本篇涉及的内容主要有小型常用的经典数据集的加载步骤,tensorflow提供了如下接口:keras.datasets、tf.data.Dataset.from_tensor_slices(shuffle、map、batch、repeat),涉及的数据集如下:boston housing、mnist/fashion mnist、cifar10/100、imdb
1.keras.datasets
通过该接口可以直接下载指定数据集。boston housing提供了和房价有关的一些因子(面积、居民来源等),mnist提供了手写数字的图片和对应label,fashion mnist提供了10种衣服的灰度图和对应label,cifar10/100是用来进行简单图像识别的数据集,分别包含10类物品和100类物品,imdb是一个类似于淘宝好评的数据集,即通过评语及其标注(好评或差评),来实现一个好评或差评的分类器。
注:通过该接口得到的数据集格式为numpy格式。
2.tf.data.Dataset.from_tensor_slices()
该方法可以用来进行数据的迭代,过程中可以直接将numpy格式转化为tensor格式,然后通过调用next(iter())方法实现迭代,使用示例如下:
# 加载数据集 (x,y),(x_test,y_test) = keras.datasets.mnist.load_data() # 转化为tensor并实现迭代 db = tf.data.Dataset.from_tensor_slices(x_test) # 打印迭代数据的shape print(next(iter(db)).shape) # 将img和label封装为同一次迭代 db = tf.data.Dataset.from_tensor_slices((x_test,y_test)) print(next(iter(db))[0].shape) print(next(iter(db))[1].shape)
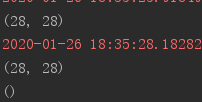
3.shuffle
通过shuffle函数可以将数据集打散,从而提高模型的泛化能力,使用方法:db.shuffle(10000),参数设置范围,通常值设置比较大
4.map
# deep learning一般使用float32,而numpy格式多为float64,所以需要转化 def preprocess(x,y): x = tf.cast(x,dtype=tf.float32)/255 y = tf.cast(y,dtype=tf.int32) y = tf.one_hot(y,depth=10) return x,y db2 = db.map(preprocess) res = next(iter(db2)) print(res[0].shape,res[1].shape)

5.batch
db3 = db2.batch(32) res = next(iter(db3)) print(res[0].shape,res[1].shape)

6.StopIteration
因为迭代多次后会到达数据集的末尾,如果不进行异常处理则会报StopIteration异常,如下处理方式就是错误的:
db_iter = iter(db3) while True: next(db_iter)
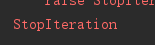
只要加上异常处理语句对db_iter重新赋值即可