一:linux环境准备
vmware+CentOs-7.6
Local path:X:xxxHadoop2.Linux环境资料安装包
1.1安装好linux
内存4G,硬盘50G
1.2关闭防火墙
iptables -F 关闭防火墙
systemctl stop firewalld 关闭防火墙
systemctl disable firewalld 禁止开机启动
systemctl status firewalld 查看防火墙状态
1.3 设置静态IP
1.修改配置文件
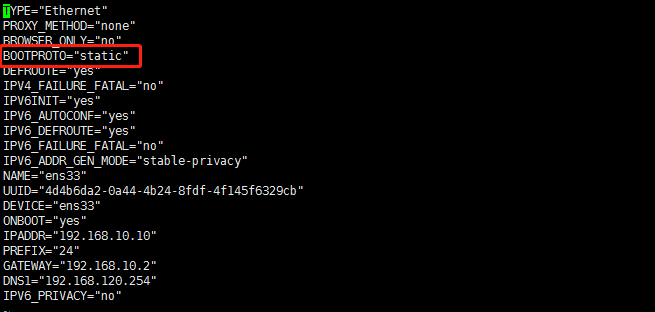
命令:[root@hdp-10 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static" 修改这一行
2.然后重启网卡
命令:[root@hdp-10 ~]# systemctl restart network
1.4安装常用工具
命令:[root@hdp-10 ~]# yum -y install vim wget lrzsz
1.5修改主机名
1.查看当前主机名
命令:[root@hdp-10 ~]# echo $HOSTNAME
2.修改主机名
命令:[root@hdp-10 ~]# hostnamectl set-hostname hdp-10.com
3.增加ip和主机的映射关系
命令:[root@hdp-10 ~]# vim /etc/hosts
增加内容:192.168.10.10 hdp-10

因为后面需要增加大量的映射关系,为了方便写一个脚本执行
(1)编辑脚本
命令:[root@hdp-10 ~]# vim test.sh
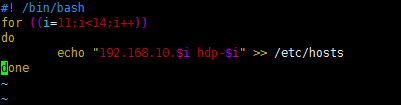
(2)脚本内容
#! /bin/bash
for ((i=11;i<14;i++))
do
echo "192.168.10.$i hdp-$i" >> /etc/hosts
done
(3)执行脚本
命令:[root@hdp-10 ~]# sh test.sh
(4)查看结果
命令:[root@hdp-10 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.10 hdp-10
192.168.10.11 hdp-11
192.168.10.12 hdp-12
192.168.10.13 hdp-13
1.6 创建一个一般用户deyi,配置密码
(1)创建用户
命令:[root@hdp-10 ~]# useradd deyi
(2)修改密码
命令:[root@hdp-10 ~]# passwd deyi
(3)配置这个用户为sudoers
命令:[root@hdp-10 ~]# vim /etc/sudoers
添加内容为:deyi ALL=(ALL) NOPASSWD:ALL

1.7在/opt目录下创建连个文件夹module 和software
命令:[root@hdp-10 ~]# mkdir /opt/module /opt/sofaware
把所有权赋给deyi用户
命令:[root@hdp-10 ~]# chown deyi:deyi /opt/module /opt/sofaware
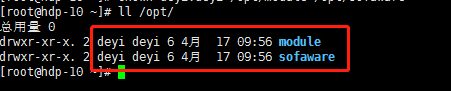
基础配置已经完成
二:Hadoop运行环境搭建(开发重点)
2.1基础步骤
1.克隆虚拟机
2.修改克隆虚拟机的静态ip
3.修改主机名
4.切换用户为deyi
2.2安装jdk Hadoop
1.将jdk、hadoop 包上传到虚拟机 /opt/sofaware 目录下
命令:[deyi@hdp-10 ~]$ cd /opt/sofaware/
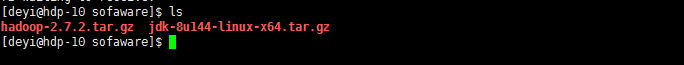
2.分别将jdk和hadoop解压到 /opt/module 目录下
命令:[deyi@hdp-10 sofaware]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
命令:[deyi@hdp-10 sofaware]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
3.配置环境变量
打开配置文件: /etc/profile
命令:[deyi@hdp-10 sofaware]$ sudo vim /etc/profile
在最末尾添加jdk路径和hadoop路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin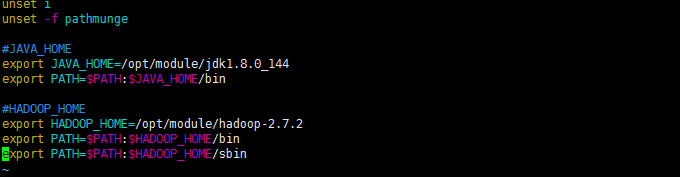
4.让修改后的文件生效
命令:[deyi@hdp-10 sofaware]$ source /etc/profile
5.查看配置文件是否成功
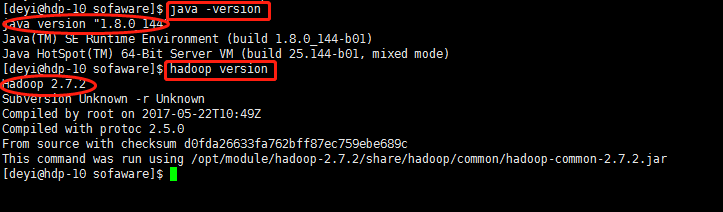
命令:[deyi@hdp-10 sofaware]$ java -version
命令:[deyi@hdp-10 sofaware]$ hadoop version
看见版本号说明配置成功
2.3Hadoop目录结构
1.查看hadoop目录结构
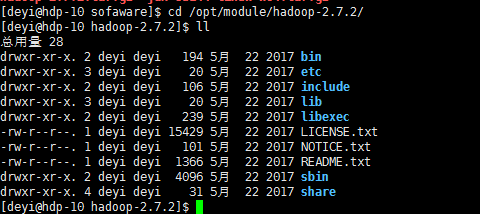
命令:[deyi@hdp-10 sofaware]$ cd /opt/module/hadoop-2.7.2/
命令:[deyi@hdp-10 hadoop-2.7.2]$ ll
2.重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
三:Hadoop运行模式
3.1本地运行模式
命令:[deyi@hdp-10 hadoop-2.7.2]$ cd etc/hadoop/
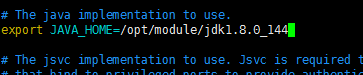
(1)配置:hadoop-env.sh
命令:[deyi@hdp-10 hadoop]$ vim hadoop-env.sh
修改JAVA_HOME 路径(大约25行):
export JAVA_HOME=/opt/module/jdk1.8.0_144
3.2官方WordCount案例
(1)创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
命令:[deyi@hdp-10 hadoop]$ cd /opt/module/hadoop-2.7.2/
命令:[deyi@hdp-10 hadoop-2.7.2]$ mkdir wcinput
(2)在wcinput文件下创建一个wc.input文件
命令:[deyi@hdp-10 hadoop-2.7.2]$ cd wcinput
命令:[deyi@hdp-10 wcinput]$ touch wc.input
(3)编辑wc.input文件
命令:[deyi@hdp-10 wcinput]$ vim wc.input
将以下内容输入
hadoop yarn
hadoop mapreduce
deyi
deyi

(4)执行程序
命令:[deyi@hdp-10 wcinput]$cd /opt/module/hadoop-2.7.2/
命令:[deyi@hdp-10 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
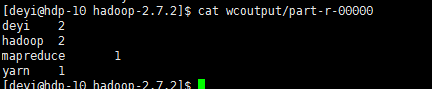
(5)查看结果
命令:[deyi@hdp-10 hadoop-2.7.2]$ cat wcoutput/part-r-00000
3.3伪分布式运行模式
启动HDFS并运行MapReduce程序
1. 分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
2. 执行步骤
(1)配置集群
命令:[deyi@hdp-10 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/etc/hadoop/
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
命令:[deyi@hdp-10 hadoop]$ echo $JAVA_HOME
/opt/module/jdk1.8.0_144

修改JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144
命令:[deyi@hdp-10 hadoop]$ vim hadoop-env.sh

(b)配置:core-site.xml
命令:[deyi@hdp-10 hadoop]$ vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-10:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>

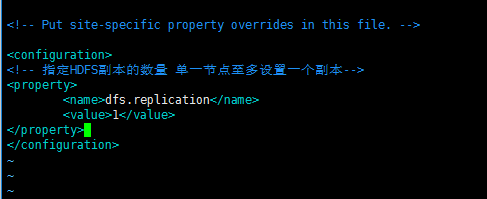
(c)配置:hdfs-site.xml
命令:[deyi@hdp-10 hadoop]$ vim hdfs-site.xml
<!-- 指定HDFS副本的数量 单一节点至多设置一个副本-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
命令:[deyi@hdp-10 hadoop]$ cd /opt/module/hadoop-2.7.2/ 回到hadoop-2.7.2目录下
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hdfs namenode -format 格式化命令

(b)启动NameNode
命令:[deyi@hdp-10 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode

(c)启动DataNode
命令:[deyi@hdp-10 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode

(3)查看集群
(a)查看是否启动成功
命令:[deyi@hdp-10 hadoop-2.7.2]$ jps

注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
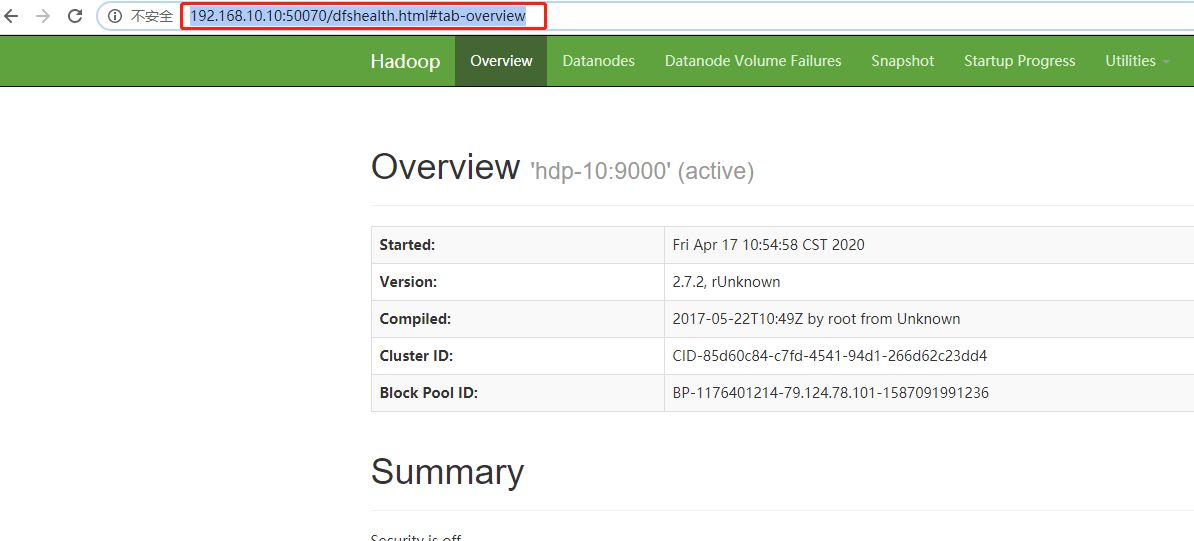
(b)web端查看HDFS文件系统
在浏览器上输入:http://192.168.10.10:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html
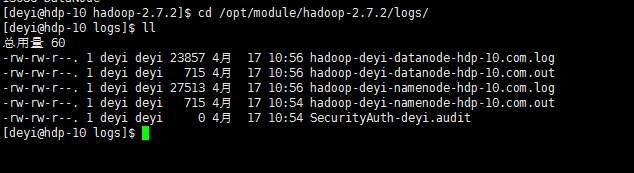
(c)查看产生的Log日志
说明:在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。
当前目录:/opt/module/hadoop-2.7.2/logs
命令:[deyi@hdp-10 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/logs/
命令:[deyi@hdp-10 logs]$ ll
(d)为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
命令:[deyi@hdp-10 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/

注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
命令:[deyi@hdp-10 current]$ cd /opt/module/hadoop-2.7.2/
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/deyi/input
(b)将测试文件内容上传到文件系统上
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hdfs dfs -put wcinput/wc.input /user/deyi/input/

(c)查看上传的文件是否正确
命令:bin/hdfs dfs -ls /user/deyi/input/

命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/deyi/input/wc.input
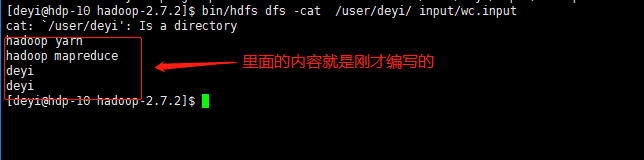
(d)运行MapReduce程序
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/deyi/input/ /user/deyi/output

(e)查看输出结果
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/deyi/output/*

(f)浏览器查看
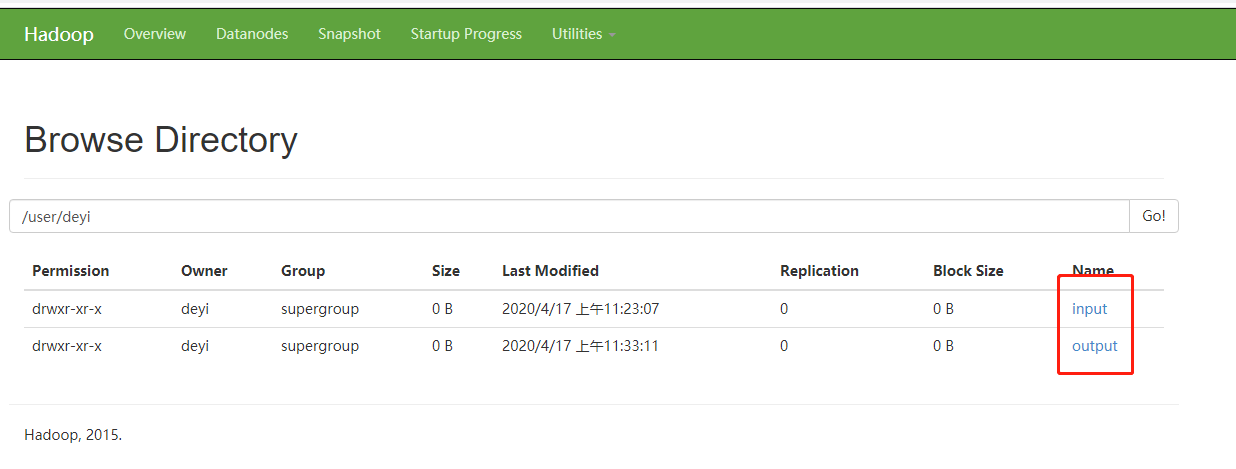

(g)将测试文件内容下载到本地
命令:[deyi@hdp-10 hadoop-2.7.2]$ hdfs dfs -get /user/deyi/output/part-r-00000 ./wcoutput/

(h)删除输出结果
命令:[deyi@hdp-10 hadoop-2.7.2]$ hdfs dfs -rm -r /user/deyi/output

四:启动YARN并运行MapReduce程序
1. 分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
2. 执行步骤
(1)配置集群
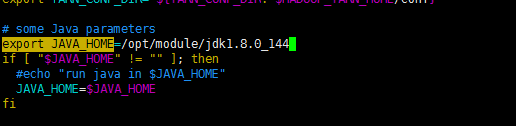
(a)配置yarn-env.sh
命令:[deyi@hdp-10 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/etc/hadoop/
命令:[deyi@hdp-10 hadoop]$ vim yarn-env.sh (大约23行)
修改如下
export JAVA_HOME=/opt/module/jdk1.8.0_144
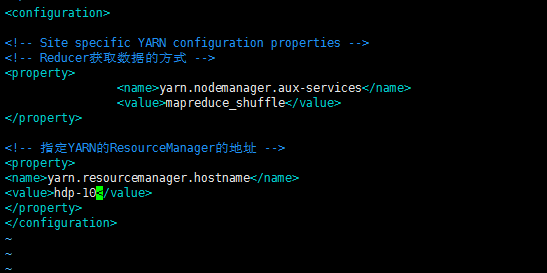
(b)配置yarn-site.xml
命令:[deyi@hdp-10 hadoop]$ vim yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-10</value>
</property>
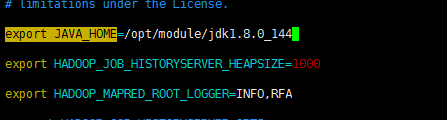
(c)配置:mapred-env.sh
命令:[deyi@hdp-10 hadoop]$ vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
命令:[deyi@hdp-10 hadoop]$ cp mapred-site.xml.template mapred-site.xml
命令:[deyi@hdp-10 hadoop]$ vim mapred-site.xml
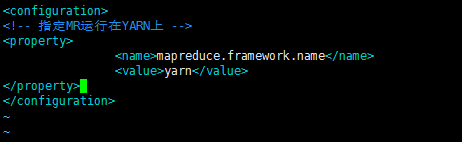
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(2)启动集群
(a)启动前必须保证NameNode和DataNode已经启动

(b)启动ResourceManager
命令:[deyi@hdp-10 hadoop]$ cd /opt/module/hadoop-2.7.2/
命令:[deyi@hdp-10 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
(c)启动NodeManager
命令:[deyi@hdp-10 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager

(3)集群操作
(a)YARN的浏览器页面查看
http://192.168.10.10:8088/cluster
(b)删除文件系统上的output文件
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/deyi/output
(c)执行MapReduce程序
命令:[deyi@hdp-10 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/deyi/input /user/deyi/output
(d)查看运行结果
命令:bin/hdfs dfs -cat /user/deyi/output/*
总结:。。。。。。。。。。。。。(此处省略一万字)