1. 为什么需要动态hash
平常的hash,大多是下面这样一副面孔:
图1 一个静态hash结构
这种Hash维护着一些桶,就是图上左边的部分,每一个桶中装着hash值相同的数据。
这些具有相同hash值的数据形成一个链表。这种hash的一个最主要缺点就是桶的数目是一定的,不易扩展,随着插入数据增多,查找效率会急剧下降。
动态hash就是用来解决这个问题的,postgresql实现的动态hash保证填充因子不超过一个预定值的情况下动态地增长hash表的容量。同时每一次扩容所作的改动不大,空间利用率也比较地高。
2. 动态hash的结构
Postgresql与动态hash相关的代码分布在dynahash.c和hashfn.c这两个文件之中hashfn.c
主要是一些Hash Function,而dynahash.c才是动态hash的主要实现。
与普通hash表相比,动态hash多了一个新的行政单位: 目录。 如下图:
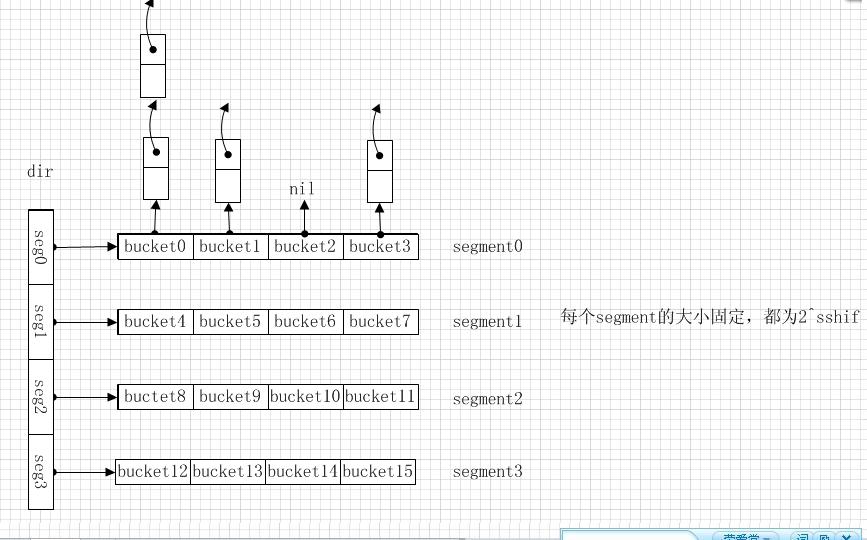
图2 postgresql 动态hash结构
dir是一个大小可变的数组,初始长度可以在创建时指定,以后每一次扩展其长度都会X2。dir中的每一项都指向一个长度固定的Segment, 这些Segment的长度都相同且必须是2的整数次幂,Segment数组中的元素是Bucket(桶) ,每一个桶中存放着一个链表,动态hash将所有具有相同hash值的元素都放在同一个桶中。
现在来看一下pg中 这些基本概念的定义:
- typedef struct HASHELEMENT
- {
- struct HASHELEMENT *link; /* link to next entry in same bucket */
- uint32 hashvalue; /* hash function result for this entry */
- } HASHELEMENT;
- /* A hash bucket is a linked list of HASHELEMENTs */
- typedef HASHELEMENT *HASHBUCKET;
- /* A hash segment is an array of bucket headers */
- typedef HASHBUCKET *HASHSEGMENT;
这些定义都可以和上图相对应,不再多说。
3. 给定hash value,如何找到与其对应的Bucket
先看一下实现吧:
- /* Convert a hash value to a bucket number */
- static inline uint32
- calc_bucket(HASHHDR *hctl, uint32 hash_val)
- {
- uint32 bucket;
- bucket = hash_val & hctl->high_mask;
- if (bucket > hctl->max_bucket)
- bucket = bucket & hctl->low_mask;
- return bucket;
- }
hctl->max_bucket 指的是bucket总数减1,对于图2来说,这个值为15
hctl->low_mask 是<= (hctl->max_bucket + 1)的最大的2^K减1, 对于图2来说,这个值是16 - 1 = 15 (0000 1111)
hctl->high_mask 是2^(K + 1)减1, 对于图2来说,这个值是32 - 1 = 31 (0x0001 1111)
这几个变量要注意的是,hctl->max_bucket在hash表创建好以后,会变化,一般情况下每次增加一个,如果hctl->max_bucket变成了2的整数次幂,就需要更新hctl->low_mask和hctl->high_mask。更新代码如下:
- /*
- * If we crossed a power of 2, readjust masks.
- */
- if ((uint32) new_bucket > hctl->high_mask)
- {
- hctl->low_mask = hctl->high_mask;
- hctl->high_mask = (uint32) new_bucket | hctl->low_mask;
- }
我们回头继续看那个calc_bucket函数, 因为理解这个函数是理解动态扩展的关键。从上面关于max_bucket,low_mask和high_mask的介绍,可以得出下面的结论:
hctl->high_mask >= hctl->max_bucket >= hctl->low_mask
反应在它们的二进制表示上,如果hctl->low_mask占m位(2^m - 1),则hctl->high_mask占m + 1位。而hctl->max_bucket是在闭区间[low_mask,high_mask]之间的。所以要取得hash_val的bucket值应优先&上high_mask,如果发现得到的bucket的序号比max_bucket还大,则再&上low_mask。这一步为后面的扩展埋下了伏笔。在扩展的时候,也就是max_bucket增加的时候,可能会造成这种情况,扩展前后同一hash_val通过calc_bucket算出的值不一样。下面在叙述扩展的时候再详细解说其解决办法 。
4. 动态扩展
5. 总结