原理,结构,基本命令,item,spider,selector简述
原理
(1)结构
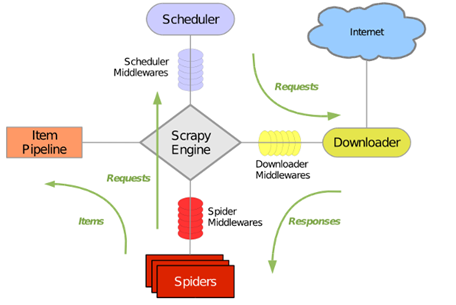

(2)运行流程

实操
(1) scrapy命令:
注意先把python安装目录的scripts文件夹添加到环境变量
查看帮助
scrapy
scrapy <command> -h
创建项目
scrapy startproject 项目名
创建爬虫
scrapy genspider [-t template] <name> <domain>
运行爬虫
运行一个爬虫的基本命令:
scrapy crawl 爬虫名
-a 给spider的构造器传参数
-o表示写入文件,-t 表示以json格式输出
scrapy crawl test -o test.json -t json
查看可用爬虫
scrapy list
快捷爬取(不需要创建爬虫项目,爬取结果直接回送到命令行)
scrapy fetch <url>

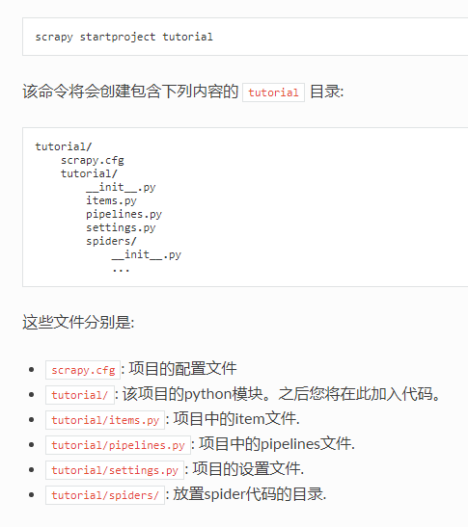
(2)项目结构功能
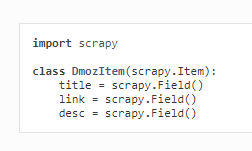
(3)item.py定义数据model
(4)spiders文件夹中的爬虫文件
name爬虫名,唯一
allowed_domains域名
start_urls起始url
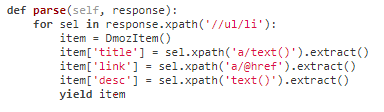
parse函数——处理爬取到的response的函数
基本格式:
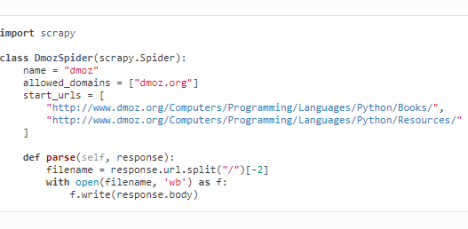
parse函数使用selector的格式:
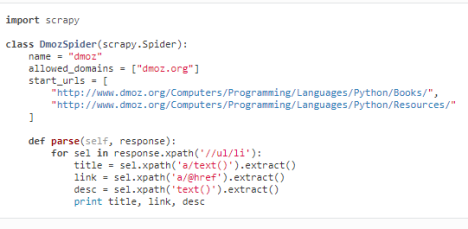
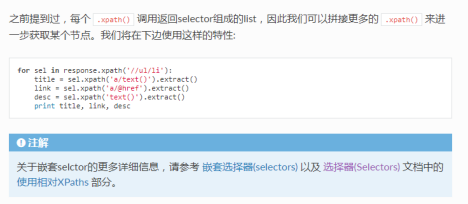
parse函数使用selector并通过生成器返回多个结果:
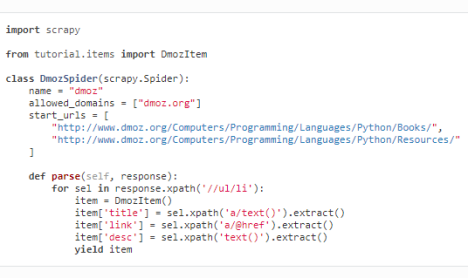
(5)selector
四种格式(即spider文件parse函数中response对象的四个可用方法)

response.xpath()
response.css()
response.extract()
举例:response.xpath()使用
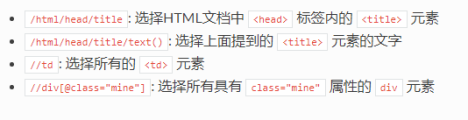
selector的嵌套
(6)保存爬取结果的方式之一:Feed Exports