PAI-STUDIO在支持OSS数据源的基础上,增加了对MaxCompute表的数据支持。用户可以直接使用PAI-STUDIO的Tensorflow组件读写MaxCompute数据,本教程将提供完整数据和代码供大家测试。
详细流程
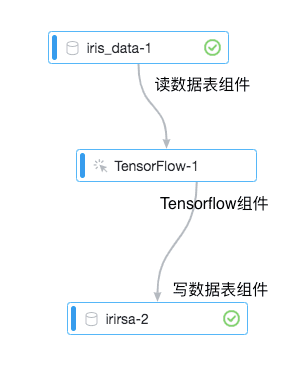
为了方便用户快速上手,本文档将以训练iris数据集为例,介绍如何跑通实验。
1.读数据表组件
为了方便大家,我们提供了一份公共读的数据供大家测试,只要拖出读数据表组件,输入:
pai_online_project.iris_data
即可获取数据,
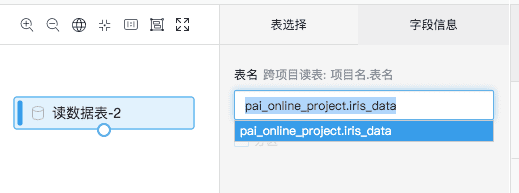
数据格式如图:

2.Tensorflow组件说明
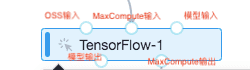
3个输入桩从左到右分别是OSS输入、MaxCompute输入、模型输入。2个输出桩分别是模型输出、MaxCompute输出。如果输入是一个MaxCompute表,输出也是一个MaxCompute表,需要按下图方法连接。
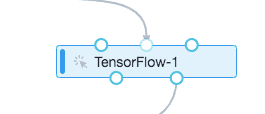
读写MaxCompute表需要配置数据源、代码文件、输出模型路径、建表等操作。
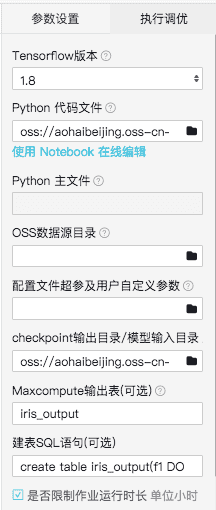
- Python代码文件:需要把执行代码放到OSS路径下(注意OSS需要与当前项目在同一区域),本文提供的代码可以在下方连接下载(代码需要按照下方代码说明文案调整):http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/129749/cn_zh/1565333220966/iristest.py?spm=a2c4g.11186623.2.10.50c46b36PlNwcq&file=iristest.py
- Checkpoint输出目录/模型输入目录:选择自己的OSS路径用来存放模型
- MaxCompute输出表:写MaxCompute表要求输出表是已经存在的表,并且输出的表名需要跟代码中的输出表名一致。在本案例中需要填写“iris_output”
- 建表SQL语句:如果代码中的输出表并不存在,可以通过这个输入框输入建表语句自动建表。本案例中建表语句“create table iris_output(f1 DOUBLE,f2 DOUBLE,f3 DOUBLE,f4 DOUBLE,f5 STRING);”
组件PAI命令
PAI -name tensorflow180_ext -project algo_public -Doutputs="odps://${当前项目名}/tables/${输出表名}" -DossHost="${OSS的host}" -Dtables="odps://${当前项目名}/tables/${输入表名}" -DgpuRequired="${GPU卡数}" -Darn="${OSS访问RoleARN}" -Dscript="${执行的代码文件}";上述命令中的${}需要替换成用户真实数据
3.代码说明
import tensorflow as tf
tf.app.flags.DEFINE_string("tables", "", "tables info")
FLAGS = tf.app.flags.FLAGS
print("tables:" + FLAGS.tables)
tables = [FLAGS.tables]
filename_queue = tf.train.string_input_producer(tables, num_epochs=1)
reader = tf.TableRecordReader()
key, value = reader.read(filename_queue)
record_defaults = [[1.0], [1.0], [1.0], [1.0], ["Iris-virginica"]]
col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults = record_defaults)
# line 9 and 10 can be written like below for short. It will be helpful when too many columns exist.
# record_defaults = [[1.0]] * 4 + [["Iris-virginica"]]
# value_list = tf.decode_csv(value, record_defaults = record_defaults)
writer = tf.TableRecordWriter("odps://pai_bj_test2/tables/iris_output")
write_to_table = writer.write([0, 1, 2, 3, 4], [col1, col2, col3, col4, col5])
# line 16 can be written like below for short. It will be helpful when too many columns exist.
# write_to_table = writer.write(range(5), value_list)
close_table = writer.close()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
sess.run(tf.local_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
step = 0
while not coord.should_stop():
step += 1
sess.run(write_to_table)
except tf.errors.OutOfRangeError:
print('%d records copied' % step)
finally:
sess.run(close_table)
coord.request_stop()
coord.join(threads)- 读数据表
tables = [FLAGS.tables]
filename_queue = tf.train.string_input_producer(tables, num_epochs=1)
reader = tf.TableRecordReader()
key, value = reader.read(filename_queue)
record_defaults = [[1.0], [1.0], [1.0], [1.0], ["Iris-virginica"]]
其中FLAGS.tables是前端配置的输入表名的传参变量,对应组件的MaxCompute输入桩:

- 写数据表
writer = tf.TableRecordWriter("odps://pai_bj_test2/tables/iris_output")
write_to_table = writer.write([0, 1, 2, 3, 4], [col1, col2, col3, col4, col5])
TableRecordWriter中的格式为odps://当前项目名/tables/输出表名
本文作者:傲海
本文为云栖社区原创内容,未经允许不得转载。