1、获取所有的span标签
from lxml import etree parser=etree.HTMLParser(encoding='utf-8') html=etree.parse("tencent.html",parser=parser) # 1、获取所有的span标签 # //span # xpath返回的是一个列表 spans=html.xpath("//span") for span in spans: print(etree.tostring(span, encoding='utf-8').decode('utf-8'))
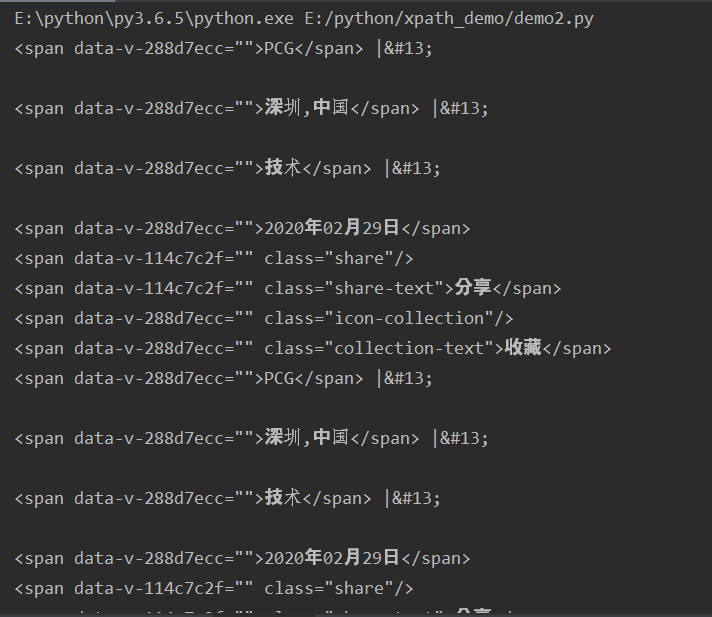
2、获取第二个span标签
# 2、获取第二个span标签 # //span[2] spans=html.xpath("//span[2]") for span in spans: print(etree.tostring(span,encoding='utf-8').decode('utf-8'))

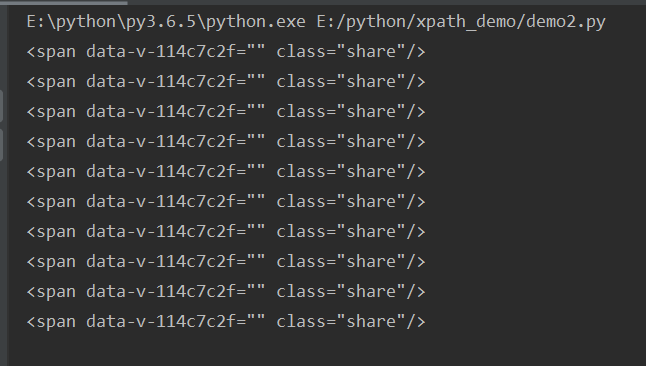
3、获得class等于share的span标签
# 3、获得class等于share的span标签 # //span[@class="share"] spans=html.xpath("//span[@class='share']") for span in spans: print(etree.tostring(span,encoding='utf-8').decode('utf-8'))
结果为列表的形式:
4、获取所有div标签下,id的值
# 4、获取所有div标签下,id的值 # //div/@id # 因为id的值就是字符串形式,所有就不用tostring了 divs=html.xpath("//div/@id") for div in divs: print(div)

5、获取html里面的纯文本
# 5、获取html里面的纯文本
# 一般不要第一个span,因为第一个span一般为标题,从第二个span开始,先获取第二个span得纯文本,然后把第二个span里面得数据组装成一个字典,然后把这些字典放入列表
divs=html.xpath("//div/div/div/div")
positions=[]
for div in divs:
try:
title=div.xpath(".//h4/text()")[0]
address=div.xpath(".//span[3]/text()")[0]
jishu=div.xpath(".//span[5]/text()")[0]
time=div.xpath(".//span[9]/text()")[0]
recruittext=div.xpath(".//p[2]/text()")[0]
# print(address)
position={
'title':title,
'address':address,
'jishu':jishu,
'time':time,
'recruittext':recruittext
}
positions.append(position)
print(positions)
except IndexError:
pass
结果:
