Set接口
set接口表示一个无序,唯一的容器。
set接口提供的方法(方法其实和list接口的方法超级像,也是增,删,查)
public static void main(String[] args) { /** * 增:add/addAll * 删:clear/remove/removeAll/retainAll * 改: * 查:contains/containsAll * 遍历:iterator * 其他:size/isEmpty */ Set<Integer> set=new HashSet<Integer>(); //[1]添加 set.add(2); set.add(3); set.add(1); System.out.println(set); //[2]删除 set.remove(2); set.clear();//清空 //[3]查看是否包含 System.out.println(set.contains(3)); //其它 System.out.println(set.size()); System.out.println(set.isEmpty()); }
set遍历
public static void main(String[] args) { //遍历 Set<String> set=new HashSet<String>(); set.add("apple"); set.add("banana"); set.add("coco"); System.out.println(set); //快速遍历 for(String item:set){ System.out.println(item); } //迭代器 Iterator<String> it=set.iterator(); while (it.hasNext()) { String item = it.next(); System.out.println(item); } }
set的三个实现类:HashSet、LinkedHashSet、TreeSet。
一,HashSet
hashset底层数据是hash表,hashset的线程也不安全。
hash表工作原理:
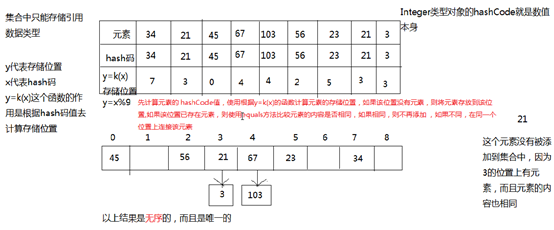
*理解:每个元素都有一个唯一的哈希码,然后利用函数公式可以把无数个哈希码放置在有限的储存位置上,数字的哈希码就是数字本身,那么自定义的对象又怎么存储到hashset中呢?
解决方法很简单:只需要在自定义对象的元素实现hashCode方法和equals方法即可
public class Student { private String name; private String type; private int age; //设置器访问器和有参无参构造省略 @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); result = prime * result + ((type == null) ? 0 : type.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; if (type == null) { if (other.type != null) return false; } else if (!type.equals(other.type)) return false; return true; } @Override public String toString() { return "Student [name=" + name + ", type=" + type + ", age=" + age + "]"; } }
测试类
public static void main(String[] args) { Student st1=new Student("wnagyi","001",19); Student st2=new Student("zhangsan","001",20); Student st3=new Student("lisi","001",22); HashSet<Student> set=new HashSet<Student>(); //自定义对象存储 set.add(st2); set.add(st3); set.add(st1); System.out.println(set); //快速遍历 for (Student item:set) { System.out.println(item); } //迭代器 Iterator<Student> it=set.iterator(); while (it.hasNext()) { Student item = it.next(); System.out.println(item); } }
其实 hashset的增删查效率都还可以,但就是没法有序。
那set接口的第二个实现类就出来了
二,linkedhashset
底层数据结构哈希表+链表
哈希表用于散列元素;链表用于维持添加顺序。
如果要添加自定义对象元素,也需要重写hashCode和equals方法。
理解:这里所谓的有序也只是单指在输入元素的时候的输入顺序,而且其他的增删改查方法都和hashset一样的。
三,treeset
底层数据结构是二叉树。
TreeSet 存储的数据按照一定的规则存储。存储规则让数据表现出自然顺序。
treeset工作原理:
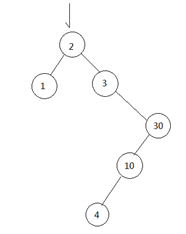
添加一个新元素t的存储的步骤
[1] 如果集合无元素,t直接加入;如果集合有元素,t和根节点比较;
[2] 如果t小于根节点;把t放到根节点的左子树上;重复1-3步骤
[3] t大于根节点;把t放到根节点的右子树上;重复1-3步骤
理解:添加的新元素从根节点开始比较,比根节点小的往左边走,大的往右边走,相同的被去掉。
输出时按照一定的规则:左子树->根节点->右子树
如果是数字类型的话放入元素还比较好比较,如果放入的是自定义的元素(无法正常通过大小去比较),那么很有可能会出现ClassCastException(类转换异常)
,所以我们得提供比较策略(内部比较器和外部比较器)
1,内部比较策略
当一个自定义对象实现Comparable并实现compareTo方法时,通过指定具体的比较策略,此时称为内部比较器
public class Student implements Comparable<Student> { private String name; private String type; private int age; //设置器访问器和有参无参构造省略 //hashcode和equals方法重写也省略了 @Override public int compareTo(Student o) { if(this.getAge()<o.getAge()) { return -1; }else if(this.getAge() == o.getAge()) { //多种比较情况:如果这里相等了,treeset会认为两个元素相同而删除一个的,所以还得在这里继续比较其它的不同的属性 return 0; }else { return 1; } } }
2,外部比较策略
当实际开发过程中不知道添加元素的源代码、无权修改别人的代码,此时可以使用外部比较器。
Comparator 位于java.util包中,定义了compare(o1,o2) 用于提供外部比较策略。
TreeSet接受一个指定比较策略的构造方法,这些比较策略的实现类必须实现Comparator
接口。
需求:按照字符串的长度比较
public static void main(String[] args) { TreeSet<String> set=new TreeSet<String>(new Comparator<String>() { @Override public int compare(String o1, String o2) { return o1.length()-o2.length(); } }); //标记的地方都是匿名内部类 里面重写一个比较方法。 set.add("banana"); set.add("coco"); set.add("apple"); set.add("apple"); System.out.println(set); }
接下来介绍与List接口和Set接口齐名的Map接口
Map接口称为键值对集合或者映射集合,其中的元素(entry)是以键值对(key-value)的形式存在。
Map接口中都是通过key来操作键值对,一般key是已知。通过key获取value
举一反三:
Map 容器接口中提供了增、删、改、查的方式对集合进行操作;
提供了遍历方法;
以及三个实现类(HashMap,LinkedHashMap,TreeMap)
那下面一个个来介绍一下:
/** 增删改查等方法就不用多写了,和前面不一样的是个别代码的变化 * 增:put/putAll * 删:clear/remove * 改:put * 查:get/containsKey/containsValue * 其他:isEmpty/size */
遍历:
public static void main(String[] args) { Map<String, String> map=new HashMap<String,String>(); map.put("A", "apple"); map.put("B", "banana"); map.put("C", "coco"); System.out.println(map); //快速遍历 Set<String> key=map.keySet(); for(String item:key){ System.out.println(item+"=>"+map.get(item)); }
//迭代器 Iterator<String> it=key.iterator(); while (it.hasNext()) { String item = it.next(); System.out.println(item+"=>"+map.get(item)); } }
三个实现类之
1,HashMap
key以HashSet存储
public static void main(String[] args) { /* 以string对象向hashmap中添加元素(默认是可以自然排序的,不需要重写方法) HashMap<String, Object> map = new HashMap<String,Object>(); ArrayList<String> list1 = new ArrayList<String>(); list1.add("alex"); list1.add("alice"); list1.add("allen"); map.put("A", list1); ArrayList<String> list2 = new ArrayList<String>(); list2.add("ben"); list2.add("bill"); map.put("B", list2); System.out.println(map); */ //以自定义对象向hashmap中添加元素(必须要重写student类的hashcode和equals方法) HashMap<Student, Object> map = new HashMap<Student,Object>(); ArrayList<String> list1 = new ArrayList<String>(); list1.add("alex"); list1.add("alice"); list1.add("allen"); Student s1 = new Student("001", "大狗", 20); map.put(s1, list1); ArrayList<String> list2 = new ArrayList<String>(); list2.add("ben"); list2.add("bill"); Student s2 = new Student("001", "大狗", 20); // 修改 map.put(s2, list2); System.out.println(map); }
2,LinkedHashMap
key以LinkedHashSet存储。
哈希表散列key,链表维持key的添加顺序。
这个不同于hashmap的地方就是:添加元素的顺序也可以是一种顺序
3,TreeMap
key以TreeSet存储
特点也是需要提供比较策略。
TreeMap<String, Object> map = new TreeMap<String,Object>(new Comparator<String>() { @Override public int compare(String o1, String o2) { return o1.length() - o2.length(); } }); //匿名内部类+比较策略 ArrayList<String> list2 = new ArrayList<String>(); list2.add("ben"); list2.add("bill"); map.put("Aa", list2); ArrayList<String> list1 = new ArrayList<String>(); list1.add("alex"); list1.add("alice"); list1.add("allen"); map.put("B", list1); System.out.println(map);