源码链接:https://github.com/yemahei/test
广告的转化率预估模型
- 总体介绍
目前,互联网公司中收入占比中,广告占了很大的比重,互联网广告是最重要的一种商业模式之一。如何提升广告的收入,那就是吸引更多的用户在自己的平台上做广告。这就涉及到一个推广效率的问题,用户只有在你这个平台上推广产品取得了很好的效果,他们才会信任你。
所以我做了一个广告的转化率预估模型。广告推广平台可以发挥特有的用户识别和转化跟踪数据能力,帮助广告主跟踪广告投放后的转化效果,基于广告转化数据训练转化率预估模型(pCVR,Predicted Conversion Rate),在广告排序中引入pCVR因子优化广告投放效果,提升ROI。
- 数据集介绍
2.1 数据集大小
从腾讯社交广告系统中某一连续两周的日志中按照推广中的App和用户维度随机采样。训练集370多万条数据 测试集30多万条数据。
2.2
数据集介绍集特征分析

广告特征介绍

用户特征

上下文特征

- 数据的预处理
a.连续属性离散化
b.类别特征编码
c.数据集成
将年龄和一天的时间进行连续属性离散化
将省份和城市以及app的类目进行类别特征编码
将各个数据表利用pandas库连接起来汇总成一个表
- 模型的建立
为什么选择随机森林
1、 在当前的很多数据集上,相对其他算法有着很大的优势,表现良好
2、它能够处理很高维度(feature很多)的数据,并且不用做特征选择
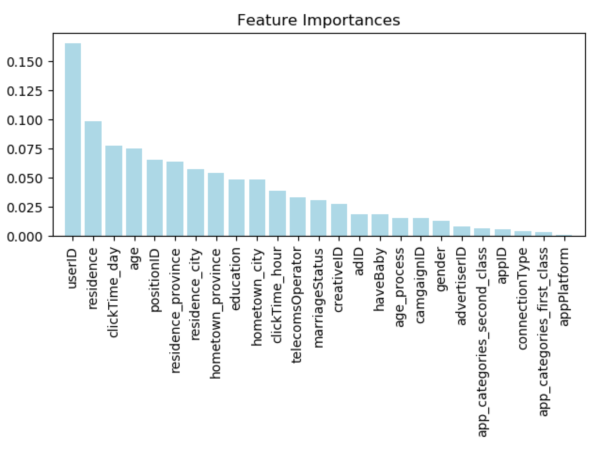
3、在训练完后,它能够给出哪些feature比较重要
4、在创建随机森林的时候,对generlization error使用的是无偏估计,模型泛化能力强
5、 对于不平衡的数据集来说,它可以平衡误差。
6、如果有很大一部分的特征遗失,仍可以维持准确度。
对数据进行平衡处理
数据的正负样本比:1:40 (会造成过拟合)
如何处理不平衡数据集
采用的Bagging:
Bagging基于自助采样法(bootstrap sampling)。给定包含m个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中。这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本再采样集里多次出现,有的则从未出现。
随机森林调参
1. n_estimators =100(决策树的个数)
2. max_depth 默认 (树的最大深度)
3. max_features 默认(选择最适属性时划分特征的最大值)
4. predict_proba (输出有概率的结果)
实验结果