http://www.csdn1 2 3.com/html/itweb/20130730/29422_29378_29408.htm
******************************
一、字符集与文字编码简介
1. 计算机如何显示文字
我们知道,计算机是以二进制的“形式”来保存和处理数据的,也 就是说,不管我们使用键盘进行输入,还是让计算机去读取一个文本文件,计算机得到的原始内容是一些二进制序列,当需要对这些二进制序列进行显示时,计算机 会依照某种“翻译机制”(也就是编码方式),取到这些二进制序列所表示的每个文字的“轮廓描述”(点阵或者矢量图),知道了轮廓,计算机便可以将二进制序 列所表示的实际的文字形状显示到屏幕上了,这里面的思想和用学号来表示一个学生是一样的。(当然,这里面具体的知识点会很多,相关知识可以参考《计算机图 形学》中显示原理的部分和其他与计算机显示原理相关的基础书籍)。
2. 字符集
将一些自然语言中的字符组成一个集合,并对集合中的每个字符制 定规范化的编码方式,这个字符的集合和规范化的编码方式就组成了一个字符集。如ASCII字符集里面包括了所有的英文字母,并且指定了这些英文字母的编码 规则。GB2312字符集里面包括了常用的简体汉字,并且指定了这些简体汉字的编码规则。
3. 字符编码
字符编码,就是建立一套自然语言中的“字符”跟计算机能够存储 处理的二进制数的映射的规则,即在一个字符集内,用一个特定的二进制数表示一个唯一“字符”,类似于学号跟学生的映射关系。为了保证统一性,兼容性,国际 上会对“字符”和“内码”的映射关系指定标准,这样就有了ASCII、Unicode等标准的编码方式,详细的编码方式请参考字符编码和其他相关资料。
二、泛意义上的编码和解码
1. 为什么需要编码
当数据不利于处理、存储的时候,就需要对它们进行编码。如对字符进行编码是因为自然语言中的字符不利于计算机处理和存储。对图片信息、视频信息、声音信息进行压缩、优化,将其“格式化”,是为了在保证媒体资源质量的同时,尽量的节省网络带宽和本地存储的空间。对URL进行编码,是为了避免URL解析发生歧义,简化解码方式,如:URL采用“&”作为不同参数的分隔符,假如某个特定的参数的名称或者值本身就包括分隔符“&”,如果不将参数中的“&”做编码转换,那势必会增加URL解析的复杂性,提高解析错误的概率。
2. 怎么样进行编码和解码
根据实际需求的差异,编码、解码算法有可能会很复杂,也有可能非常的简单,但是从根本上来讲,编码、解码只是在做翻译工作,将一种形式的数据翻译为另一种形式的数据,如,最简单的编码、解码就是相当于从一个Map中根据key查找value,然后使用value代替实际数据中的key的值。复杂一点儿的编码如javascript中的encodeURIComponent和decodeURIComponent,encodeURIComponent负责将字符串中不符合URL编码规范的字符转换为“%”形式的十六进制Unicode内码序列,decodeURIComponent负责将“%”形式的十六进制Unicode内码序列转换为实际的字符。
三、HTTP协议中的编码和解码
1. URL的编码和解码
首先,由于URL是采用ASCII字符集进行编码的,所以如果URL中含有非ASCII字符集中的字符,那就需要对其进行编码。再者,由于URL中好多字符是保留字,他们在URL中具有特殊的含义。如“&”表示参数分隔符,如果想要在URL中使用这些保留字,那就得对他们进行编码。
根据2005年发布的RFC3986“%编码”规范:对URL中属于ASCII字符集的非保留字不做编码;对URL中的保留字需要取其ASCII内码,然后加上“%”前缀将该字符进行替换(编码);对于URL中的非ASCII字符需要取其Unicode内码,然后加上“%”前缀将该字符进行替换(编码)。由于这种编码是采用“%”加上字符内码的方式,所以,有些地方也称其为“百分号编码”。
虽然“百分号编码”对URL的编码方式做了详细的规定,但是实践中,浏览器对于URL的编码方式还是存在一些差异(主要表现在对非ASCII字符编码的差异),接下来我们首先展示不同浏览器(chrome和IE)对URL编码
的差异性,然后再对这些差异性做一些客观的总结和分析。
1) 对URL中的非ASCII字符的编码,原始URL地址:http://test/wangfengpaopao/王丰,请求方式为直接在浏览器地址栏输入地址,发起请求。
a) chrome
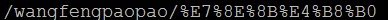
b) IE
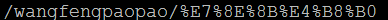
可以看出对于路径中的非ASCII字符,chrome和IE都是按照RFC3986“%编码”进行编码的,取的是非ASCII字符的Unicode内码。
2) 对URL参数中的非ASCII字符的编码,原始URL地址:http://test/wangfengpaopao/王丰?name=王丰,请求方式为直接在浏览器地址栏输入地址,发起请求。
a) chrome和IE11

b) IE11以下版本(使用gbk进行解码)

可以看出对于查询参数中的非ASCII字符,chrome及其IE11都是按照都是按照RFC3986“%编码”进行编码的,取的是非ASCII字符的Unicode内码。IE11以下版本直接发送的是非ASCII字符相对应的当前系统默认编码的内码。
3) 对表单字段name的值中的非ASCII字符的编码,请求地址:http://test/wangfengpaopao/王丰,请求方式为get。
a) Chrome
i. 页面gbk编码
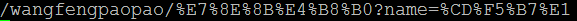
ii. 页面utf-8编码

b) IE
i. 页面gbk编码
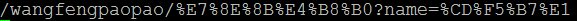
ii. 页面utf-8编码

可以看出当通过表单发送get请求时,对于表单字段内容中的非ASCII,chrome和IE都会采用当前页面的编码对其进行“百分号”编码。
4) 对表单字段name的值中的非ASCII字符的编码,请求地址:http://test/wangfengpaopao/王丰,请求方式为post,enctype为application/x-www-form-urlencoded。
a) chrome
i. 页面UTF-8编码

ii. 页面GBK编码
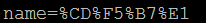
b) IE
i. 页面UTF-8编码

ii. 页面GBK编码
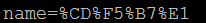
可以看出当通过表单发送post请求时,对于表单字段内容中的非ASCII,chrome和IE都会采用当前页面的编码对其进行“百分号”编码。
5) 对URL中的非ASCII字符的编码,原始URL地址:http://test/wangfengpaopao/王丰?name=王丰,请求方式为发起AJAX请求,method为get。
a) Chrome
i. 页面utf-8编码
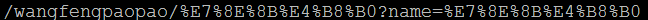
ii. 页面gbk编码

b) IE
i. 页面utf-8编码
1. IE6(gbk解码)
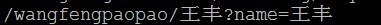
2. IE11
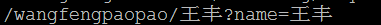
ii. 页面GBK编码
1. IE6(gbk解码)
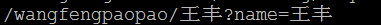
2. IE11

可以看出,对于URL中的非ASCII字符,ie6没有做任何的编码工作,而chrome和IE11则是按照用表单get请求的方式对URL进行编码的。
6) 对URL中的非ASCII字符的编码,原始URL地址:http://test/wangfengpaopao/王丰,请求方式为发起AJAX请求,method为post,数据位name=王丰,content-type为application/x-www-form-urlencoded。
a) Chrome
i. 页面utf-8编码

ii. 页面gbk编码
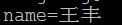
b) IE
i. 页面utf-8编码
1. IE6
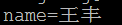
2. IE11
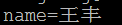
ii. 页面GBK编码
1. IE6
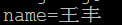
2. IE11

可以看出,对于使用post发送并且content-type为application/x-www-form-urlencoded的请求,各个浏览器都没有对数据进行“百分号”编码。
从上面的实验结果我们看得出:
① 对于URL中的路径部分,IE和chrome都会统一采用utf-8编码对URL中的非ASCII字符进行百分号编码。
② 对于新开页面,IE11以下版本不会对URL中的参数部分做编码,chrome和IE11会采用utf-8编码对URL中的非ASCII字符进行百分号编码。
③ 对于通过表单发起的请求(不管是post还是get方式),IE和chrome都会采用当前页面的默认编码对URL参数中的非ASCII字符进行百分号编码。
④ 对于AJAX通过get方式发起的请求,IE11和chrome会根据当前页面的默认编码对URL参数中的非ASCII字符进行百分号编码。而IE6不会对URL非ASCII表示的路径信息和参数信息进行编码。
⑤ 对于AJAX通过post方式发起的请求,即便设定了application/x-www-form-urlencoded头信息,浏览器也不会对数据做任何的编码(或者说浏览器不把发送的数据当做URL的一部分)。
不同的浏览器在不同情况下处理URL中非ASCII字符的编码方式可谓是千差万别,好在浏览器对表单数据的编码处理是一致的,即:对URL路径中的非ASCII字符采用UTF-8字符集进行百分号编码;对中的表单数据(包括post时enctype为application/x-www-form-urlencoded),采用页面默认的编码字符集进行百分号编码。
对于AJAX发起请求时URL编码的差异性,我们可以对URL或者数据中的非ASCII字符使用javascript的encodeURIComponent进行编码,统一编码方式,简化服务器解码的复杂度。
2. 浏览器对不同媒体资源类型(mime-type)的“资源”的解码
1) 与资源类型和编码类型相关的HTTP头信息。
a) 浏览器request时携带的头信息

b) 服务器response时携带的头信息

当通过浏览器发起一个资源请求,浏览器会携带Accept头信息,标识浏览器需要的mime-type,并且指定浏览器对不同mime-type的喜好系数q,同时浏览器也会发送Accept-Charset头信息,标识浏览器字符集解码类型。
当服务器返回“符合”浏览器需求的资源时,服务器也会携带Content-Type头信息,标识返回资源的媒体类型和编码方式。
2) 浏览器对不同媒体资源类型的资源的解析过程
不管怎样,浏览器发起一个请求时所携带的mime-type信息只是对服务器返回资源的一种“期望”,资源本身的mime-type还得用服务器应答时携带的mime-type信息进行表示。
笼统的讲,对于文本类型的数据(html/css/js/xml等),浏览器首先会根据资源的Charset,将文本流的编码转换为与资源的mime-type相对应的解码器处理数据时所使用的编码,比如对于javascript文件,如果文本流本身 是GBK编码的,那就得首先转为Unicode编码,然后再交给javascript引擎去解析执行。当然对于不同类型的资源,浏览器进行解码的流程也是不一样的,下面会用流程图较详细的说明下浏览器对于HTML、CSS、Javascript的通用的解码步骤。
① 浏览器对于HTML文档的解码流程

② 浏览器对于CSS/JS文档的解码流程

3) AJAX请求中,浏览器对“数据”的解码流程
AJAX请求跟页面内的有资源属性source的标签发起的请求有所不同,从本质来说,AJAX请求得到的数据,浏览器都认为它是普通的文本流,跟具体的mime-type无关,即便是responseXML这样的数据,它也是由浏览器对responseText进行了XML解析,这与使用javascript对responseText进行XML解析的道理是一样的。
AJAX解码的流程
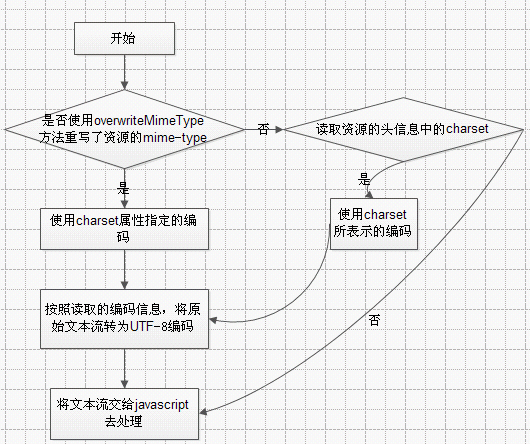
3. 服务器对资源的编码和解码
弄清了编码和解码的原理以及浏览器的编解码流程,服务器的编码和解码可说的已经不多了,将来兵挡,水来土掩而已。要说的是为了避免URL解码时的各种兼容性问题,最好有统一的规范,比如通过接口提交的数据中的非ASCII字符都是用encodeURIComponent进行URL编码。为了避免浏览器对资源进行解码的兼容性,服务器返回资源时,明确正确的指定Charset信息也是很重要的。
除了熟练使用自己所擅长的编程语言以及相对应的框架提供的编解码相关的方法外,可以参考iconv了解具体的编码转换原理,参考UCharsetDetector了解字符集探测原理。