我们知道机器学习中模型的参数是通过不断减小损失函数loss来进行优化的,这就与线性回归的含义不谋而合,只不过线性回归是通过最小二乘法来最小化误差(的平方)并且寻找最优函数。一想到平方,又不难联系到平方损失函数,平方损失函数相比最小二乘法不过就是多了个 1/n ,即求平均的系数。
假设模型预测值为yi,模型实际输出为 ai,则有:
平方损失函数公式:loss = (1/N)Σ(yi - ai)2
最小二乘法公式:e = Σ(yi - ai)2 (由于回归方程的随机误差期望为0且无法确定,此处忽略)
可以看出两者并没有本质区别,都可以理解成通过最小化误差的平方和来优化模型参数。
下面使用tensorflow模拟一下损失函数的优化过程,完整代码如下:
1 import tensorflow as tf 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from mpl_toolkits.mplot3d import Axes3D 5 6 batch_size = 10 7 seed = 23445 8 9 # 通过随机数种子生成模型的输入输出 10 random = np.random.RandomState(seed) 11 input_x = random.rand(64,2) 12 input_y = [[x1+x2+random.rand()/10.0-0.05] for (x1,x2) in input_x] 13 print(input_x) 14 print(input_y) 15 x = input_x[:,0] 16 y = input_x[:,1] 17 z = input_y 18 # 绘制3D散点图,查看分布情况 19 fig = plt.figure() 20 ax = Axes3D(fig) 21 ax.scatter(x, y, z) 22 23 ax.set_zlabel('Z', fontdict={'size': 15, 'color': 'red'}) 24 ax.set_ylabel('Y', fontdict={'size': 15, 'color': 'red'}) 25 ax.set_xlabel('X', fontdict={'size': 15, 'color': 'red'}) 26 plt.show() 27 28 # 定义网络输入和输出以及参数 29 x = tf.placeholder(tf.float32,shape=(None,2)) 30 y_ = tf.placeholder(tf.float32,shape=(None,1)) 31 w = tf.Variable(tf.random_normal([2,1],stddev=1,seed=1)) 32 y = tf.matmul(x,w) 33 34 # 定义损失函数为MSE 35 loss = tf.reduce_mean(tf.square(y-y_)) 36 train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss) 37 38 # 生成会话,训练10000轮 39 with tf.Session() as sess: 40 init = tf.global_variables_initializer() 41 sess.run(init) 42 steps = 10000 43 for i in range(steps): 44 start = (i*batch_size)%64 45 end = (i*batch_size)%64+batch_size 46 sess.run(train_step,feed_dict={x:input_x[start:end],y_:input_y[start:end]}) 47 if i%500 ==0: 48 print("after ",i," steps,w is :",sess.run(w),"loss is :",sess.run(loss,feed_dict={x:input_x[start:end],y_:input_y[start:end]}),' ') 49 print("final,w is :",sess.run(w),"loss is :",sess.run(loss,feed_dict={x:input_x[start:end],y_:input_y[start:end]}),' ')
生成数据如下:
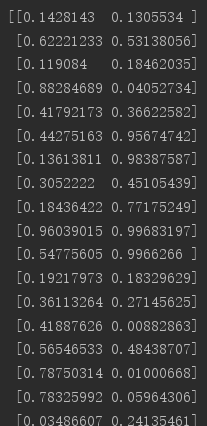

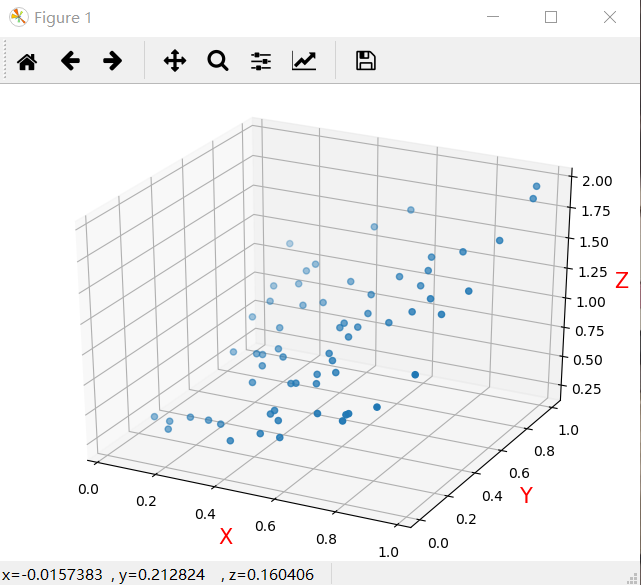
首先可以看到散点分布如图
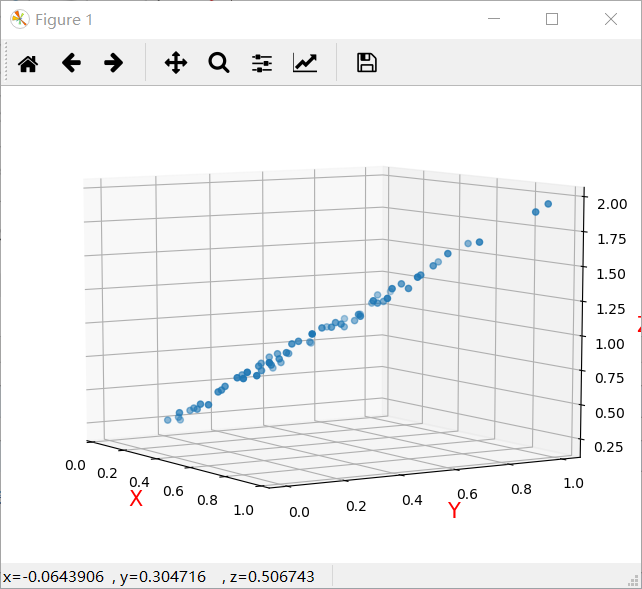
旋转一下方向可以看到,生成的数据是存在一定线性关系的
参数调优过程如下:
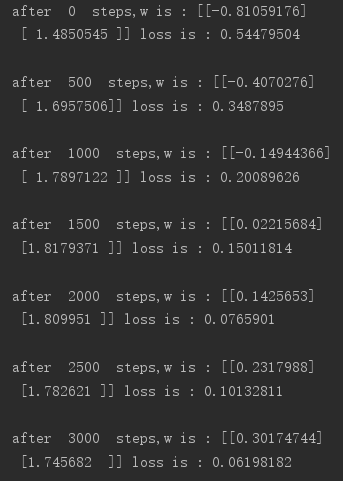
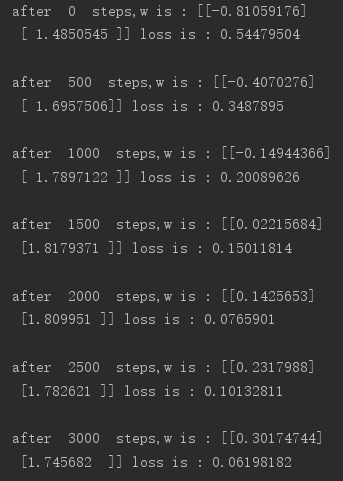
可以看到loss大致是在不断减小的,最终结果如下:
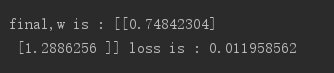
由上述过程可以看出,损失函数和线性回归存在一定的相似性,但是需要注意的是线性回归只能处理线性问题,而损失函数可以处理非线性的复杂模型。
感兴趣的读者可以修改上述代码实现线性回归原理。