一、网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。简单来讲,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序。web爬虫是一种机器人,它们会递归地对各种信息性的web站点进行遍历,获取第一个web页面,然后获取那个页面指向的所有的web页面,依次类推。因特网搜索引擎使用爬虫在web上游荡,并把他们碰到的文档全部拉回来。然后对这些文档进行处理,形成一个可搜索的数据库。简单来说,网络爬虫就是搜索引擎访问你的网站进而收录你的网站的一种内容采集工具。
例如:百度的网络爬虫就叫做BaiduSpider。

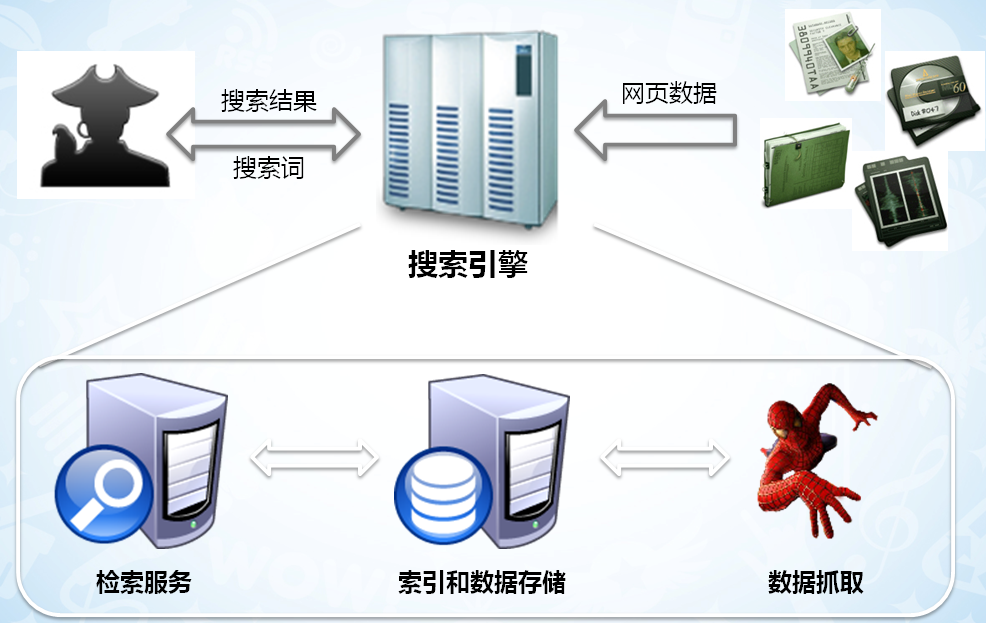
二、网络爬虫基本原理
网络 < --- > 爬虫 < --- > 网页内容库 < --- > 索引程序 < --- > 索引库 < --- > 搜索引擎 < --- > 用户
三、爬虫程序需要注意的地方
1、链接提取以及相对链接的标准化
- 爬虫在web上移动的时候会不停的对HTML页面进行解析,它要对所解析的每个页面上的URL链
接进行分析,并将这些链接添加到需要爬行的页面列表中去
2、 避免环路的出现
web爬虫在web上爬行时,要特别小心不要陷入循环之中,至少有以下三个原因,环路对爬虫来说是有害的。
- 他们会使爬虫可能陷入可能会将其困住的循环之中。爬虫不停的兜圈子,把所有时间都耗费在不停获取相同的页面上。
- 爬虫不断获取相同的页面的同时,服务器段也在遭受着打击,它可能会被击垮,阻止所有真实用户访问这个站点。
- 爬虫本身变的毫无用处,返回数百份完全相同的页面的因特网搜索引擎就是这样的例子。
同时,联系上一个问题,由于URL“别名”的存在,即使使用了正确的数据结构,有时候也很难分辨出以前是否访问过这
个页面,如果两个URL看起来不一样,但实际指向的是同一资源,就称为互为“别名”。
3、标记为不爬取
4、避免环路与循环方案
5、规范化URL
6、广度优先的爬行
- 以广度优先的方式去访问就可以将环路的影响最小化。
7、节流
- 限制一段时间内爬虫可以从一个web站点获取的页面数量,也可以通过节流来限制重复页面总数和对服务器访问的总数。
8、限制URL的大小
- 如果环路使URL长度增加,长度限制就会最终终止这个环路
9、URL黑名单
10、人工监视
四、搜索引擎优化(SEO)
1、内部优化
- META标签优化:例如:TITLE,KEYWORDS,DESCRIPTION等的优化
- 内部链接的优化,包括相关性链接(Tag标签),锚文本链接,各导航链接,及图片链接
- 语义化书写HTML代码,符合W3C标准
- 网站内容更新:每天保持站内的更新(主要是文章的更新等)
2、外部优化
- 外部链接类别:博客、论坛、B2B、新闻、分类信息、贴吧、知道、百科、相关信息网等尽量保持链接的多样性
- 外链运营:每天添加一定数量的外部链接,使关键词排名稳定提升。
- 外链选择:与一些和你网站相关性比较高,整体质量比较好的网站交换友情链接,巩固稳定关键词排名
- 提升网站速度等
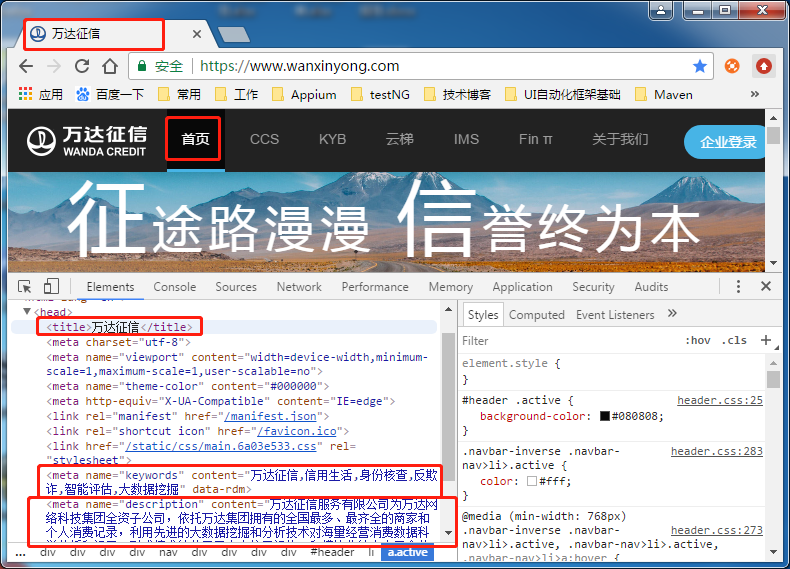
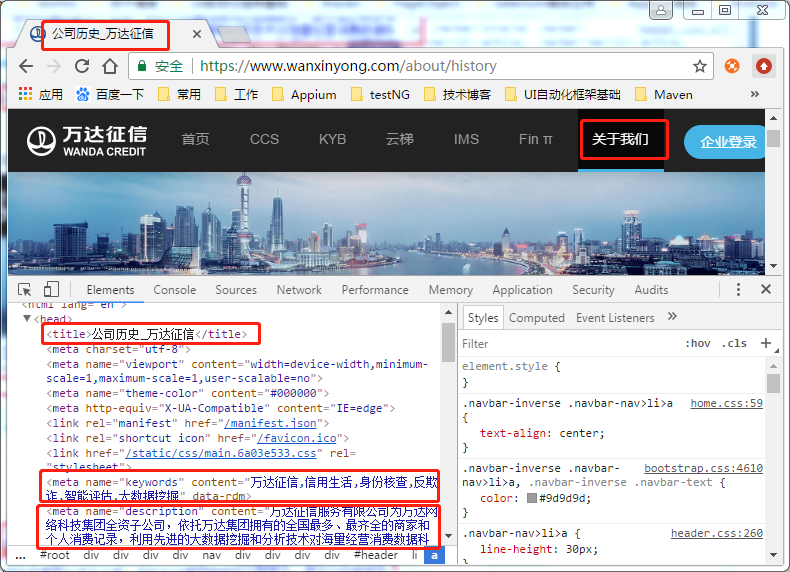
以内部优化中META标签优化举例(下图为万达征信官网),下图为不同页面的title、keywords、description都不一样,
易于爬虫,提升网站的访问量。