众所周知,在互联网诞生之初都是各个高校和科研机构相互通讯,并没有网络流量控制方面的考虑和设计,IP协议的原则是尽可能好地为所有数据流服务,不同的数据流之间是平等的。然而多年的实践表明,这种原则并不是最理想的,有些数据流应该得到特别的照顾, 比如,远程登录的交互数据流应该比数据下载有更高的优先级。
针对不同的数据流采取不同的策略,这种可能性是存在的。并且,随着研究的发展和深入, 人们已经提出了各种不同的管理模式。IETF已经发布了几个标准, 如综合服务(Integrated Services)、区分服务(Diferentiated Services)等。其实,Linux内核从2 2开始,就已经实现了相关的流量控制功能。本文将介绍Linux中有关流量控制的相关概念, 用于流量控制的工具TC的使用方法,并给出几个有代表性实例。
一、相关概念
由此可以看出, 报文分组从输入网卡(入口)接收进来,经过路由的查找, 以确定是发给本机的,还是需要转发的。如果是发给本机的,就直接向上递交给上层的协议,比如TCP,如果是转发的, 则会从输出网卡(出口)发出。网络流量的控制通常发生在输出网卡处。虽然在路由器的入口处也可以进行流量控制,Linux也具有相关的功能, 但一般说来, 由于我们无法控制自己网络之外的设备, 入口处的流量控制相对较难。本文将集中介绍出口处的流量控制。流量控制的一个基本概念是队列(Qdisc),每个网卡都与一个队列(Qdisc)相联系, 每当内核需要将报文分组从网卡发送出去, 都会首先将该报文分组添加到该网卡所配置的队列中, 由该队列决定报文分组的发送顺序。因此可以说,所有的流量控制都发生在队列中,详细流程图见图1。

图1报文在Linux内部流程图
有些队列的功能是非常简单的, 它们对报文分组实行先来先走的策略。有些队列则功能复杂,会将不同的报文分组进行排队、分类,并根据不同的原则, 以不同的顺序发送队列中的报文分组。为实现这样的功能,这些复杂的队列需要使用不同的过滤器(Filter)来把报文分组分成不同的类别(Class)。这里把这些复杂的队列称为可分类(ClassfuI)的队列。通常, 要实现功能强大的流量控制, 可分类的队列是必不可少的。因此,类别(class)和过滤器(Filter)也是流量控制的另外两个重要的基本概念。图2所示的是一个可分类队列的例子。
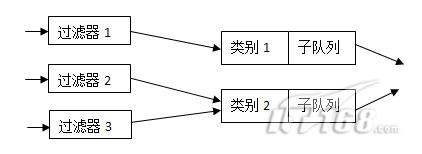
图2多类别队列
由图2可以看出,类别(CIass)和过滤器(Filter)都是队列的内部结构, 并且可分类的队列可以包含多个类别,同时,一个类别又可以进一步包含有子队列,或者子类别。所有进入该类别的报文分组可以依据不同的原则放入不同的子队列或子类别中,以此类推。而过滤器(Filter)是队列用来对数据报文进行分类的工具, 它决定一个数据报文将被分配到哪个类别中。
二、使用TC
在Linux中,流量控制都是通过TC这个工具来完成的。通常, 要对网卡进行流量控制的配置,需要进行如下的步骤:
◆ 为网卡配置一个队列;
◆ 在该队列上建立分类;
◆ 根据需要建立子队列和子分类;
◆ 为每个分类建立过滤器。
在Linux中,可以配置很多类型的队列,比如CBQ、HTB等,其中CBQ 比较复杂,不容易理解。HTB(HierarchicaIToken Bucket)是一个可分类的队列, 与其他复杂的队列类型相比,HTB具有功能强大、配置简单及容易上手等优点。在TC 中, 使用"major:minor"这样的句柄来标识队列和类别,其中major和minor都是数字。
对于队列来说,minor总是为0,即"major:0"这样的形式,也可以简写为"major: 比如,队列1:0可以简写为1:。需要注意的是,major在一个网卡的所有队列中必须是惟一的。对于类别来说,其major必须和它的父类别或父队列的major相同,而minor在一个队列内部则必须是惟一的(因为类别肯定是包含在某个队列中的)。举个例子,如果队列2:包含两个类别,则这两个类别的句柄必须是2:x这样的形式,并且它们的x不能相同, 比如2:1和2:2。
下面,将以HTB队列为主,结合需求来讲述TC的使用。假设eth0出口有100mbit/s的带宽, 分配给WWW 、E-mail和Telnet三种数据流量, 其中分配给WWW的带宽为40Mbit/s,分配给Email的带宽为40Mbit/s, 分配给Telnet的带宽为20Mbit/S。如图3所示。
需要注意的是, 在TC 中使用下列的缩写表示相应的带宽:
◆ Kbps kiIobytes per second, 即"千字节每秒 ;
◆ Mbps megabytes per second, 即"兆字节每秒 ,
◆ Kbit kilobits per second,即"千比特每秒 ;
◆ Mbit megabits per second, 即"兆比特每秒 。
三、创建HTB队列
有关队列的TC命令的一般形式为:
#tc qdisc [add|change|replace|link] dev DEV [parent qdisk-id|root][handle qdisc-id] qdisc[qdisc specific parameters]
首先,需要为网卡eth0配置一个HTB队列,使用下列命令:
#tc qdisc add dev eth0 root handle 1:htb default 11
这里,命令中的"add 表示要添加,"dev eth0 表示要操作的网卡为eth0。"root 表示为网卡eth0添加的是一个根队列。"handle 1: 表示队列的句柄为1:。"htb 表示要添加的队列为HTB队列。命令最后的"default 11 是htb特有的队列参数,意思是所有未分类的流量都将分配给类别1:11。
四、为根队列创建相应的类别
有关类别的TC 命令的一般形式为:
#tc class [add|change|replace] dev DEV parent qdisc-id [classid class-id] qdisc [qdisc specific parameters]
可以利用下面这三个命令为根队列1创建三个类别,分别是1:1 1、1:12和1:13,它们分别占用40、40和20mb[t的带宽。
#tc class add dev eth0 parent 1: classid 1:1 htb rate 40mbit ceil 40mbit
#tc class add dev eth0 parent 1: classid 1:12 htb rate 40mbit ceil 40mbit
#tc class add dev eth0 parent 1: cllassid 1:13 htb rate 20mbit ceil 20mbit
命令中,"parent 1:"表示类别的父亲为根队列1:。"classid1:11"表示创建一个标识为1:11的类别,"rate 40mbit"表示系统
将为该类别确保带宽40mbit,"ceil 40mbit",表示该类别的最高可占用带宽为40mbit。
五、为各个类别设置过滤器
有关过滤器的TC 命令的一般形式为:
#tc filter [add|change|replace] dev DEV [parent qdisc-id|root] protocol protocol prio priority filtertype [filtertype specific parameters] flowid flow-id
由于需要将WWW、E-mail、Telnet三种流量分配到三个类别,即上述1:11、1:12和1:13,因此,需要创建三个过滤器,如下面的三个命令:
#tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 80 0xffff flowid 1:11
#tc filter add dev eth0 prtocol ip parent 1:0 prio 1 u32 match ip dport 25 0xffff flowid 1:12
#tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 23 oxffff flowid 1:13
这里,"protocol ip"表示该过滤器应该检查报文分组的协议字段。"pr[o 1" 表示它们对报文处理的优先级是相同的,对于不同优先级的过滤器, 系统将按照从小到大的优先级。
顺序来执行过滤器, 对于相同的优先级,系统将按照命令的先后顺序执行。这几个过滤器还用到了u32选择器(命令中u32后面的部分)来匹配不同的数据流。以第一个命令为例,判断的是dport字段,如果该字段与Oxffff进行与操作的结果是8O,则"flowid 1:11" 表示将把该数据流分配给类别1:1 1。更加详细的有关TC的用法可以参考TC 的手册页。
六、复杂的实例
在上面的例子中, 三种数据流(www、Email、Telnet)之间是互相排斥的。当某个数据流的流量没有达到配额时,其剩余的带宽并不能被其他两个数据流所借用。在这里将涉及如何使不同的数据流可以共享一定的带宽。
首先需要用到HTB的一个特性, 即对于一个类别中的所有子类别,它们将共享该父类别所拥有的带宽,同时,又可以使得各个子类别申请的各自带宽得到保证。这也就是说,当某个数据流的实际使用带宽没有达到其配额时, 其剩余的带宽可以借给其他的数据流。而在借出的过程中,如果本数据流的数据量增大,则借出的带宽部分将收回, 以保证本数据流的带宽配额。
下面考虑这样的需求, 同样是三个数据流WWW、E-mail和Telnet, 其中的Telnet独立分配20Mbit/s的带宽。另一方面,VWVW 和SMTP各自分配40Mbit/s。同时,它们又是共享的关系, 即它们可以互相借用带宽。如图3所示。

需要的TC命令如下:
#tc qdisc add dev eth0 root handle 1: htb default 21
#tc class add dev eth0 partent 1: classid 1:1 htb rate 20mbit ceil 20mbit
#tc class add dev eth0 parent 1: classid 1:2 htb rate 80mbit ceil 80mbit
#tc class add dev eth0 parent 1: classid 1:21 htb rate 40mbit ceil 20mbit
#tc class add dev eth0 parent 1:2 classid 1:22 htb rate 40mbit ceil 80mbit
#tc filter add dev eth0 protocol parent 10 prio 1 u32 match ip dport 80 0xffff flowid 1:21
#tc filter add dev eth0 protocol parent 1:0 prio 1 u32 match ip dport 25 0xffff flowid 1:22
#tc filter add dev eth0 protocol parent 1:0 prio 1 u32 match ip dport 23 0xffff flowid 1:1
这里为根队列1创建两个根类别,即1:1和1:2,其中1:1对应Telnet数据流,1:2对应80Mbit的数据流。然后,在1:2中,创建两个子类别1:21和1:22,分别对应WWW和E-mail数据流。由于类别1:21和1:22是类别1:2的子类别,因此他们可以共享分配的80Mbit带宽。同时,又确保当需要时,自己的带宽至少有40Mbit。
从这个例子可以看出,利用HTB中类别和子类别的包含关系,可以构建更加复杂的多层次类别树,从而实现的更加灵活的带宽共享和独占模式,达到企业级的带宽管理目的。