requests高级部分
-
代理
- 代理概念:代理服务器
- 作用:接受请求==>请求转发
- 代理和爬虫之间的关联:
- 可以使用请求转发的机制使得目的服务器接受的请求对应ip的一个改变
- 为什么要使用代理改变请求的ip地址
- 爬程序在短时间内对指定的服务器发起了一个高频的请求,则请求对应的ip可能会被目的服务器禁止
- 代理的一些基础知识:
- 代理的匿名度:
- 透明代理:目的服务器知道你使用了代理机制,并且也知道你的真实ip
- 匿名代理:知道使用了代理机制,但是不知道你的真实ip
- 高匿代理:不知道你使用了代理,也不知道你的真实ip
- 代理的类型:
- http:
- https:
- 代理的匿名度:
- 免费代理ip:
- 快代理
- 西刺代理
- www.goubanjia.com
- 代理精灵 付费:http://http.zhiliandaili.cn/
-
cookie
-
验证码的识别
-
模拟登陆
需求:测试一下代理是否会生效
- 准备:
- 代理ip和端口
- 测试的过程
https://www.baidu.com/s?ie=utf-8&wd=ip
- get/post方法中使用proxies请求代理的设置
- proxies = {'http':'ip:port'}
import requests
from lxml import etree
url = 'http://www.baidu.com/s?ie=utf-8&wd=ip'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
page_text = requests.get(url=url,headers=headers,proxies={
'https': "114.98.26.47:4216"
}).text
with open('./ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
对西刺代理发起一个高频的请求,使得本机ip被禁止采用代理池解决反爬
-
url = "https://www.xicidaili.com/
-
在xpath表达式中一定不可以出现tbody标签
import requests from lxml import etree url = "https://www.xicidaili.com/nn/%d" headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" } ips = [] for page in range(1,30): new_url = format(url%page) page_text = requests.get(new_url,headers=headers).text tree = etree.HTML(page_text) tree_list = tree.xpath('//*[@id="ip_list"]//tr')[1:] for tr in tree_list: ip = tr.xpath('./td[2]/text()')[0] ips.append(ip) print(len(ips)) -
代理池的构建:就是一个列表,列表中存储的是字典,每一个字典存储的键值{'http':'ip:port'}
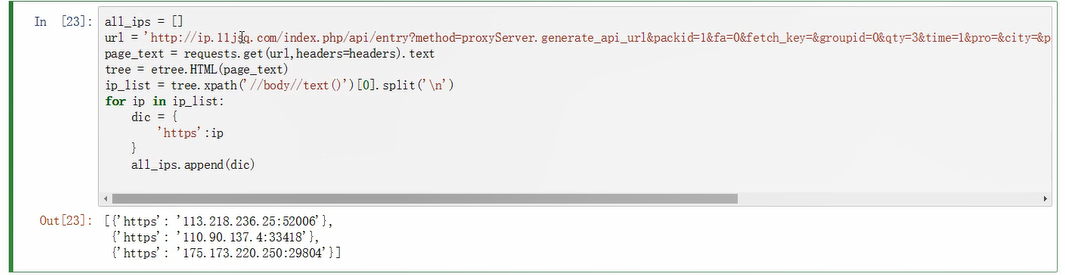
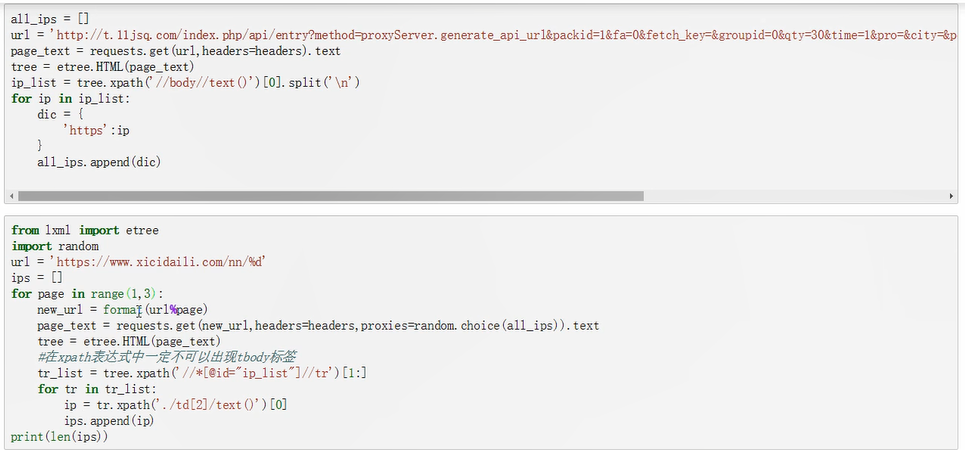
import requests
from lxml import etree
import random
url = "https://www.xicidaili.com/nn/%d"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
ips = []
for page in range(1,30):
new_url = format(url%page)
page_text = requests.get(new_url,headers=headers,proxies=random.choice(all_ips)).text
tree = etree.HTML(page_text)
tree_list = tree.xpath('//*[@id="ip_list"]//tr')[1:]
for tr in tree_list:
ip = tr.xpath('./td[2]/text()')[0]
ips.append(ip)
print(len(ips))
完整代码
cookie处理
- https://xueqiu.com/,对这个雪球网中的新闻数据进行爬取
- 分析:
- 新闻数据是通过ajax动态加载出来的
- 捕获到ajax数据包中的url
- 请求头中重要信息
- User-Agent
- Cookie
- Referer
- cookie的处理
- 手动处理
- 将cookie作用到headers中即可
- 自动处理
- session = requests.Session()
- session的作用:
- session可以像requests模块一样调用get和post进行请求发送
- 在进行请求发送的过程中如果产生了cookie则cookie会被自动存储到session的对象中
- 手动处理
session = requests.Session()
#第一次请求发送:为了捕获cookie且存储到session对象中
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
first_url = 'https://xueqiu.com/'
session.get(first_url,headers=headers)
#第二次请求发送:携带着cookie进行请求的发送
url = "https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=63198&size=15"
json_data = session.get(url=url,headers=headers).json()
print(json_data)
模拟登陆
- 为什么需要进行模拟登陆
- 有些数据不经过登陆是访问不到的
- 验证码的处理
- 基于线上的打码平台来实现
- 云打码
- 超级鹰:https://www.chaojiying.com/
- 超级鹰的使用流程:
- 基于用户中心的身份进行注册
- 用户中心的身份进行登陆:
- 充值
- 创建一个软件:点击软件ID => 生成软件ID
- 下载实例代码:
- 基于线上的打码平台来实现
#!/usr/bin/env python
# coding:utf-8
import requests
from lxml import etree
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
#
# if __name__ == '__main__':
# chaojiying = Chaojiying_Client('11111111', 'z12345678', '905817') #用户中心>>软件ID 生成一个替换 96001
# im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
# print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#封装一个识别码的函数
def transformCode(imgPath,imgType):
chaojiying = Chaojiying_Client('111111111', 'z12345678', '905817') #用户中心>>软件ID 生成一个替换 96001
im = open(imgPath, 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
return chaojiying.PostPic(im, imgType)['pic_str'] #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#使用打码平台识别古诗文网中的验证码图片
url = "https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
page_text = requests.get(url,headers=headers).text
tree = etree.HTML(page_text)
code_img_src = "https://so.gushiwen.org"+tree.xpath('//*[@id="imgCode"]/@src')[0]
img_data = requests.get(code_img_src,headers=headers).content
with open("./code.jpg",'wb')as fp:
fp.write(img_data)
print(transformCode('./code.jpg',1902))
-
模拟登陆
-
对点击登录按钮对应的url进行请求发送
-
动态变化的请求参数:
- 一般都会被隐藏咱前台页面中
- 基于抓包工具对请求参数的名称进行全局搜索
-
import requests
from lxml import etree
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
def transformCode(imgPath,imgType):
chaojiying = Chaojiying_Client('11111111', 'z12345678', '905817') #用户中心>>软件ID 生成一个替换 96001
im = open(imgPath, 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
return chaojiying.PostPic(im, imgType)['pic_str'] #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#处理cookie
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
session = requests.Session()
#获取且识别验证码
url = "https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx"
page_text = session.get(url,headers=headers).text
tree = etree.HTML(page_text)
#解析到了验证码图片的地址
code_img_src = "https://so.gushiwen.org"+tree.xpath('//*[@id="imgCode"]/@src')[0]
#解析出模拟登陆请求中动态变化的两个参数的值
__VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0]
__VIEWSTATEGENERATOR = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0]
#对图片进行请求时捕获cookie
img_data = session.get(code_img_src,headers=headers).content
with open("./code.jpg",'wb')as fp:
fp.write(img_data)
#验证码对应的文本数据
code_text = transformCode('./code.jpg',1902)
print(code_text)
#对于登录按钮的点击进行请求发送
login_url = "https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx"
data = {
"__VIEWSTATE":__VIEWSTATE,
"__VIEWSTATEGENERATOR": __VIEWSTATEGENERATOR,
"from": "http://so.gushiwen.org/user/collect.aspx",
"email": "1614655582@qq.com",
"pwd": "z12345678",
"code": code_text,
"denglu": "登录",
}
login_page_text=session.post(url=login_url,headers=headers,data=data).text
with open('./古文.html','w',encoding='utf-8')as fp:
fp.write(login_page_text)
- 总结:
- 验证码
- 动态汉化的请求参数
- cookie
- 代理
- UA
- robots