业务数据存储是业务系统最基本的构成,构建数据中台,就是要将这些数据集中起来放到一个有更强算力的地方集中处理,所以对于数据集成的能力是构建数据中台最基本要求;
从存储的发展历程来看,由于不同的业务场景需求,带来了数据存储的不同发展路径,在企业发展中随着业务规模的变化,也会选择不同的存储来支撑,所以每个企业一定会存在异构存储,如何将多源异构存储中的数据集成起来是企业做数据中台需要面临的一个巨大问题;
当然,目前行业内有很多人采用一些开源技术组件来实现,比如GitHub上的DataX、HData等,但是由于技术组件的易用性较弱,对于分析师和模型师而言,学习效率和使用便捷度还有待提高;因此集中式、界面化的工具尤为重要;
不久前我们就接触过一个客户,他们是一家有着大概十多年发展历史的零售企业,有线上渠道也有线下自营店,企业发展一直都比较重视信息化,所以基于Oracle的ERP系统、基于MySQL的APP应用、基于ES的搜索系统、基于HBase的数据服务系统,还有第三提供的POS服务,每月同步账单;经年累月,系统变得比较复杂,而且没有当下流行的业务中台架构;
在和客户的业务方、IT部门沟通过程中了解到,目前最首要的需求是希望可以把这些数据统一管理起来,并且在业务上能够发挥一些价值。基于客户诉求和基础信息的了解,目前虽然远期的蓝图不是很清楚,但是短期内对于数据建设的方向是明确的,先完成数据的集成工作,然后再挖掘数据业务价值,当然集成的数据内容要与业务价值考量关联,否则盲目集成,也只是转存了一份数据而已;
基于这些判断,系统梳理了下客户的系统以及使用的存储;
梳理结果如下:

整体IT信息如下:
信息系统:六大模块(前端业务APP、营销工具、运营平台、供应链平台、内部管理平台、OA系统)
存储类型:
关系型数据库:MySQL、Oracle、PostgreSQL
无结构数据存储:FTP、日志文件、ElasticSearch、线下CSV(Excel文件)
NoSQL存储:HBase
集成目标:
MaxCompute(已采购)
集成工具
公共云Dataphin
根据对系统存储和工具的梳理,数据流形式如下:
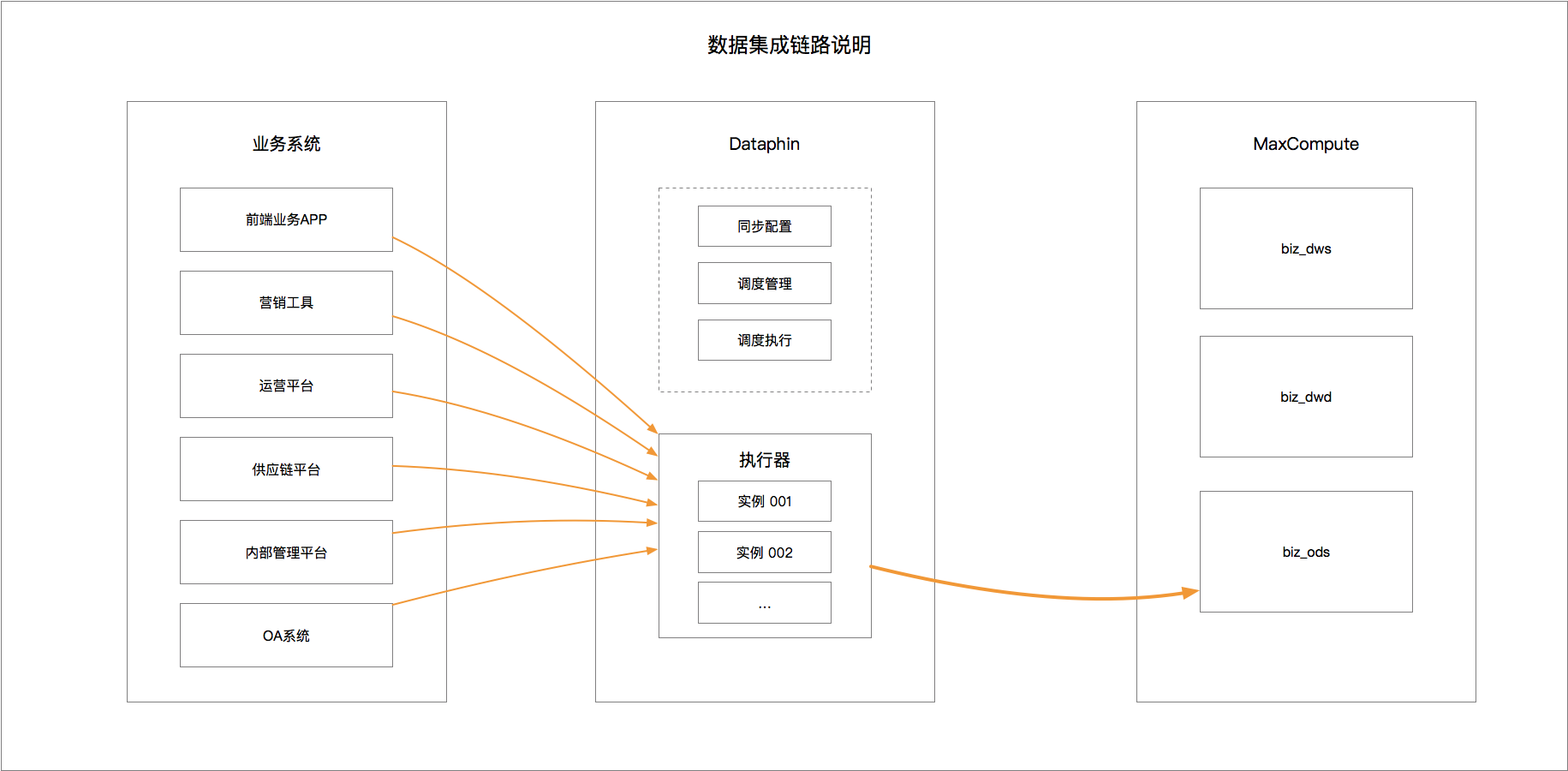
在整个集成数据流设计中,主要使用的是Dataphin产品,目前存储数据梳理中用到的类型都可以支撑到,更重要是界面化操作,入门门槛比较低,维护和管理起来比较简单,配置下数据源,设置下数据从来源到目标的mapping关系即可。
Step 1. 新建数据源

Step 2. 配置映射关系

Step 3. 发布生产环境
这样一个数据同步任务就创建好,客户这边大概有12个存储源约200个数据表做上云,大概2天的时间就完成了,因此,工具还是很重要的!
我们在项目中所使用的数据集成产品Dataphin就是一个非常方便的工具。
Dataphin数据同步支撑了数据上云最基础的能力,只有数据上云才有可能谈论数据中台建设和数字化转型;
Dataphin数据同步定位于数据上云的管道,集成多源异构存储中的数据,构建数据中台建设的基础原料;在数据同步的设计中,首先将多类型存储介质的元数据进行了标准化,基于这种标准化实现了前端配置的一致体验,避免填写大量的JSON文件进行同步配置的定义,简化配置操作,以提升工程师开发阶段的体验;同时,兼顾客户最终价值需求,即数据能够稳定、高效地完成传输,实现上云,因此数据同步设计的过程中也是非常关注数据同步的性能指标;
目前我们已经实现12种来源存储类型以及14种目标存储类型的支持;覆盖了当前客户使用的大多数数据源类型;同时,由于采用插件式的设计方法,对于异构数据源提供了快速扩展的能力;
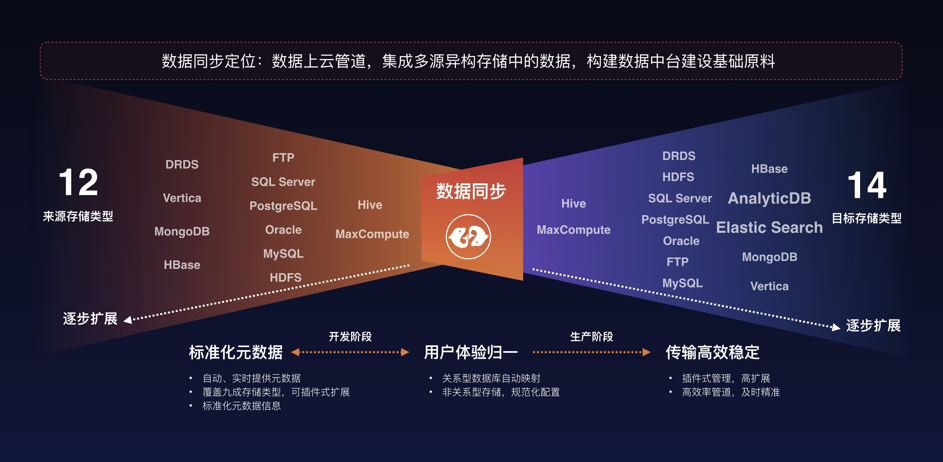
按照存储类型划分,保持与DataX定义的标准一致:
- RDBMS关系型数据库
- MySQL
- SQL Server
- Oracle
- PostgreSQL
- DRDS
- Vertica
- 协议支持DB
- 数仓数据存储
- AnalyticDB(只写)
- ODPS
- Hive
- NoSQL存储
- MongoDB
- HBase
- 无结构化数据存储
- HDFS
- FTP
- ElasticSearch(只写)
Dataphin数据同步提供了强大的数据传输能力,帮助企业数据高效上云,打破数据孤岛,构建数据中台!
本文作者:王腾
本文为云栖社区原创内容,未经允许不得转载。