urllib库是 python内置的一个库,用于 HTTP的访问
其中包括4个模块
urllib.request 基本 HTTP请求模块,类似于浏览器上输入网址 url,获取网页源代码
urllib.error 异常处理模块,当获取网页数据错误时,可以使程序不退出,进行重试等操作
urllib.parse 工具模块,可以对网址 url进行拆分、合并、拼接等
urllib.robotparser 主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬的
1、request 模块

1.1 urlopen() urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
data 必须是字节流形式,也就是 byte类型的数据 传递了 data数据,那么请求就变成了 pose请求,而不是 get请求
get请求和 pose请求 get请求 会把数据都写在 url上,暴露
pose请求 例如,账号密码,就可以写成一个字典形式的 ['key':'value']
timeout 获取时间,例如,设置 timeout=1 即等待 1s的获取网页时间,如果超时,则会报错
import urllib.request response = urllib.request.urlopen('https://www.python.org') print(type(response))
导入模块,使用 urlopen获取到对象 response,得到结果,返回的值是一个,类,其中包括 read() getheaders() gethead(Server) 等方法

import urllib.request reponse = urllib.request.urlopen('http://www.baidu.com') print(reponse.read().decode('utf-8'))
可以利用 read()方法读取网页源码
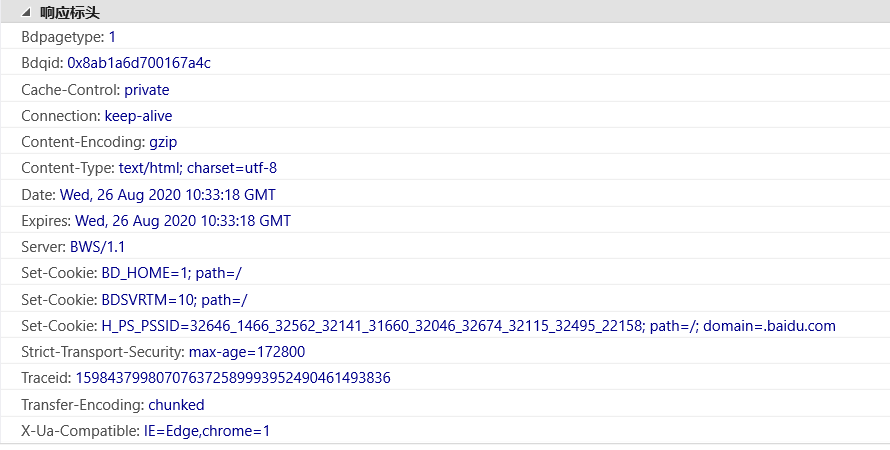
import urllib.request response = urllib.request.urlopen('http://www.baidu.com') print(response.status) # 状态码 判断请求是否成功 print(response.getheaders()) # 响应头 得到的一个元组组成的列表 print(response.getheader('Server')) #得到特定的响应头 print(response.read().decode('utf-8')) #获取响应体的内容,字节流的数据,需要转成utf-8格式
也可以利用 status读取网页状态,200表示请求成功, 404表示没有找到网页

利用 getheaders()读取相应标头,也可以具体读取某一单个的值
1.2 Request类 对象
还是用 urlopen发起请求,但是普通的 urlopen请求的参数内容有限,无法包含所有内容,例如,如果想要包含 headers信息,就需要用到对象 Request类构建请求
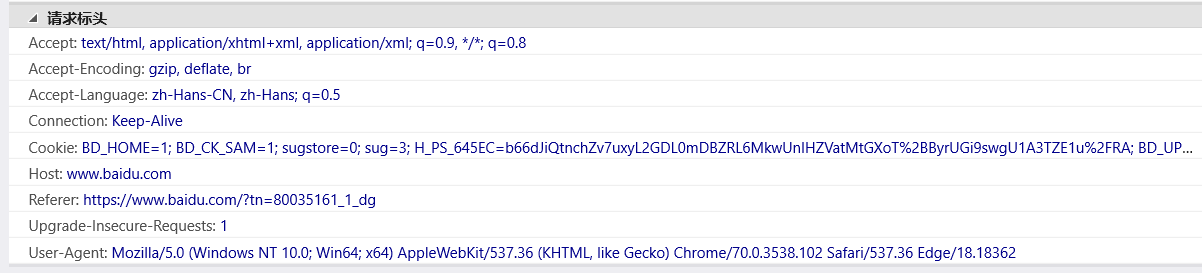
例如,User-Agent 就是浏览器数据,可以模拟指定浏览器访问网址 url
import urllib.request url ='http://baidu.com' headers ={ 'User-Agent' :'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 70.0.3538.102Safari / 537.36Edge / 18.18362' } req =urllib.request.Request(url =url,headers=headers) response =urllib.request.urlopen(req) print(response.read().decode('utf-8'))
当遇到反爬虫的时候,有可能是网址设定不准python访问,可以修改 User-Agent 模拟浏览器访问
2、error 异常处理
如果因为网络问题或者其他问题,获取网址失败,那么程序就会报错或者停止,这时候如果有一个异常处理使得获取网址信息代码重新执行就可以避免整个程序停止
异常处理分为两类:URLError 和 HTTPError 其中 HTTPError是URLError的一个子类
2.1 URLError
from urllib import request,error try: response = request.urlopen('http://cuiqingcai.com/index.htm') except error.URLError as e: print(e.reason)
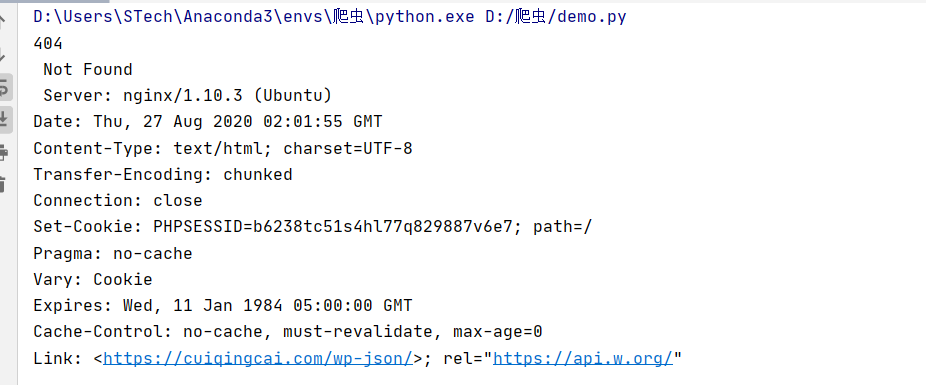
其中,网址 'http://cuiqingcai.com/index.htm' 为一个 404网址,可以得到运行结果

2.2 HTTPError
from urllib import request,error try: response = request.urlopen('https://cuiqingcai.com/index.htm') except error.HTTPError as e: print(e.code,' ',e.reason,' ',e.headers)
也可以用 HTTPError进行异常处理,分为三个方法,code:返回状态码404表示不存在,500表示服务器错误
reason:返回错误原因
headers:返回请求头
因此,一种常见的异常处理方法,可以先检查是否为 HTTPError,再检查是否为 URLError,如果都不是,则说明获取网址正常
from urllib import request,error try: response = request.urlopen('https://www.baidu.com',timeout=0.01) except error.HTTPError as e: print("HTTPError") print(e.code,' ',e.reason,' ',e.headers) except error.URLError as e: print("URLError") print(e.reason) else: print('Request successfully')
例如,正确的百度网址,设置获取时间为 0.01s,报错,显示 URLError,超时获取
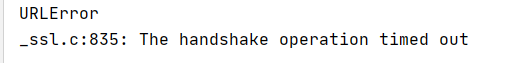
可如果去除 timeout=0.01,自然获取网址,则无异常,显示 Request successfully

3、parse 拆分、拼凑
3.1 urlparse 拆分
import urllib.parse result = urllib.parse.urlparse("https://edu.hellobi.com/course/157/play/lesson/2580") print(result)
将网址进行拆分,输出结果

3.2 urlunparse 拼凑
from urllib.parse import urlunparse data = ['http','www.baidu.com','index.html','user','a=6','comment'] print(urlunparse(data))
可以将字典形式的数据进行拼接成一个网址

3.3 urlencode 源网址上添加新内容
也可以再原网址上添加,获得一个新网址
from urllib.parse import urlencode params = { 'name':'germey', 'age': 22 } base_url = 'http://www.baidu.com?' url = base_url + urlencode(params) print(url)
得到结果

以上就是 urllib 获取网址的方法