简介
Prometheus是SoundCloud公司开发的一站式监控告警平台,依赖少,功能齐全。
于2016年加入CNCF,广泛用于 Kubernetes集群的监控系统中,2018.8月成为继K8S之后第二个毕业的项目。Prometheus作为CNCF生态圈中的重要一员,其活跃度仅次于 Kubernetes。
关键功能包括:
- 多维数据模型:metric,labels
- 灵活的查询语言:PromQL, 在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
- 可独立部署,拆箱即用,不依赖分布式存储
- 通过Http pull的采集方式
- 通过push gateway来做push方式的兼容
- 通过静态配置或服务发现获取监控项
- 支持图表和dashboard等多种方式
核心组件:
- Prometheus Server: 采集和存储时序数据
- client库: 用于对接 Prometheus Server, 可以查询和上报数据
- push gateway处理短暂任务:用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等
- 定制化的exporters,比如:HAProxy, StatsD,Graphite等等, 汇报机器数据的插件
- 告警管理:Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager
- 多种多样的支持工具
优势和劣势:
- 同InfluxDB相比, 在场景方面:PTSDB 适合数值型的时序数据。不适合日志型时序数据和用于计费的指标统计。InfluxDB面向的是通用时序平台,包括日志监控等场景。而Prometheus更侧重于指标方案。两个系统之间有非常多的相似之处,包括采集,存储,报警,展示等等
- Influxdata的组合有:telegraf+Influxdb+Kapacitor+Chronograf
- Promethues的组合有:exporter+prometheus server+AlertManager+Grafana
- 采集端prometheus主推拉的模式,同时通过push gateway支持推的模式。influxdata的采集工具telegraf则主打推的方式。
- 存储方面二者在基本思想上相通,关键点上有差异包括:时间线的索引,乱序的处理等等。
- 数据模型上Influxdb支持多值模型,String类型等,更丰富一些。
- Kapacitor 是一个混合了 prometheus 的数据处理,存储规则,报警规则以及告警通知功能的工具.而AlertManager进一步提供了分组,去重等等。
- influxdb之前提供的cluster模式被移除了,现在只保留了基于relay的高可用,集群模式作为商业版本的特性发布。prometheus提供了一种很有特色的cluster模式,通过多层次的proxy来聚合多个prometheus节点实现扩展。
同时开放了remote storage,因此二者又相互融合,Influxdb作为prometheus的远端存储。
- OpenTSDB 的数据模型与Prometheus几乎相同,查询语言上PromQL更简洁,OpenTSDB功能更丰富。OpenTSDB依赖的是Hadoop生态,Prometheus成长于Kubernetes生态。
数据模型
- 采用单值模型, 数据模型的核心概念是metric,labels和samples.
- 格式:<metric name>{<label name>=<label value>, …}
- 例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
- metric的命名具有业务含义,比如http_request_total.
- 指标的类型分为:Counter, Gauge,Historgram,Summary
- labels用于表示维度.Samples由时间戳和数值组成。
- jobs and instances
- Prometheus 会自动生成target和instances作为标签
- job: api-server
- instance 1: 1.2.3.4:5670
- instance 2: 1.2.3.4:5671
- job: api-server
- Prometheus 会自动生成target和instances作为标签
整体设计思路
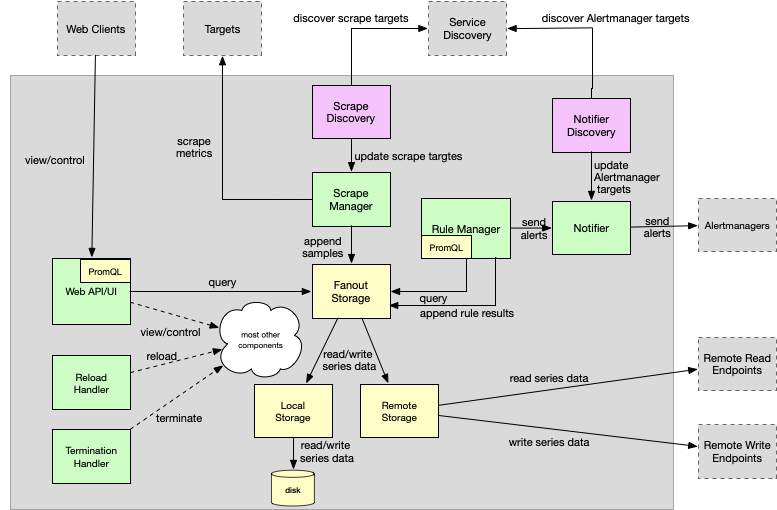
Prometheus的整体技术架构可以分为几个重要模块:
- Main function:作为入口承担着各个组件的启动,连接,管理。以Actor-Like的模式协调组件的运行
- Configuration:配置项的解析,验证,加载
- Scrape discovery manager:服务发现管理器同抓取服务器通过同步channel通信,当配置改变时需要重启服务生效。
- Scrape manager:抓取指标并发送到存储组件
- Storage:
- Fanout Storage:存储的代理抽象层,屏蔽底层local storage和remote storage细节,samples向下双写,合并读取。
- Remote Storage:Remote Storage创建了一个Queue管理器,基于负载轮流发送,读取客户端merge来自远端的数据。
- Local Storage:基于本地磁盘的轻量级时序数据库。
- PromQL engine:查询表达式解析为抽象语法树和可执行查询,以Lazy Load的方式加载数据。
- Rule manager:告警规则管理
- Notifier:通知派发管理器
- Notifier discovery:通知服务发现
- Web UI and API:内嵌的管控界面,可运行查询表达式解析,结果展示。
PTSDB概述
本文侧重于Local Storage PTSDB的解析. PTSDB的核心包括:倒排索引+窗口存储Block。
数据的写入按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个Head Block中,每一个块中包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
最新写入数据保存在内存block中, 2小时后写入磁盘。后台线程把2小时的数据最终合并成更大的数据块,一般的数据库在固定一个内存大小后,系统的写入和读取性能会受限于这个配置的内存大小。而PTSDB的内存大小是由最小时间周期,采集周期以及时间线数量来决定的。
为防止内存数据丢失,实现wal机制。删除记录在独立的tombstone文件中。
核心数据结构和存储格式
PTSDB的核心数据结构是HeadAppender,Appender commit时wal日志编码落盘,同时写入head block中。

PTSDB本地存储使用自定义的文件结构。主要包含:WAL,元数据文件,索引,chunks,tombstones
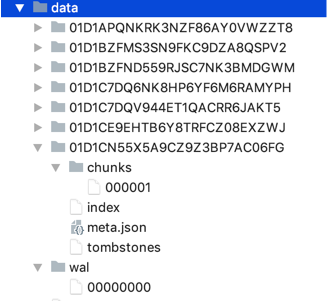
Write Ahead Log
WAL 有3种编码格式:时间线,数据点,以及删除点。总体策略是基于文件大小滚动,并且根据最小内存时间执行清除。
- 当日志写入时,以segment为单位存储,每个segment默认128M, 记录数大小达到32KB页时刷新一次。当剩余空间小于新的记录数大小时,创建新的Segment。
- 当compation时WAL基于时间执行清除策略,小于内存中block的最小时间的wal日志会被删除。
- 重启时,首先打开最新的Segment,从日志中恢复加载数据到内存。
元数据文件
meta.json文件记录了Chunks的具体信息, 比如新的compactin chunk来自哪几个小的chunk。 这个chunk的统计信息,比如:最小最大时间范围,时间线,数据点个数等等
compaction线程根据统计信息判断该blocks是否可以做compact:(maxTime-minTime)占整体压缩时间范围的50%, 删除的时间线数量占总体数量的5%。

索引
索引一部分先写入Head Block中,随着compaction的触发落盘。
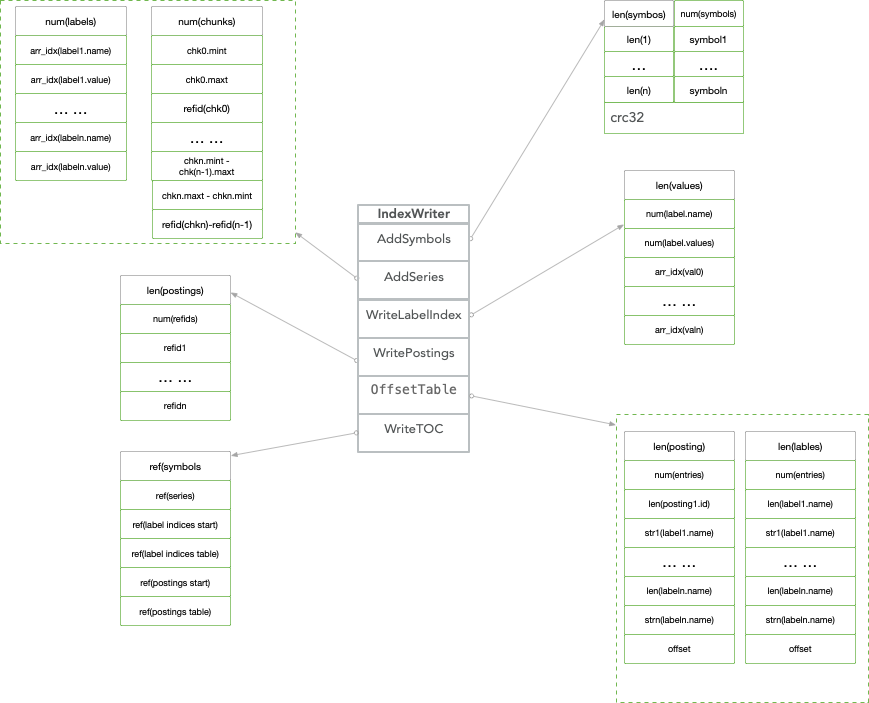
索引采用的是倒排的方式,posting list里面的id是局部自增的,作为reference id表示时间线。索引compact时分为6步完成索引的落盘:Symbols->Series->LabelIndex->Posting->OffsetTable->TOC
- Symbols存储的是tagk, tagv按照字母序递增的字符串表。比如__name__,go_gc_duration_seconds, instance, localhost:9090等等。字符串按照utf8统一编码。
- Series存储了两部分信息,一部分是标签键值对的符号表引用;另外一部分是时间线到数据文件的索引,按照时间窗口切割存储数据块记录的具体位置信息,因此在查询时可以快速跳过大量非查询窗口的记录数据,
为了节省空间,时间戳范围和数据块的位置信息的存储采用差值编码。 - LabelIndex存储标签键以及每一个标签键对应的所有标签值,当然具体存储的数据也是符号表里面的引用值。
- Posting存储倒排的每个label对所对应的posting refid
- OffsetTable加速查找做的一层映射,将这部分数据加载到内存。OffsetTable主要关联了LabelIndex和Posting数据块。TOC是各个数据块部分的位置偏移量,如果没有数据就可以跳过查找。
Chunks
数据点存放在chunks目录下,每个data默认512M,数据的编码方式支持XOR,chunk按照refid来索引,refid由segmentid和文件内部偏移量两个部分组成。

Tombstones
记录删除通过mark的方式,数据的物理清除发生在compaction和reload的时候。以时间窗口为单位存储被删除记录的信息。

查询PromQL
Promethues的查询语言是PromQL,语法解析AST,执行计划和数据聚合是由PromQL完成,fanout模块会向本地和远端同时下发查询数据,PTSDB负责本地数据的检索。
PTSDB实现了定义的Adpator,包括Select, LabelNames, LabelValues和Querier.
PromQL定义了三类查询:
瞬时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:http_requests_total
区间数据 (Range vector): 包含一组时序,每个时序有多个点,例:http_requests_total[5m]
纯量数据 (Scalar): 纯量只有一个数字,没有时序,例如:count(http_requests_total)
一些典型的查询包括:
- 查询当前所有数据
http_requests_total
select * from http_requests_total where timestamp between xxxx and xxxx - 条件查询
http_requests_total{code="200", handler="query"}
select * from http_requests_total where code="200" and handler="query" and timestamp between xxxx and xxxx - 模糊查询: code 为 2xx 的数据
http_requests_total{code~="20"}
select * from http_requests_total where code like "%20%" and timestamp between xxxx and xxxx - 值过滤: value大于100
http_requests_total > 100
select * from http_requests_total where value > 100 and timestamp between xxxx and xxxx - 范围区间查询: 过去 5 分钟数据
http_requests_total[5m]
select * from http_requests_total where timestamp between xxxx-5m and xxxx - count 查询: 统计当前记录总数
count(http_requests_total)
select count(*) from http_requests_total where timestamp between xxxx and xxxx - sum 查询:统计当前数据总值
sum(http_requests_total)
select sum(value) from http_requests_total where timestamp between xxxx and xxxx - top 查询: 查询最靠前的 3 个值
topk(3, http_requests_total)
select * from http_requests_total where timestamp between xxxx and xxxx order by value desc limit 3 - irate查询:速率查询
irate(http_requests_total[5m])
select code, handler, instance, job, method, sum(value)/300 AS value from http_requests_total where timestamp between xxxx and xxxx group by code, handler, instance, job, method;
PTSDB关键技术点
乱序处理
PTSDB对于乱序的处理采用了最小时间窗口的方式,指定合法的最小时间戳,小于这一时间戳的数据会丢弃不再处理。
合法最小时间戳取决于当前head block里面最早的时间戳和可存储的chunk范围。
这种对于数据行为的限定极大的简化了设计的灵活性,对于compaction的高效处理以及数据完整性提供了基础。
内存的管理
使用mmap读取压缩合并后的大文件(不占用太多句柄),
建立进程虚拟地址和文件偏移的映射关系,只有在查询读取对应的位置时才将数据真正读到物理内存。
绕过文件系统page cache,减少了一次数据拷贝。
查询结束后,对应内存由Linux系统根据内存压力情况自动进行回收,在回收之前可用于下一次查询命中。
因此使用mmap自动管理查询所需的的内存缓存,具有管理简单,处理高效的优势。
Compaction
Compaction主要操作包括合并block、删除过期数据、重构chunk数据。
- 合并多个block成为更大的block,可以有效减少block个,当查询覆盖的时间范围较长时,避免需要合并很多block的查询结果。
- 为提高删除效率,删除时序数据时,会记录删除的位置,只有block所有数据都需要删除时,才将block整个目录删除。
- block合并的大小也需要进行限制,避免保留了过多已删除空间(额外的空间占用)。
比较好的方法是根据数据保留时长,按百分比(如10%)计算block的最大时长, 当block的最小和最大时长超过2/3blok范围时,执行compaction
快照
PTSDB提供了快照备份数据的功能,用户通过admin/snapshot协议可以生成快照,快照数据存储于data/snapshots/-目录。
PTSDB最佳实践
- 在一般情况下,Prometheus中存储的每一个样本大概占用1-2字节大小。如果需要对Prometheus Server的本地磁盘空间做容量规划时,可以通过以下公式计算:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample - 保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,
只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。
因此有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。
考虑到Prometheus会对时间序列进行压缩,因此减少时间序列的数量效果更明显。 - PTSDB的限制在于集群和复制。因此当一个node宕机时,会导致一定窗口的数据丢失。
当然,如果业务要求的数据可靠性不是特别苛刻,本地盘也可以存储几年的持久化数据。
当PTSDB Corruption时,可以通过移除磁盘目录或者某个时间窗口的目录恢复。 - PTSDB的高可用,集群和历史数据的保存可以借助于外部解决方案,不在本文讨论范围。
- 历史方案的局限性,PTSDB在早期采用的是单条时间线一个文件的存储方式。这中方案有非常多的弊端,比如:
Snapshot的刷盘压力:定期清理文件的负担;低基数和长周期查询查询,需要打开大量文件;时间线膨胀可能导致inode耗尽。
PTSDB面临的挑战
在使用过程中,PTSDB也在某些方面遇到了一些问题,比如;
- Compaction对于IO, CPU, 以及Memory的影响
- 冷启动后,预热阶段CPU和内存占用会上升
- 在高速写入时会出现CPU的Spike等等
总结
PTSDB 作为K8S监控方案里面存储时序数据的实施标准,其在时序届影响力和热度都在逐步上升。Alibaba TSDB目前已经支持通过Adapter的方式作为其remote storage的方案。
原文链接
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight