如何搭建配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何配置hadoop2.9.0 HA 请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA》
安装hadoop的服务器:
192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 slave2 192.168.0.123 slave3
公共运行及环境准备工作:
修改主机名
将搭建1个master,3个slave的hadoop集群方案:首先修改主机名vi /etc/hostname,在master上修改为master,其中一个slave上修改为slave1,其他依次推。
192.168.0.120

192.168.0.121

192.168.0.122

192.168.0.123

关闭防火墙
依次在master,slave1,slave2,slave3上执行以下命令:
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --state
配置hosts
在每台主机上修改host文件:vi /etc/hosts
192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 slave2 192.168.0.123 slave3
以master节点配置后的结果为:
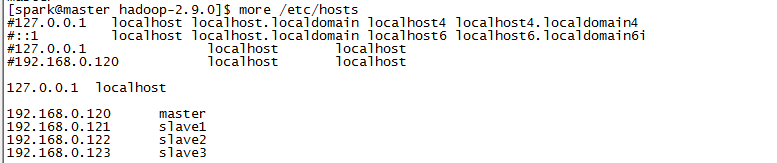
配置之后ping一下用户名看是否生效
ping master ping slave1 ping slave2 ping slave3
ssh配置
安装Openssh server
备注:默认centos上都是已经安装好了ssh,因此不需要安装。
1)确认centos是否安装ssh命令:
yum install openssh-server -y
2)在所有机器上都生成私钥和公钥
ssh-keygen -t rsa #一路回车
依次在master,slave1,slave2,slave3上执行:

3)需要让机器间都能相互访问,就把每个机子上的id_rsa.pub发给master节点,传输公钥可以用scp来传输。
slave1执行:
scp ~/.ssh/id_rsa.pub spark@master:~/.ssh/id_rsa.pub.slave1
slave2执行:
scp ~/.ssh/id_rsa.pub spark@master:~/.ssh/id_rsa.pub.slave2
slave3执行:
scp ~/.ssh/id_rsa.pub spark@master:~/.ssh/id_rsa.pub.slave3
以slave1上执行过程截图:
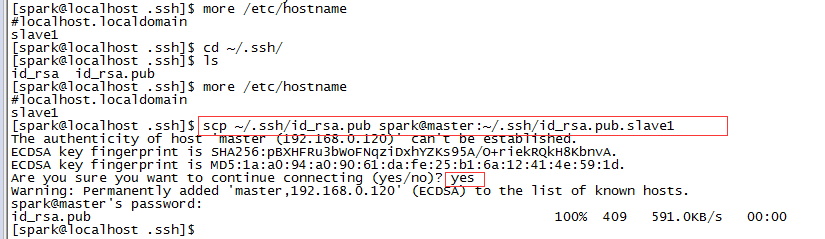
执行后master显示结果:

4)在master上,将所有公钥加到用于认证的公钥文件authorized_keys中
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
注意:上边是id_rsa.pub*,后边带了一个“*”。

5)将master上生成的公钥文件authorized_keys分发给每台slave
scp ~/.ssh/authorized_keys spark@slave1:~/.ssh/ scp ~/.ssh/authorized_keys spark@slave2:~/.ssh/ scp ~/.ssh/authorized_keys spark@slave3:~/.ssh/
执行过程截图:

6)在每台机子上验证SSH无密码通信
ssh master ssh slave1 ssh slave2 ssh slave3
如果登陆测试不成功,则可能需要修改文件authorized_keys的权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能 )
chmod 600 ~/.ssh/authorized_keys
安装java8
1)查看是否系统已经安装了jdk
[spark@localhost ~]$ rpm -qa | grep Java [spark@localhost ~]$
我这里发现未安装过jdk,如果你发现有可以参考《使用CentOS7卸载自带jdk安装自己的JDK1.8》进行卸载。
2)从官网下载最新版 Java
Spark官方说明 Java 只要是6以上的版本都可以,我下的是jdk-8u171-linux-x64.tar.gz
3)上传jdk到centos下的/opt目录
安装“在线导入安装包”插件:
yum -y install lrzsz
备注:目的为了上传文件使用。

安装插件完成之后输入 rz 命令然后按回车,就会弹出一个窗口,然后你就在这个窗口找到你下载好的jdk,
备注:使用 rz 命令的好处就是你在哪里输入rz导入的安装包他就在哪里,不会跑到根目录下
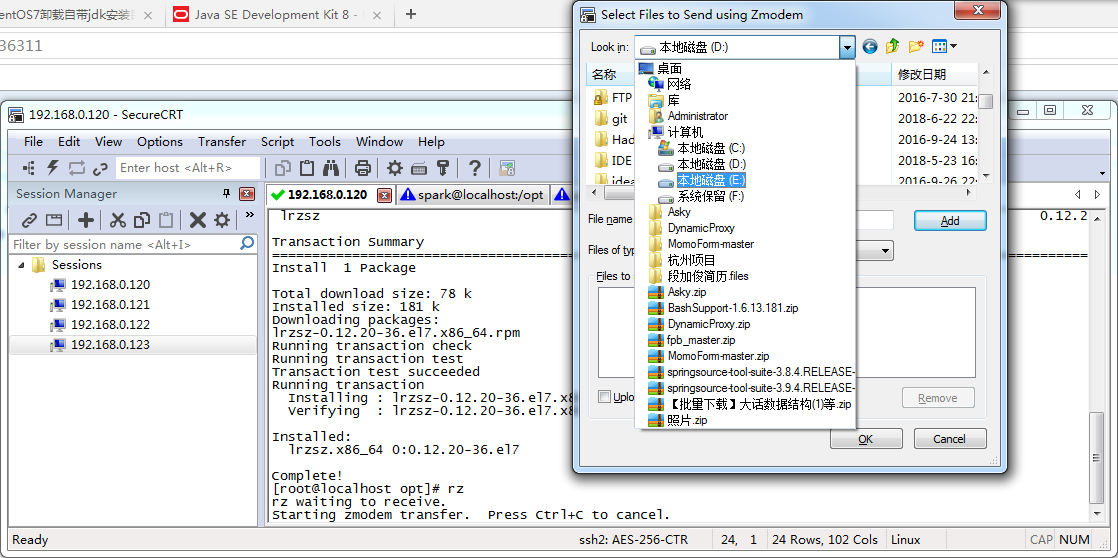
关于该插件的使用和安装,请参考《https://blog.csdn.net/hui_2016/article/details/69941850》
4)执行解压
tar -zxvf jdk-8u171-linux-x64.tar.gz
5)配置jdk环境变量
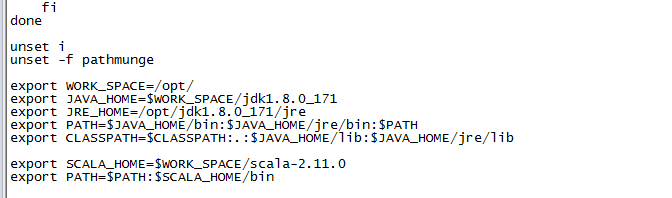
修改环境变量vi /etc/profile,添加下列内容,注意将home路径替换成你的:
export WORK_SPACE=/opt/ export JAVA_HOME=$WORK_SPACE/jdk1.8.0_171 export JRE_HOME=/opt/jdk1.8.0_171/jre export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
然后使环境变量生效,并验证 Java 是否安装成功
$ source /etc/profile #生效环境变量 $ java -version #如果打印出如下版本信息,则说明安装成功 java version "1.8.0_171" Java(TM) SE Runtime Environment (build 1.8.0_171-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode) [root@localhost opt]#
依次把master,slave1,slave2,slave3安装jdk8。
安装scala
Spark官方要求 Scala 版本为 2.10.x,注意不要下错版本,我这里下了 2.11.0,官方下载地址。
依据参考:http://spark.apache.org/downloads.html

同样解压到/opt下:
tar -zxvf scala-2.11.0.tgz
再次修改环境变量 vi /etc/profile,添加以下内容:
export SCALA_HOME=$WORK_SPACE/scala-2.11.0 export PATH=$PATH:$SCALA_HOME/bin
同样的方法使环境变量生效,并验证 scala 是否安装成功
$ source /etc/profile #生效环境变量 $ scala -version #如果打印出如下版本信息,则说明安装成功 Scala code runner version 2.11.0 -- Copyright 2002-2013, LAMP/EPFL
安装hadoop2.9.0 YARN
下载解压
从官网下载 hadoop2.9.0 版本。
同样在/opt/中解压
tar -zxvf hadoop-2.9.0.tar.gz
配置 Hadoop
cd /opt/hadoop-2.9.0/etc/hadoop进入hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml

1)在hadoop-env.sh中配置JAVA_HOME
# The java implementation to use. export JAVA_HOME=/opt/jdk1.8.0_171
2)在yarn-env.sh中配置JAVA_HOME
# The java implementation to use. export JAVA_HOME=/opt/jdk1.8.0_171
3)在slaves中配置slave节点的ip或者host
#localhost
slave1
slave2
slave3
4)修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000/</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop-2.9.0/tmp</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> </configuration>
备注:不需要在/opt/hadoop-2.9.0下建立tmp文件夹,同时分配权限777
5)修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop-2.9.0/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop-2.9.0/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
备注:不需要在/opt/hadoop-2.9.0下新建dfs文件夹,再在dfs下新建name,data文件夹,并给他们分配777权限。
1)dfs.namenode.name.dir----HDFS namenode数据镜像目录
2)dfs.datanode.data.dir---HDFS datanode数据镜像存储路径,可以配置多个不同的分区和磁盘中,使用,号分隔
3)还可以配置:dfs.namenode.http-address---HDFS Web查看主机和端口号
可以参考下边这个hdfs-site.xml配置项
vim hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/hdfs/name</value> <!-- HDFS namenode数据镜像目录 --> <description> </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/hdfs/data</value> <!-- HDFS datanode数据镜像存储路径,可以配置多个不同的分区和磁盘中,使用,号分隔 --> <description> </description> </property> <property> <name>dfs.namenode.http-address</name> <value>apollo.hadoop.com:50070</value> <!-- HDFS Web查看主机和端口号 --> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>artemis.hadoop.com:50090</value> <!-- 辅控HDFS Web查看主机和端口 --> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.replication</name> <value>3</value> <!-- HDFS数据保存份数,通常是3 --> </property> <property> <name>dfs.datanode.du.reserved</name> <value>1073741824</value> <!-- datanode写磁盘会预留1G空间给其它程序使用,而非写满,单位 bytes --> </property> <property> <name>dfs.block.size</name> <value>134217728</value> <!-- HDFS数据块大小,当前设置为128M/Blocka --> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> <!-- HDFS关闭文件权限 --> </property> </configuration>
来自于《https://blog.csdn.net/jssg_tzw/article/details/70314184》
6)修改mapred-site.xml
需要从mapred-site.xml.template拷贝mapred-site.xml:
[root@localhost hadoop]# scp mapred-site.xml.template mapred-site.xml
[root@localhost hadoop]# vi mapred-site.xml
配置为:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>master:50030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>mapred.job.tracker</name> <value>http://master:9001</value> </property> </configuration>
7)修改yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>512修改为 2048,否则会抛出内存不足问题导致nodemanager启动不了</value> </property> </configuration>
将配置好的hadoop-2.9.0文件夹分发给所有slaves
scp -r /opt/hadoop-2.9.0 spark@slave1:/opt/ scp -r /opt/hadoop-2.9.0 spark@slave2:/opt/ scp -r /opt/hadoop-2.9.0 spark@slave3:/opt/
注意:此时默认master,slave1,slave2,slave3上是没有/opt/hadoop-2.9.0,因此直接拷贝可能会出现无权限操作 。
解决方案,分别在master,slave1,slave2,slave3的/opt下创建hadoop-2.9.0,并分配777权限。
[root@localhost opt]# mkdir hadoop-2.9.0
[root@localhost opt]# chmod 777 hadoop-2.9.0
[root@localhost opt]#
之后,再次操作拷贝就有权限操作了。
启动 Hadoop
在 master 上执行以下操作,就可以启动 hadoop 了。
cd /opt/hadoop-2.9.0 #进入hadoop目录
bin/hadoop namenode -format #格式化namenode
sbin/start-all.sh #启动dfs,yarn
执行format成功的提示信息如下:
[spark@master hadoop-2.9.0]$ bin/hadoop namenode -format #格式化namenode DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 18/06/30 08:28:40 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/192.168.0.120 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.9.0 STARTUP_MSG: classpath = /opt/hadoop-2.9.0/etc/hadoop:/opt/hadoop-2.9.0/share/hadoop/common/lib/nimbus-jose-jwt-3.9.jar:/opt/hadoop-2.9.0。。。 TARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50; compiled by 'arsuresh' on 2017-11-13T23:15Z STARTUP_MSG: java = 1.8.0_171 ************************************************************/ 18/06/30 08:28:40 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 18/06/30 08:28:40 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-5003db37-c0ea-4bac-a789-bd88cae43202 18/06/30 08:28:40 INFO namenode.FSEditLog: Edit logging is async:true 18/06/30 08:28:40 INFO namenode.FSNamesystem: KeyProvider: null 18/06/30 08:28:40 INFO namenode.FSNamesystem: fsLock is fair: true 18/06/30 08:28:40 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 18/06/30 08:28:40 INFO namenode.FSNamesystem: fsOwner = spark (auth:SIMPLE) 18/06/30 08:28:40 INFO namenode.FSNamesystem: supergroup = supergroup 18/06/30 08:28:40 INFO namenode.FSNamesystem: isPermissionEnabled = true 18/06/30 08:28:40 INFO namenode.FSNamesystem: HA Enabled: false 18/06/30 08:28:40 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 18/06/30 08:28:40 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000 18/06/30 08:28:40 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 18/06/30 08:28:40 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 18/06/30 08:28:40 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Jun 30 08:28:40 18/06/30 08:28:40 INFO util.GSet: Computing capacity for map BlocksMap 18/06/30 08:28:40 INFO util.GSet: VM type = 64-bit 18/06/30 08:28:40 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 18/06/30 08:28:40 INFO util.GSet: capacity = 2^21 = 2097152 entries 18/06/30 08:28:41 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 18/06/30 08:28:41 WARN conf.Configuration: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS 18/06/30 08:28:41 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 18/06/30 08:28:41 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0 18/06/30 08:28:41 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000 18/06/30 08:28:41 INFO blockmanagement.BlockManager: defaultReplication = 3 18/06/30 08:28:41 INFO blockmanagement.BlockManager: maxReplication = 512 18/06/30 08:28:41 INFO blockmanagement.BlockManager: minReplication = 1 18/06/30 08:28:41 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 18/06/30 08:28:41 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 18/06/30 08:28:41 INFO blockmanagement.BlockManager: encryptDataTransfer = false 18/06/30 08:28:41 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 18/06/30 08:28:41 INFO namenode.FSNamesystem: Append Enabled: true 18/06/30 08:28:41 INFO util.GSet: Computing capacity for map INodeMap 18/06/30 08:28:41 INFO util.GSet: VM type = 64-bit 18/06/30 08:28:41 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 18/06/30 08:28:41 INFO util.GSet: capacity = 2^20 = 1048576 entries 18/06/30 08:28:41 INFO namenode.FSDirectory: ACLs enabled? false 18/06/30 08:28:41 INFO namenode.FSDirectory: XAttrs enabled? true 18/06/30 08:28:41 INFO namenode.NameNode: Caching file names occurring more than 10 times 18/06/30 08:28:41 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false 18/06/30 08:28:41 INFO util.GSet: Computing capacity for map cachedBlocks 18/06/30 08:28:41 INFO util.GSet: VM type = 64-bit 18/06/30 08:28:41 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 18/06/30 08:28:41 INFO util.GSet: capacity = 2^18 = 262144 entries 18/06/30 08:28:41 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 18/06/30 08:28:41 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 18/06/30 08:28:41 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 18/06/30 08:28:41 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 18/06/30 08:28:41 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 18/06/30 08:28:41 INFO util.GSet: Computing capacity for map NameNodeRetryCache 18/06/30 08:28:41 INFO util.GSet: VM type = 64-bit 18/06/30 08:28:41 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 18/06/30 08:28:41 INFO util.GSet: capacity = 2^15 = 32768 entries 18/06/30 08:28:41 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1045060460-192.168.0.120-1530318521716 18/06/30 08:28:41 INFO common.Storage: Storage directory /opt/hadoop-2.9.0/dfs/name has been successfully formatted. 18/06/30 08:28:41 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/hadoop-2.9.0/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 18/06/30 08:28:41 INFO namenode.FSImageFormatProtobuf: Image file /opt/hadoop-2.9.0/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 322 bytes saved in 0 seconds. 18/06/30 08:28:41 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 18/06/30 08:28:41 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.0.120 ************************************************************/
备注:如果出现上边红色部分信息系则说明格式化成功。
启动执行过程:
[spark@master hadoop-2.9.0]$ sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-namenode-master.out
slave3: starting datanode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-datanode-slave3.out
slave2: starting datanode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-datanode-slave2.out
slave1: starting datanode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-datanode-slave1.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-resourcemanager-master.out
slave2: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave2.out
slave1: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave1.out
slave3: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave3.out
[spark@master hadoop-2.9.0]$ jps
1361 NameNode
1553 SecondaryNameNode
1700 ResourceManager
1958 Jps
[spark@master hadoop-2.9.0]$ sbin/start-yarn.sh #启动yarn
starting yarn daemons
resourcemanager running as process 1700. Stop it first.
slave3: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave3.out
slave2: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave2.out
slave1: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave1.out
[spark@master hadoop-2.9.0]$
[spark@master hadoop-2.9.0]$ jps
1361 NameNode
1553 SecondaryNameNode
1700 ResourceManager
2346 Jps
启动过程发现问题:
1)启动问题:slave1,slave2,slave3都是只启动了DataNode,而DataManager并没有启动:解决方案参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(七)针对hadoop2.9.0启动DataManager失败问题》
2)启动问题:启动之后发现slave上正常启动了DataNode,DataManager,但是过了几秒后发现DataNode被关闭:解决方案参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(五)针对hadoop2.9.0启动之后发现slave上正常启动了DataNode,DataManager,但是过了几秒后发现DataNode被关闭》
3)启动问题:执行start-all.sh出现异常:failed to launch: nice -n 0 /bin/spark-class org.apache.spark.deploy.worker.Worker:解决方案参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(四)针对hadoop2.9.0启动执行start-all.sh出现异常:failed to launch: nice -n 0 /bin/spark-class org.apache.spark.deploy.worker.Worker》
正常启动hadoop后,master正常启动包含的进程有:
[spark@master hadoop2.9.0]$ jps 5938 ResourceManager 5780 SecondaryNameNode 6775 Jps 5579 NameNode [spark@master hadoop2.9.0]$
正常启动hadoop后,slaves上正常启动包含的进程有:
[spark@slave1 hadoop-2.9.0]$ jps 3202 NodeManager 3784 Jps 3086 DataNode [spark@slave1 hadoop-2.9.0]$
另外启动master的JobHistoryServer进程方式:
[spark@master hadoop-2.9.0]$ /opt/hadoop-2.9.0/sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/hadoop-2.9.0/logs/mapred-spark-historyserver-master.out [spark@master hadoop-2.9.0]$ jps 2945 SecondaryNameNode 2216 QuorumPeerMain 3386 JobHistoryServer 3099 ResourceManager 3454 Jps
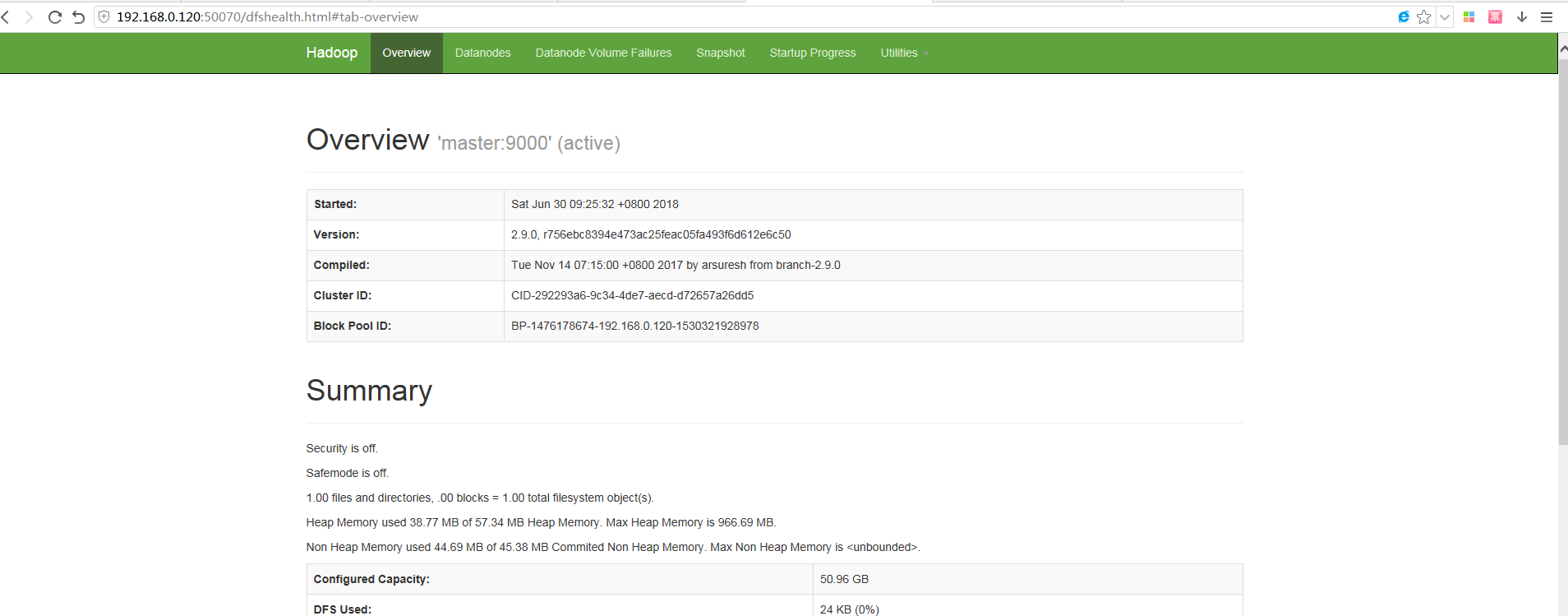
验证是否安装成功访问地址:http://192.168.0.120:8088/,是否可以访问。

访问:http://192.168.0.120:50070/ 备注:该端口50070配置项是可以设置在hdfs-site.xml