Wide&Deep learning
最近调试了几天WDL,留个笔记。
WDL是Google在2016年的paper,目标是用于自己Google play中的app推荐。
推荐系统
推荐系统主要分为两个部分,检索系统(Retrieval)和排序系统(Ranking)。
首先用检索的方法对大数据集进行初步筛选,返回一个query list。这里retrieval通常会结合采用机器学习模型和人工定义规则两种方法。
得到query list后,再使用排序系统对每个item进行打分和排序。
分数值P(y|x), y是采取的行为,x是特征,一般包括
User feature
Contextual feature
Impression feature
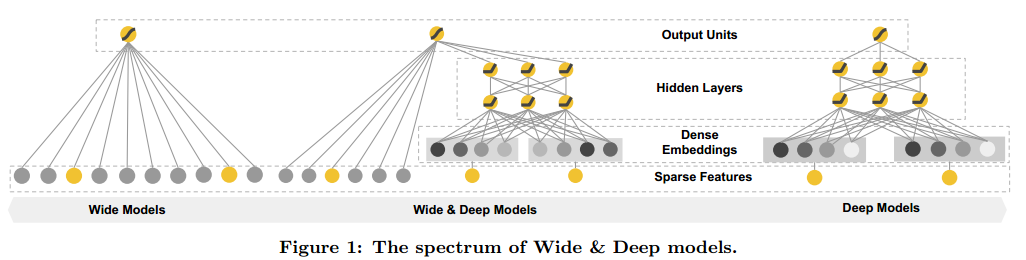
memorization & generalization
推荐系统重要问题之一,解决memorization(记忆)和generalization(归纳)。
memorization主要是基于历史数据 学习频繁共同出现的item,并且探索他们之间的相关性,也就是根据历史行为数据,推荐相关的item(topical),由wide作为主导;
generalization主要是基于相关性之间的传递, 探索历史上没有出现的新的特征的组合,也就是实现了推荐的多样性问题(diversity),deep作为主导。
wide model
wide model主要采用逻辑回归(LR),LR的特征一般是二值且稀疏的,这里采用one-hot编码。特征组合(cross-product transformation),只有当变量同时满足时才会取值为1,否则为0。但是这存在局限,当训练集里没有出现过query-item pair,就不能进行泛化。
Linear model:。其中特征x包括原始的输入特征以及组合特征。
cross-product transformation特征表示为:
是一个bool变量,如果第i个特征是第k个transformation
的一部分,那么值就是1,否则就是0。
deep model
deep就是deep learning了,模型输入包括类型特征(embedding)+连续特征。
对于特殊兴趣或者小众用户,query-item matrix非常稀疏,dense embedding的方法可以得到对所有query-item pair非零的预测,但是容易过度泛化over-generalize,这点正好和LR互补。
每一个隐层(hidden-layer):
f激活函数(default=ReLu), l是层数。
Joint Training
TensorFlow实现
没自己实现过的东西理解就是不深。代码实现这块google在github给出了DEMO and myself code。
不过在自己套用时就会出现问题,毕竟应用场景不同了。
首先是特征维度这块,DEMO中的维度较少,全list出来还能接受,如果是一个上百维或者千维的,那就崩了。。。。
将所有列定义为连续(continuous)或者分类(categorical)。categorical_columns,有限集的一部分(eg:sex,name)。
对于类别较多的categorical_columns,使用哈希值作为键值。continuous_columns使用的是真实值。
continuous_columns,连续范围内的任何数值(eg:money or age)。
Bucketization(桶化),将连续值分组看待,而不是将所有的作为一个大整体,提高准确性。
def csv_head():
categorical_columns = ["C"+str(i) for i in range(1,6)] #这里是5-dims, not 6-dims
continuous_columns = ["I"+str(i) for i in range(1,5)]
label_column = ["label"]
feature_columns = categorical_columns + continuous_columns
CSV_COLUMNS = feature_columns + label_column
return feature_columns, label_column, CSV_COLUMNS
def process_feature():
wide_columns = []
for name in categorical_columns:
wide_columns.append(tf.feature_column.categorical_column_with_hash_bucket(
name, hash_bucket_size=1000))
deep_columns = []
for name in continuous_columns:
deep_columns.append(tf.feature_column.numeric_column(name))
for col in wide_columns:
deep_columns.append(tf.feature_column.embedding_column(
col, dimension=8))
price_buckets = []
for i in range(7):
price_buckets.append( tf.feature_column.bucketized_column(deep_columns[i],
boundaries=[10, 20, 30, 40, ]))
wide_columns.extend(price_buckets)
cross = [["C3", "C4"], ["C4", "C5"], ["C3","C4","C5"]]
crossed_columns = []
for name in cross:
crossed_columns.append(tf.feature_column.crossed_column(name,hash_bucket_size=50))
return wide_columns, deep_columns, crossed_columns
然后就是.predict那步。输入特征x就好,不需要label,在input_fn的返回值处去掉y就好。返回结果是一个generator的格式,需要使用for来读取,而且在DNNLinearCombinedRegressor和DNNLinearCombinedClassifier的输出内容是不一样的,需要自己打印出来看需要的是什么。
其他部分按照官方DEMO 来就行,还是给的挺好的。
最后预警一个TF的坑吧,也是很多人不用TF的一个重要原因,没事乱改借口,并且相同功能的函数有好几个,对之前版本的兼容性就更谈不上了,只能两个字回馈,任性!!!
在R1.3版本中,tf.contrib.learn.下的estimator很多都被remove了,在使用的时候会输出很多没用的log信息告诉你这玩意在哪个时间被移除了。所以推荐在使用的时候该用tf.estimator这个模块下的内容。官方github上的DEMO也是这个模块下的版本。强烈推荐!
Reference
https://github.com/tensorflow/tensorflow/blob/r1.3/tensorflow/examples/learn/wide_n_deep_tutorial.py
https://github.com/yufengg/widendeep/blob/master/trainer/task.py
[译] 简明 TensorFlow 教程 — 第二部分:混合学习
论文笔记 - Wide and Deep Learning for Recommender Systems
tensorflow学习笔记(六):TF.contrib.learn大杂烩
https://www.tensorflow.org/extend/estimators
tensorflow线性模型以及Wide deep learning
《Wide & Deep Learning for Recommender Systems 》笔记
http://blog.sina.com.cn/s/blog_61c463090102wjdc.html