一、 RCNN系列的发展
1.1 R-CNN
根据以往进行目标检测的方法,在深度学习应用于目标检测时,同样首先尝试使用滑动窗口的想法,先对图片进行选取2000个候选区域,分别对这些区域进行提取特征以用来识别分割。
1.1.1 rcnn具体的步骤是:
步骤一:在imagenet分类比赛上寻找一个cnn模型,使用它用于分类的预训练权重参数;对于这个模型修改最后的分类层,分为21类,去掉最后一个全连接层,因为所用的测试集为20类,且还有一类背景类。
步骤二:根据选择性搜索来对输入的图像进行选取2000个候选区域框;
然后修改候选区域框的大小,以适应cnn的输入,然后用cnn来提取出每个候选区域的feature map。
步骤三:训练svm分类器,这个svm分类器是对于特定的某一类进行区分,是专门用来对特定敏感区域进行分类,每一个类别对应于一个SVM分类器
步骤四:使用回归器精细修正每个候选框的位置,对于每一个类,需要训练一个回归模型去判定这个框框的是否完美。
对应步骤的图片结构如下图1:

这里有几点需要补充的是:
1. 采用预训练和fine-tune来解决了标签数据不多的问题,在imagenet上训练过大规模图片集合的网络已经对图片的基本信息都有了很明确的收集,采用预训练模型后再在voc训练集上进行fine-tune会达到很好的效果。
2. 选择候选区域的几种方法:这里采用的是slective search
3. 训练过程:
在得到候选区域后,首先将候选区域跟gt(真实标注的框)来进行比较,如果iou>0.5(iou是图像分割里面对于判定两个不同区域的相似度所采用的一个标准)把这个候选区域置为正样本,否则就是负样本。Iou的取值相当重要,会对结果影响较大。
训练时候采用SGD方法来调整框的位置。
1.1.2 RCNN的缺点:
1. 训练过程太慢,需要对每一个候选区域都输入到cnn中再进行提取特征,极大的浪费了时间和精力。
2. 步骤相对较多,需要fine-tune预训练模型、训练SVM分类器、回归器进行精细的调整。
3. 占用空间大,提取出的特征以及分类器都需要占用额外的空间
4. 没有对资源进行重复利用,在使用SVM分类和对框进行回归操作的时候cnn模型的参数并没有同步修改。
1.2 Fast rcnn
针对RCNN的需要对每一个候选区域进行cnn操作这一繁琐操作进行改进,从而的到了fast-rcnn算法,
1.2.1 fast-rcnn的步骤如下:
步骤一:同样是寻找一个在imagenet上训练过的预训练cnn模型
步骤二:与rcnn一样,通过selective search在图片中提取2000个候选区域
步骤三:将一整个图片都输入cnn模型中,提取到图片的整体特征(这是相对于rcnn最大的改进的地方)
步骤四:把候选区域映射到上一步cnn模型提取到的feature map里
步骤五:采用rol pooling层对每个候选区域的特征进行上采样,从而得到固定大小的feature map,以便输入模型中
步骤六:根据softmax loss和smooth l1 loss对候选区域的特征进行分类和回归调整的过程,回归操作是对于框调整所使用的bou b reg来训练。
相比rcnn的不同处:
在得到每个候选区域的feature map后,通过rolpooling 层来进行上采样操作对尺寸进行调整以便时输入模型;
最后使用的loss函数为multi-task loss,然后是把回归操作加入到cnn权重更新的过程中去。
1.2.2优点有以下几点:
1. fast-rcnn在训练的时候,把整张图片送入cnn网络进行提取特征,不需要像rcnn那样对每一个候选区域进行输入cnn,从而在cnn的利用上提高了很大的效率。
2. 训练速度相应提升,不需要svm分类器对提取后的特征进行存储数据,把图片的特征和候选区域直接送入loss,不需要对硬盘进行读写的操作。
3. 对网络的利用效率,用于分类和回归调整的功能都用cnn网络来实现,不需要额外的分类器和回归器。
但是fast-rcnn仍然有其缺陷,对于生成候选区域仍然不够快速,所以faster-rcnn针对这一点进行改进,提出使用rpn网络来生成候选区域。同时提出的rpn网络可以与目标检测同时共享一个cnn的网络参数,减少参数的数量。
二 Faster rcnn的基本原理
2.1 faster rcnn的原理及结构
前面介绍了rcnn以及fast-rcnn,基础知识已经做好铺垫,接下来将介绍rcnn系列的最后一种算法faster-rcnn的详细内容。Faster-rcnn的主要原理如下:
Faster-rcnn是Ross B.Girshick在2016年在r-cnn和Fast-rcnn的基础上提出来的,最大的亮点之处是faster-rcnn把获取feature map,候选区域选取,回归和分类等操作全部融合在一个深层网络当中,效率较前两种提升了很多。
Faster-rcnn的基本结构如下图:
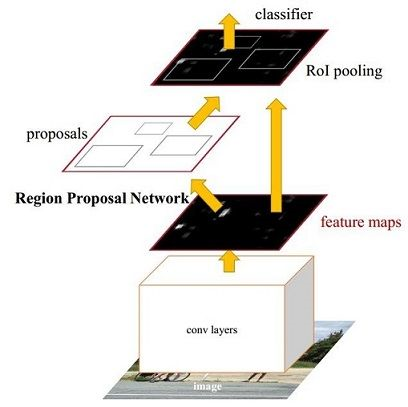
Faster-rcnn在结构上主要由一下几部分构成:
1. 卷积层,这部分卷积层就是普通的由imagenet比赛上用于分类的预训练模型所用的卷积层,它的主要功能是用来提取整张图片的feature map,卷积层结构也是卷积+激活函数+池化操作组成的。
2. RPN网络,这是整个faster-rcnn的核心部分,改善了前两种方法用选择搜索来获取候选区域的方法,这种方法不仅快速而且更加高效地利用了cnn网络。在生成候选区域的时候会生成anchors,然后内部通过判别函数判断anchors属于前景还是后景,然后通过边框回归来进行第一次调整anchors获取准确的候选区域。
3. Roi pooling,这一层的添加主要是为了解决最后输入全连接层的feature map的尺寸大小不同的问题,通过上采样来获取固定大小。
4. 分类和回归,最后通过两个分类层和回归层来分别判断物体属于哪个类别以及精细调整候选区域的位置,以获取最终目标检测的结果。