Redis安装与简单使用
Redis说明
- redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库
redis特点
- Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载并使用
- redis支持五种数据类型 字符串(String) 哈希(hash) 列表(list) 集合(set) 有序集合(sorted sets)
- Redis 支持数据库备份
Redis的优势
- Redis性能极高,读的速度是110000次/s,写的速度是81000次/s
- Redis丰富的数据类型 五种
- Redis的所有操作都具有原子性
- 原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败,有着“同生共死”的感觉。及时在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程所干扰
- Redis有丰富的特性,支持publish/subscribe,通知,key过期等待特性
五种数据类型
Redis 数据类型
-- String 字符串
-- redis的string可以包含任何数据,包括图片以及序列化的对象,一个键最大能存储512MB。
-- Hash 哈希
-- redis的hash是一个String类型的key和value的映射表,hash特别适合存储对象,类比python字典。
-- List 列表
-- redis的list是简单的字符串列表,按照插入顺序排序,可以从两端进行添加,类似于双向链表,列表还可以进行阻塞。
-- Set 集合
-- redis的set是字符串类型的无序且不重复集合。集合是通过哈希表实现的,所以添加,删除,查找的时间复杂度都是O(1)。
-- Zset 有序集合
-- redis的zset和set一样,不同的是每个元素都会关联一个double类型的分数,redis正是通过对分数的排序对集合进行有序存储。
Redis在widows上安装
- 在其它版本下载,百度,网上资料多
1. 下载:
-
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 C 盘,解压后,将文件夹重新命名为 redis
-
如果下载过慢的话,可以下载国内的资源:http://download.csdn.net/detail/shzy1988/9716082
2.启用
-
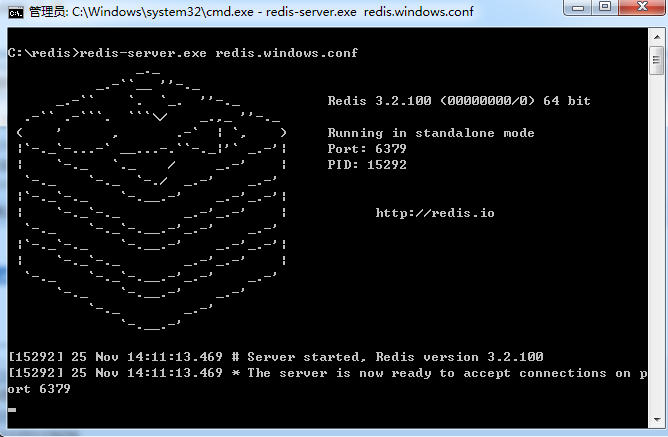
打开一个 cmd 窗口 使用cd命令切换目录到 C: edis 运行
redis-server.exe redis.windows.conf -
如果想方便的话,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。输入之后,会显示如下界面
-
这时候另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了。
-
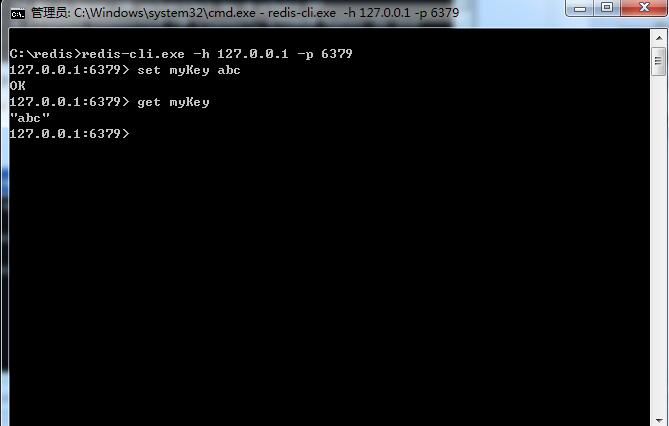
切换到redis目录下运行 redis-cli.exe -h 127.0.0.1 -p 6379 。
-
设置键值对 set myKey abc
-
取出键值对 get myKey
在Python上使用redis
一 Python连接redis
- 参数:decode_responses=True 表示存储的数据为字符串类型,默认为bytes类型
-
在Python中安装redis模块
pip3 install redis -
在Python中使用redis
- 一次性连接(一般不用这个)
import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 r = redis.Redis(host='localhost', port=6379, decode_responses=True) # host是redis主机,需要redis服务端和客户端都启动 redis默认端口是6379, decode_responses=True 表示存储的数据为字符串类型,默认为bytes类型 r.set('name', 'junxi') # key是"foo" value是"bar" 将键值对存入redis缓存 print(r['name']) print(r.get('name')) # 取出键name对应的值 print(type(r.get('name')))- 连接池(重要)
当程序创建数据源实例是,系统会一次性创建多个数据库连接,并把这些数据库连接保存在连接池中,当程序需要进行对数据库访问时,无需重新新建数据库连接,而是从连接池中取出一个空闲的数据库连接
import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True) # host是redis主机,需要redis服务端和客户端都起着 redis默认端口是6379 r = redis.Redis(connection_pool=pool) r.set('gender', 'male') # key是"gender" value是"male" 将键值对存入redis缓存 print(r.get('gender')) # gender 取出键male对应的值
二 redis基本命令String
-
set(name, value, ex=None, px=None, nx=False, xx=False)
-
在Redis中设置值,默认,不存在则创建,存在即修改
-
参数
- ex,过期时间(秒)
- px,过期时间(毫秒)
- nx,如果设置为True,则只有name不存在时,当前set操作才执行
- xx,如果设置为True,则只有name存在时,当前set操作才执行
-
实例演示:
-
ex,过期时间(秒) 这里过期时间是3秒,3秒后p,键food的值就变成None
import redis pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True) r = redis.Redis(connection_pool=pool) r.set('food', 'mutton', ex=3) # key是"food" value是"mutton" 将键值对存入redis缓存, ex=3表示3秒后food对应的value为none, print(r.get('food')) # mutton 取出键food对应的值 -
nx,如果设置为True,则只有name不存在时,当前set操作才执行 (新建)
import redis pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True) r = redis.Redis(connection_pool=pool) print(r.set('fruit', 'watermelon', nx=True)) # True--不存在 # 如果键fruit不存在,那么输出是True;如果键fruit已经存在,输出是None -
setnx(name, value)
-
设置值,只有name不存在时,执行设置操作(添加)
print(r.setnx('fruit1', 'banana')) # fruit1不存在,输出为True
-
-
setex(name, value, time)
-
参数: time ,过期时间,(数字秒或timedelalta对像
import redis import time pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True) r = redis.Redis(connection_pool=pool) r.setex("fruit2", "orange", 5) print(r.get('fruit2')) # 5秒后,取值就从orange变成None
-
-
psetex(name, time_ms, value)
-
参数: time_ms,过期时间(数字毫秒或 timedelta对象
r.psetex("fruit3", 5000, "apple") time.sleep(5) print(r.get('fruit3')) # 5000毫秒后,取值就从apple变成None
-
批量设置值 mset(*args, **kwargs)
-
批量设置值
r.mget({'k1': 'v1', 'k2': 'v2'}) r.mset(k1="v1", k2="v2") # 这里k1 和k2 不能带引号 一次设置对个键值对 print(r.mget("k1", "k2")) # 一次取出多个键对应的值 print(r.mget("k1"))
批量取值 mget(key, *args)
-
批量取值
print(r.mget('k1', 'k2')) print(r.mget(['k1', 'k2'])) print(r.mget("fruit", "fruit1", "fruit2", "k1", "k2")) # 将目前redis缓存中的键对应的值批量取出来 -
getset(name, value)
-
设置新值,并取出原来的值
print(r.getset("food", "barbecue")) # 设置的新值是barbecue 设置前的值是beef
-
-
getrange(key, start, end)
-
获取子序列(根据字节获取,非字符)
-
参数:
name, redis的key
start: 启始位置(字节)
end:结束位置(字节)
如: "骑士" , 0-3表示 骑
r.set("cn_name", "东方月初") # 汉字 print(r.getrange("cn_name", 0, 2).decode('utf8')) # 取索引号是0-2 前3位的字节 东 切片操作 (一个汉字3个字节 1个字母一个字节 每个字节8bit) print(r.getrange("cn_name", 0, -1)) # 取所有的字节 东方月初 切片操作 r.set("en_name","junxi") # 字母 print(r.getrange("en_name", 0, 2)) # 取索引号是0-2 前3位的字节 jun 切片操作 (一个汉字3个字节 1个字母一个字节 每个字节8bit) print(r.getrange("en_name", 0, -1)) # 取所有的字节 junxi 切片操作 -
setrange(name, offset, value) (没看懂)
-
修改字符串内容,从指定字符安串索引开始向后替换(如果新值比原值长,无法添加)
-
参数:
offset 字符串的索引,字节(一个汉字三个字节,索引是从0开始的)
value 值只是是1 或 0
注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo" 扩展,转换二进制表示: source = "陈思维" source = "foo" for i in source: num = ord(i) # ord方法返回单字符字符串的Unicode编码点 print bin(num).replace('b','') 特别的,如果source是汉字 "陈思维"怎么办? 答:对于utf-8,每一个汉字占 3 个字节,那么 "陈思维" 则有 9个字节 对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制 11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000
-
-
gitbit(name, offset)
-
获取name对应的值的二进制表示中的某位值(0 或者1)
print(r.getbit("foo1", 0)) # 0 foo1 对应的二进制 4个字节 32位 第0位是0还是1
-
-
bitcount(key, start=None, end=None) 了解
-
获取name对应的二进制表示中1的个数
-
参数
key redis的name
start 字节启始位置
end 字节结束位置
print(r.get("foo")) # goo1 01100111 print(r.bitcount("foo",0,1)) # 11 表示前2个字节中,1出现的个数
三 redis基本命令hash
-
-
hset(name, key, value) 增加单个 不存在则创建 hget(name, key) 获取单个 hmset(name, mapping) 批量增加 mapping为字典 hgetall(name) 获取name对应hash的所有键值 hlen(name) 获取name对应的hash中键值对的个数 hkeys(name) 获取name对应的hash中所有的key的值 hvals(name) 获取name对应的hash中所有的value的值 hexists(name, key) 检查name对应的hash是否存在当前传入的key hdel(name,*keys) 将name对应的hash中指定key的键值对删除 hscan_iter(name, match=None, count=None) 利用yield封装hscan创建生成器,实现分批去redis中获取数据 参数: match,匹配指定key,默认None 表示所有的key count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 -
单个增加--修改(单个取出)--没有就新增,有的话就修改
hset(name, key, value)
name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
name,redis的name
key,name对应的hash中的key
value,name对应的hash中的value
注:
hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hset("hash1", "k1", "v1")
r.hset("hash1", "k2", "v2")
print(r.hkeys("hash1")) # 取hash中所有的key
print(r.hget("hash1", "k1")) # 单个取hash的key对应的值
print(r.hmget("hash1", "k1", "k2")) # 多个取hash的key对应的值
r.hsetnx("hash1", "k2", "v3") # 只能新建
print(r.hget("hash1", "k2"))
四 redis的命令 list
lpush(name,values) 在name对应的list中左边添加元素 没有就新建
llen(name) 获取name对应的列表长度
lrang(name, index1, index2) 按照index切片取出name对应列表里值
lpushx(name, value) 只能添加不能新建
linsert(name, where, refvalue, value))
在name对应的列表的某一个值前或后插入一个新值
参数:
name,redis的name
where,BEFORE或AFTER
refvalue,标杆值,即:在它前后插入数据
value,要插入的数据
lset(name, index, value) 给指定索引修改值
lrem(name, value, num)
在name对应的list中删除指定的值
参数:
name,redis的name
value,要删除的值
num, num=0,删除列表中所有的指定值;
num=2,从前到后,删除2个; num=1,从前到后,删除左边第1个
num=-2,从后向前,删除2个
lindex(name, index) 在name对应的列表中根据索引获取列表元素
五 redis的发布者订阅者模式
- redis的发布和订阅模式就像是广播发消息一样,只要一发部,订阅者就能接收到
redis发布者
import redis
r = redis.Redis(host="127.0.0.1", password="", decode_responses=True)
r.publish("name", "dongfangyuechu")
订阅者
import redis
r = redis.Redis(host="127.0.0.1", password="", decode_responses=True)
# 第一步 生成一个订阅者对象
pubsub = r.pubsub()
# 第二步 订阅一个消息 实际上就是监听这个键
pubsub.subscribe("name")
# 第三步 死循环一直等待监听结果
while True:
print("working~~~")
msg = pubsub.parse_response()
print(msg)
六 管道/事物(pileline)
-
redis 默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池) 一次连接操作
-
如果想要在一次请求中指定多个命令,则可以使用管道(pipline)实现一次请求指定多个命令,并且默认情况下一次piplilne是原子性操作
-
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做
-
管道:是redis在提供单个请求中缓冲多条服务器命令基类的子类,它通过减少服务器-客户端之间反复的tcp数据库包,从而大大提高了执行批量命令的功能
import redis import time pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) # 默认的情况下,管道里执行的命令可以保证执行的原子性,执行pipe = r.pipeline(transaction=False)可以禁用这一特性。 # pipe = r.pipeline(transaction=True) pipe = r.pipeline() # 创建一个管道 pipe.set('name', 'jack') pipe.set('role', 'sb') pipe.sadd('faz', 'baz') # 新增 pipe.incr('num') # 如果num不存在则vaule为1,如果存在,则value自增1 pipe.execute() print(r.get("name")) print(r.get("role")) print(r.get("num"))管道的命令可以写在一起
pipe.set('hello', 'redis').sadd('faz', 'baz').incr('num').execute() print(r.get("name")) print(r.get("role")) print(r.get("num"))