换了几个开发环境,每次都会遇到sparksql连不上元数据的情况,整理一下脱坑吧。。。。。
进入主题:
首先说一下几个文件吧,这些是我遇到的几个问题的解决方法,有可能你并不适用,仅供参考。
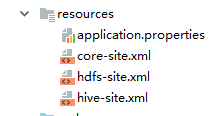
1、配置文件放在resources下面
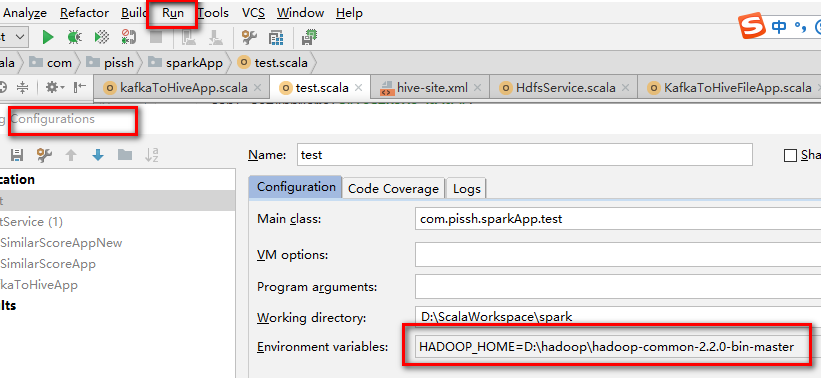
2、下载hadoop-common-2.2.0-bin-master 这个文件,里面有hadoop必要的bin文件,以此当做hadoop的家目录
配置如下:
3.启动的时候,你可能还会遇到mysql数据元字符的问题:
Specified key was too long; max key length is 767 bytes
我就直接贴了,把hive的元数据库改成latin1字符集,记住库和里面所有表
1 alter database hive character set latin1; 2 3 alter table BUCKETING_COLS convert to character set latin1; 4 alter table CDS convert to character set latin1; 5 alter table COLUMNS_V2 convert to character set latin1; 6 alter table DATABASE_PARAMS convert to character set latin1; 7 alter table DBS convert to character set latin1; 8 alter table FUNC_RU convert to character set latin1; 9 alter table FUNCS convert to character set latin1; 10 alter table GLOBAL_PRIVS convert to character set latin1; 11 alter table PART_COL_STATS convert to character set latin1; 12 alter table PARTITION_KEY_VALS convert to character set latin1; 13 alter table PARTITIONS convert to character set latin1; 14 alter table ROLES convert to character set latin1; 15 alter table SDS convert to character set latin1; 16 alter table SEQUENCE_TABLE convert to character set latin1; 17 alter table SERDES convert to character set latin1; 18 alter table SKEWED_STRING_LIST convert to character set latin1; 19 alter table SKEWED_STRING_LIST_VALUES convert to character set latin1; 20 alter table SORT_COLS convert to character set latin1; 21 alter table TAB_COL_STATS convert to character set latin1; 22 alter table TBLS convert to character set latin1; 23 alter table VERSION convert to character set latin1;
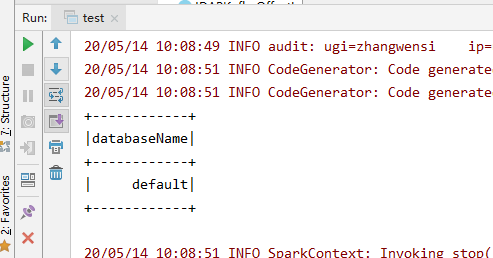
4.测试
1 object test { 2 def main(args: Array[String]): Unit = { 3 4 val conf = new SparkConf() 5 conf.setAppName(s"TestHive") 6 conf.setMaster("local[4]") 7 val spark = SparkSession.builder.config(conf).enableHiveSupport().getOrCreate() 8 9 spark.sql("show databases").show 10 } 11 12 }