最近一直在学习差分隐私,刚开始学的时候由于对这方面的知识不太清楚,一直处于模模糊糊的理解状态。现在学习了一段时间后开始有了一些初步的认识,所以把学习过程中的一些知识总结一下,方便以后复习,也为其他的小伙伴提供一些思路。由于我也是初学者,所以难免会出现一些错误,希望各位大佬可以指出。
本文的主要内容是按照Dwork在2013年写的The Algorithmic Foundations of Differential Privacy[1]展开的,但是也会穿插自己的一些理解。
整体的逻辑是按照三部分展开:
- 什么是差分隐私,利用一个简单例子形象说明
- 差分隐私的第一种形式,严格差分隐私
- 差分隐私的第二种形式,松弛差分隐私
- 附:符号的一些说明
1 - 什么是差分隐私
差分隐私顾名思义就是用来防范差分攻击的,我最早接触到差分攻击的概念是数据库课上老师介绍的。举个简单的例子,假设现在有一个婚恋数据库,2个单身8个已婚,只能查有多少人单身。刚开始的时候查询发现,2个人单身;现在张三跑去登记了自己婚姻状况,再一查,发现3个人单身。所以张三单身。
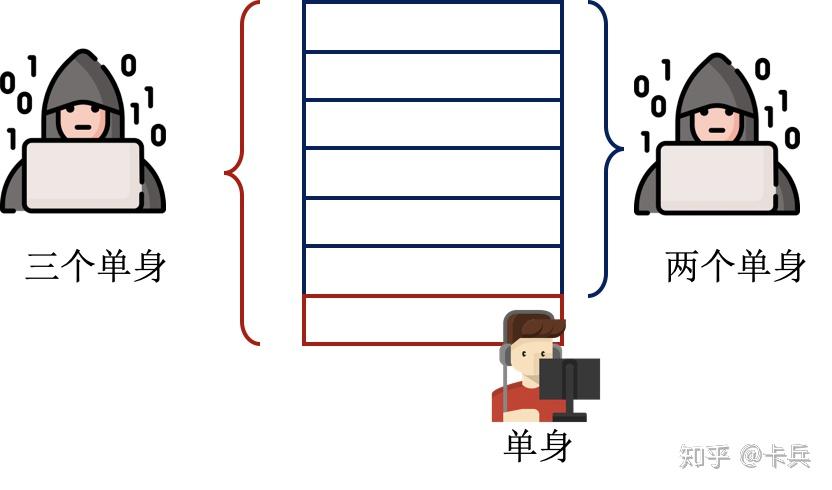 图1-1 差分攻击示意图
图1-1 差分攻击示意图
这里张三作为一个样本的的出现,使得攻击者获得了奇怪的知识。而差分隐私需要做到的就是使得攻击者的知识不会因为这些新样本的出现而发生变化。
那怎么做到呢?加入随机噪声。比如刚才的例子,本来两次查询结构是确定的2和3,现在加入随机噪声后,变成了两个随机变量,画出它们概率分布图。
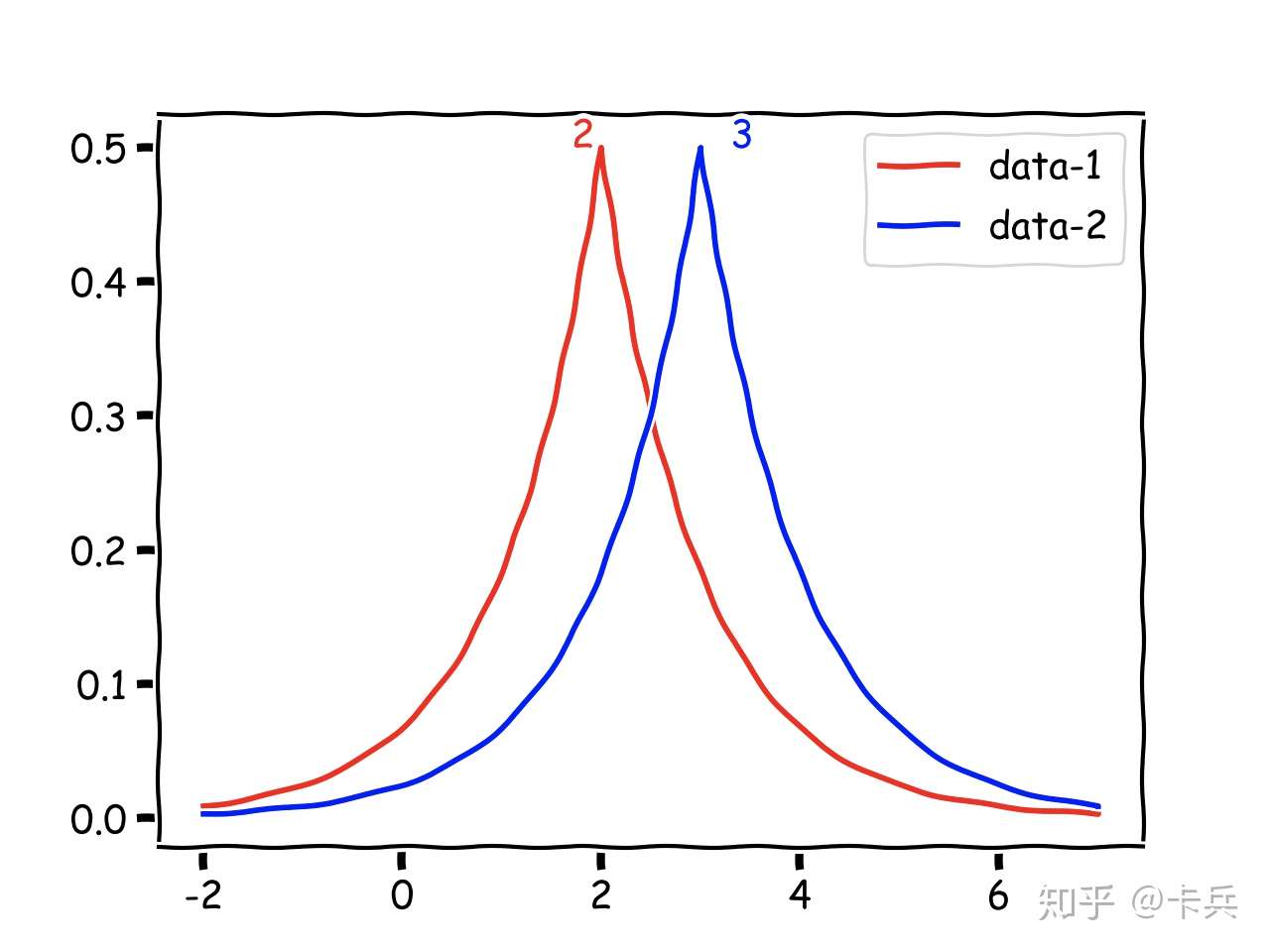 图1-2 概率分布图
图1-2 概率分布图
现在,如果张三不在数据库的话,得到结果可能是2.5;张三在的话,得到的结果也可能是2.5;两个数据集查询得到某一个结果的概率很接近,以至于我们根本分不清这个结果来自于哪一个数据集,这样也就实现了攻击者的知识不会因为张三这个样本的出现与否而发生变化。
这些只是概念上的理解,总结一下就是对查询的结果加入噪声,使得攻击者无法辨别某一样本是否在数据集中。一个形象的说法就是,双兔傍地走安能辨我是雄雌。
2 - 公式化的理解
刚才只是讲到概念上的理解,现在从数学上理解一下。上面的查询函数可以用 表示(这里暂时只考虑输出结果为1维的情况),随机噪声可以用
表示,最终得到的查询结果就是
,对于两个汉明距离为1的数据集
,对于任意的输出集合
,应该有:
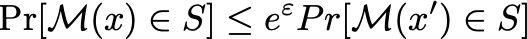 图2-1 差分隐私定义
图2-1 差分隐私定义
这是很多博客一上来就直接给出的定义公式,很少有解释是怎么来的,我在看了The Algorithmic Foundations of Differential Privacy这本书里面的3.5.1才明白。
首先还是得回到图1-2,我们的目的是使的这两个分布尽可能地接近,那么衡量两个分布 的差异自然可以用到我们熟悉的
KL-Divergence:
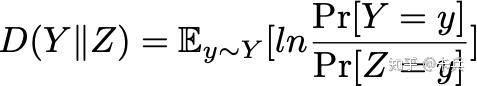
但是我们并不关心这两个分布的整体差异,我们只需要两个分布在差距最大的情况下能够被bound住,所以引入了MAX-Divergence,并且使得它小于 :
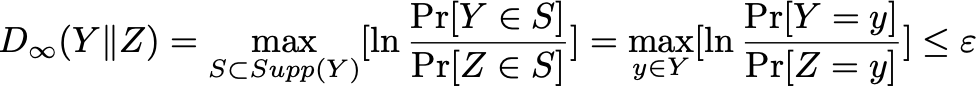
化简一下,利用 指数运算将
符号消去,然后将左边分母移到右边,就可以得到最开始的图2-1 差分隐私定义中定义的内容了。
刚开始读的时候,我容易把集合 和元素
弄混,后来发现,两者在表现
Max-Dvergence上是等价的。
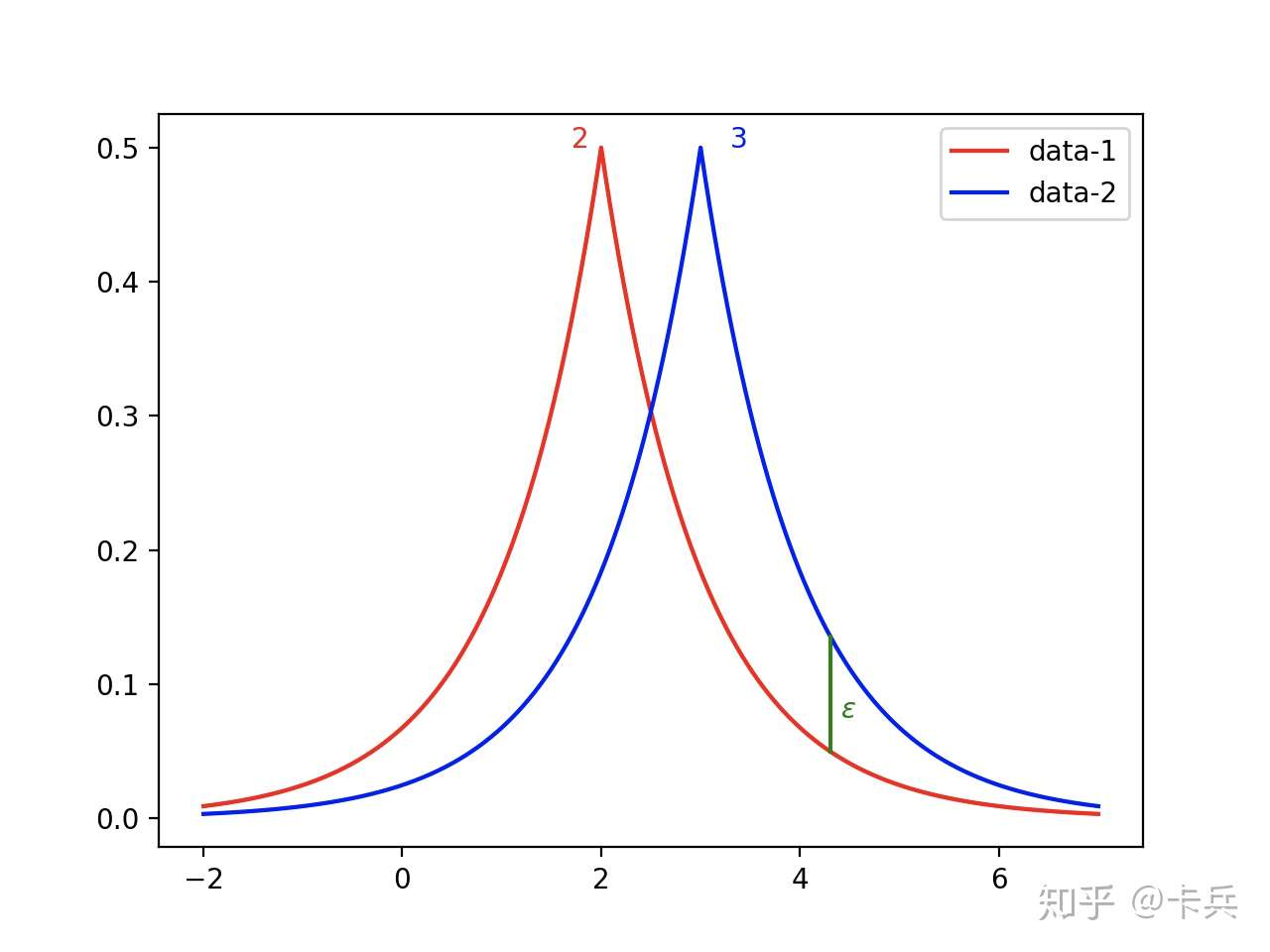 图 2-2 bound住Max-divergence
图 2-2 bound住Max-divergence
而 就被称为隐私预算,一般而言,
越小,隐私保护越好,但是加入的噪声就越大,数据可用性就下降了,如下图2-3,数据相对于正确的中心值更加分散。对于应用差分隐私的算法,首先会设定整体的隐私预算,每访问一次数据,就会扣除一些预算,当预算用完,数据就无法再访问,
 图2-3 更大噪声水平下的概率分布图
图2-3 更大噪声水平下的概率分布图
3 - 差分隐私的松弛
2中定义的差分隐私太过严格,在实际的应用中需要很多的隐私预算。因此为了算法的实用性,Dwork后面引入了松弛版本的差分隐私:
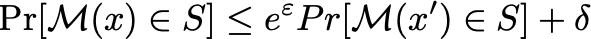
还是从对应的Max-Divergence来理解:
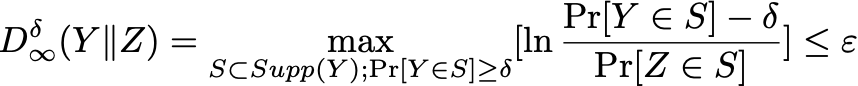
相比较于原始的式子,对分子减去了一个 ,也就是说我们可以容忍一个较小的差距。
直观形式如下图,像图中标注的位置,本来 是无法bound住,但是我们考虑松弛项
,整体依旧满足差分隐私。一般
都设置的比较小。
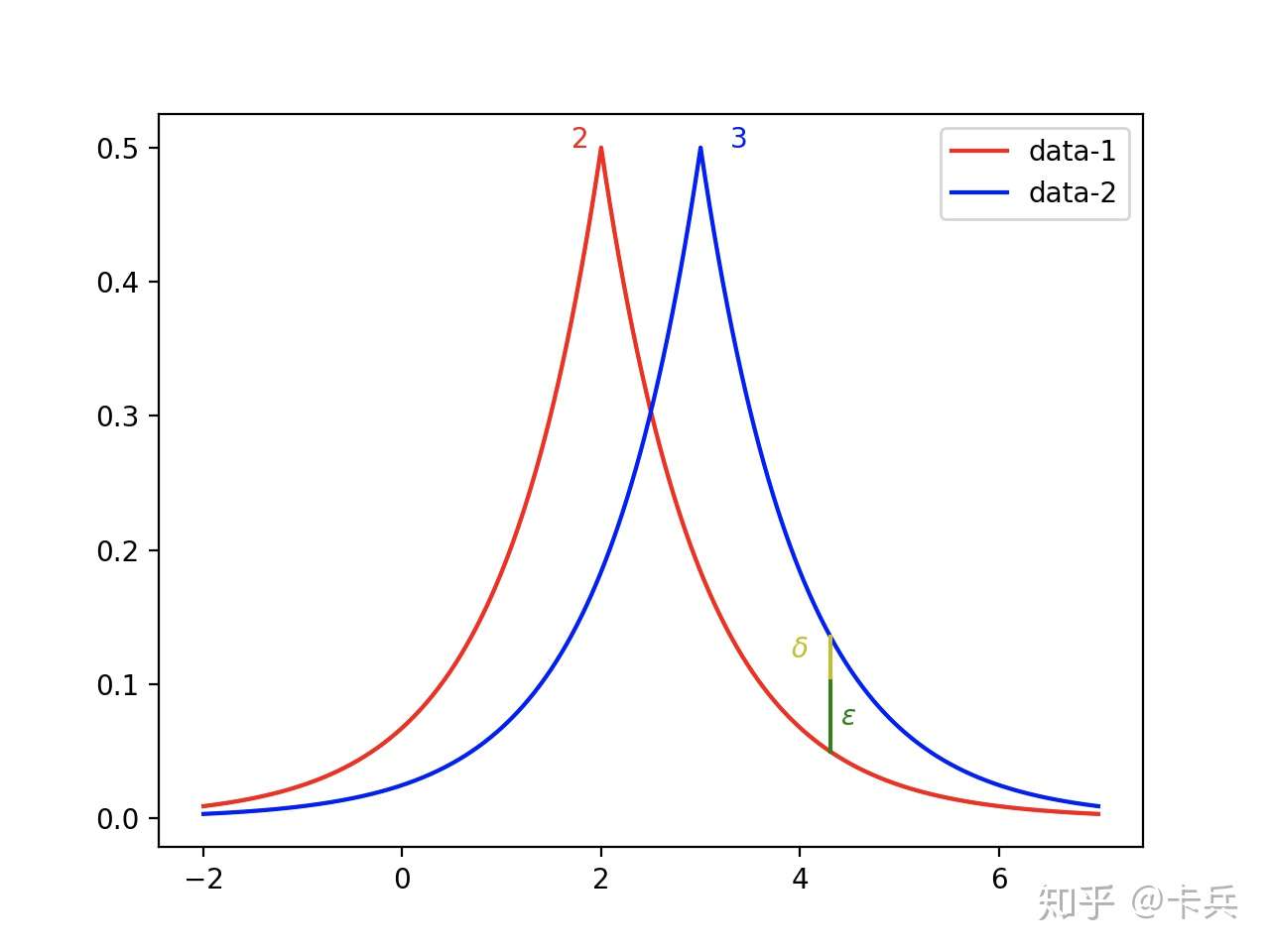 图3-1 松弛差分隐私
图3-1 松弛差分隐私
除了Dwork这里定义的松弛差分隐私,后面有许多工作都在围绕着如何定义出松弛的差分隐私,比如利用 Rényi Differential Privacy, privacy-loss的矩[2]。整体实现的目标就是,可以利用更少的隐私预算,得到相同的噪声尺度。
4 总结
这篇主要讲的差分隐私概念的来源和形式定义,但是对于差分隐私中的噪声怎么加没有讲,下面应该会去学习差分隐私中Laplace, Exponential, Gaussian三中噪声机制以及对应的证明。
5 符号
表示一个查询函数,比如查询count值,最大值,均值,梯度等等。
表示一个实数的概念,上标如果不写表示一维数据,比如最大值;如果是
表示n维数据,比如梯度。
表示一个随机噪声,可以服从高斯分布或者指数分布。
- 兄弟数据及
表示两个数据集只相差了一个样本。
表示最终的一个确定的查询结果
表示一个很小的值,用来衡量隐私预算。
是一个松弛项,表示可以接受差分隐私在一定程度上的不满足。
表示的是Renyi divergence,当
取不同值得时候代表不同的Divergence,比如KL-Divergence,Max-Divergence,是衡量两个分布的一种推广形式的表达,下一篇会讲到。
参考
https://zhuanlan.zhihu.com/p/139114240
- ^The Algorithmic Foundations of Differential Privacy https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
- ^Deep Learning with Differential Privacy https://arxiv.org/abs/1607.00133