一.字符编码
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65>>> ord('中')
20013>>> chr(66)
'B'>>> chr(25991)
'文'如果知道字符的整数编码,还可以用十六进制这么写str:
>>> 'u4e2du6587''中文'两种写法完全是等价的。
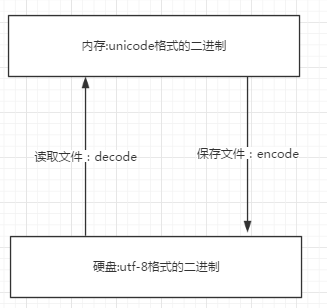
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'xe4xb8xadxe6x96x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'>>> b'xe4xb8xadxe6x96x87'.decode('utf-8')
'中文'要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3>>> len('中文')
2len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3>>> len(b'xe4xb8xadxe6x96x87')
6>>> len('中文'.encode('utf-8'))
6可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python
# -*- coding: utf-8 -*-总结
一
1.以什么编码存的就要以什么编码取出
ps:内存固定使用unicode编码
我们可以控制的编码是往硬盘存放或者基于网络传输选择编码
2.数据是最先产生于内存中,是unicode格式,要想传输需要转成bytes格式
#unicode ---------->encode(utf-8)---------->bytes
拿到bytes--------->decode(gbk)---------->unicode
3.python3中字符串被识别成unicode
python中的字符串encode得到bytes
二.
open:
1.会向操作系统发起系统调用,操作会打开一个文件
2.在python程序中会产生一个值指向操作系统打开那个文件,我们可以把该值赋给一个x。
回收资源
1.f.close(): 关闭操作系统打开的文件,即回收操作系统的资源
2.del f: 没必要做,因为在python程序运行完毕后,会自动清理与该程序有关的所有内存占用
f = open(r'aaaaa.py','r',encoding='utf-8') #print(f.read()) #print(f.readline(),end=") print(f.readlines()) f.close()
二Python对于文件处理的操作
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
read_f=open('a.txt','r',encoding='utf-8')
write_f=open('.a.txt.swp','w',encoding='utf-8')
with open('a.txt','r',encoding='utf-8') as read_f,#将文件打开
open('.a.txt.swp','w',encoding='utf-8') as write_f:#并且再创建一个文件名为.a.txt.swp的文件
for line in read_f:
if 'alex' in line: #找到想要替换的内容
line=line.replace('alex','ALEXSB') #并且将旧的内容替换成新的内容存在.a.txt.swp的文件中
write_f.write(line) #不符合条件的不动
os.remove('a.txt') #将源文件删除
os.rename('.a.txt.swp','a.txt') #将.a.txt.swp这个文件该成a.txt这样就实现了文件内容的批量修改!
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 |
关闭文件。关闭后文件不能再进行读写操作。 |
| 2 |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 |
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 |
如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 |
返回文件下一行。 |
| 6 |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 |
读取整行,包括 " " 字符。 |
| 8 |
读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 |
设置文件当前位置 |
| 10 |
返回文件当前位置。 |
| 11 |
从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后 V 后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| 12 |
将字符串写入文件,没有返回值。 |
| 13 |
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
三:三元表达式
由三个元素组成的表达式形式。
例如:
x=2
y=3
if 2<3:
print(x)
else:
print(y)
可以直接转换成三元表达式:
x if x<y else y