| 作业要求 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 课程的目标 | 学会结对编程,完成简单软件功能的开发,会对简单代码进行审核,学会两人一起合作,会对代码进行单元测试等,分析代码的利用率 |
| 此作业在具体方面帮我实现目标 | 和队友搭档完成程序开发,进行代码复审,简单修改代码挺高代码利用率,学会用新的语言进行编程 |
| 其他参考文献 | https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html https://www.cnblogs.com/lsdb/p/9201029.html https://blog.csdn.net/fly_egg/article/details/85050346 |
| 作业正文 | https://i-beta.cnblogs.com/posts/edit;postId=12620402 |
作业1
评价链接
1.https://www.cnblogs.com/kaka123456/p/12442520.html

2.https://www.cnblogs.com/limin123/p/12455500.html

3.https://www.cnblogs.com/wanghuiru/p/12460279.html

4.https://www.cnblogs.com/zxy123456/p/12449427.html

5.https://www.cnblogs.com/wanghuiru/p/12397287.html

6.https://www.cnblogs.com/zxy123456/p/12366171.html

7.https://www.cnblogs.com/limin123/p/12377468.html

8.https://www.cnblogs.com/liziye/p/12372753.html

总体看法
通过对其他同学代码的评价以及看完其他同学对自己代码的评价之后,觉得自己写的有很多的不足之处,比如说有的代码未按老师要求实现具体的功能,也没有用markdown编辑器将其框起来,显得非常的乱,可读性不是很好,以后要改正这些方面的缺点,使自己的代码更加规范。
作业2 结对编程
具体要求
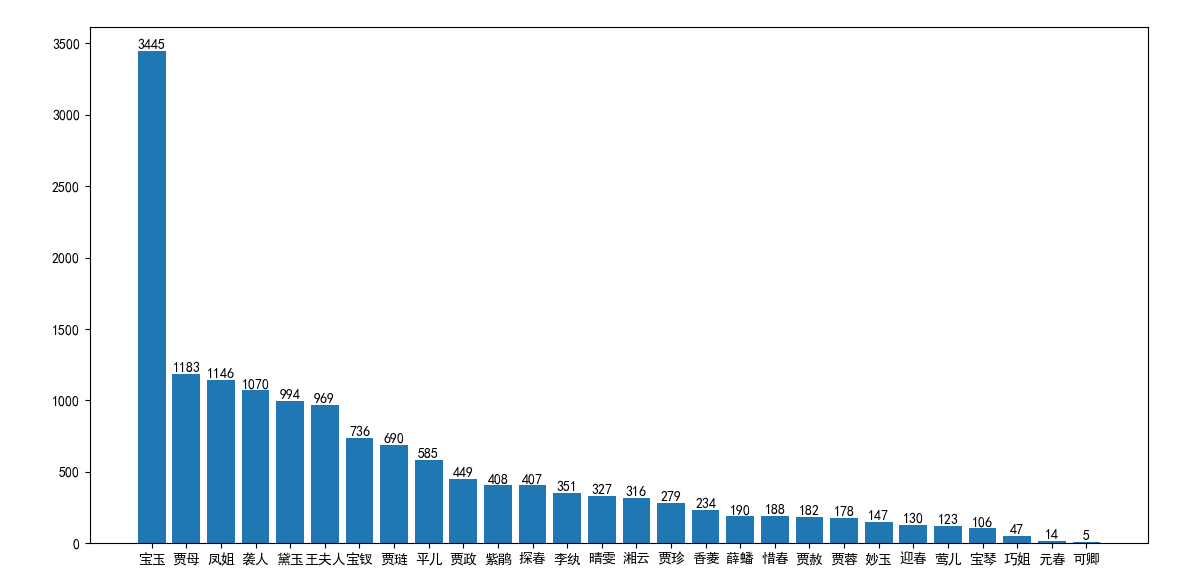
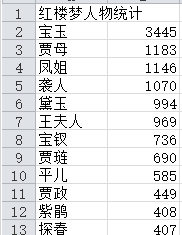
1.实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
2.进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
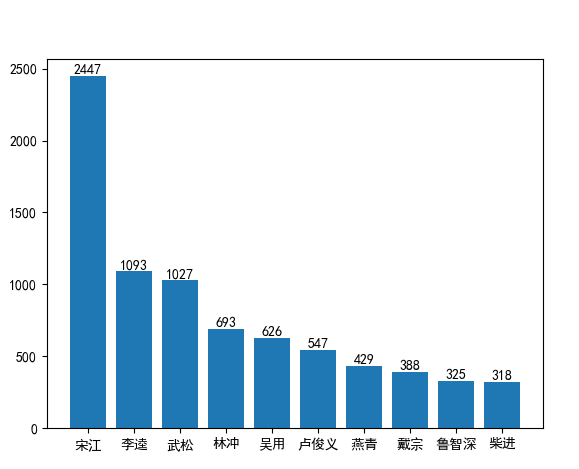
3.针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
4.将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
运行界面

《红楼梦》人物出场次数统计

csv格式输出统计
运行界面

《水浒传》人物出场次数统计
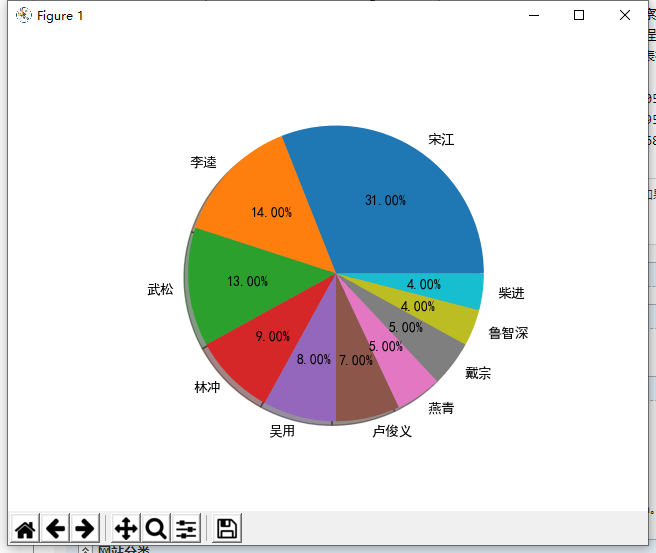
csv格式输出统计

各个模块安装界面




实验总结
本次实验因为学过的c++语言和Java语言无法高效率的统计中文出现字数,所以我转而进行了Python的下载和使用,但是一开始遇到了很多的问题,比如说缺少各种模块,导致结果运行不出来,最后在百度以及同学的帮助下顺利实现了这个代码。对于两人结对编程而言,刚开始还不太习惯,但是慢慢地到了后来各自分工明确,效率也逐渐提高了。
未解决的问题:因为刚开始学习Python语言,还未真正的学懂,所以也没有实现分章节统计《红楼梦》和《水浒传》里人物出场的次数,以后还会陆续改进。
附录
# coding=utf-8
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
# 此函数用于绘制条形图
def showNameBar(self,name_list_sort,name_list_count):
#条形数量
x = np.arange(len(name_list_sort))
#此语句用来处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
#绘制条形图
bars = plt.bar(x,name_list_count)
#给每个条形起名
plt.xticks(x,name_list_sort)
#显示条形具体的数量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
#画图
plt.show()
# 此函数用于绘制饼状图
def showNamePie(self, name_list_sort, name_list_fracs):
#此语句用来处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制饼状图
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
#画图
plt.show()
def getNameTimesSort(self,name_list,txt_path):
# 将所有人名临时添加到jieba所用字典,以使jieba能识别所有人名
for k in name_list:
jieba.add_word(k)
# 打开并读取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分词
jieba_cut = jieba.cut(file_obj)
# Counter重新组装以方便读取
book_counter = Counter(jieba_cut)
# 人名列表,因为要处理凤姐所以不直接用name_lis
name_dict ={}
# 人名出现的总次数,用于后边计算百分比
name_total_count = 0
for k in name_list:
if k == '熙凤':
# 将熙凤出现的次数合并到凤姐
name_dict['凤姐'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新组装以使用most_common排序
name_counter = Counter(name_dict)
# 按出现次数排序后的人名列表
name_list_sort = []
name_list_fracs = []
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
# print(k+':'+str(v))
# 绘制条形图
self.showNameBar(name_list_sort, name_list_count)
# 绘制条形图
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
# 参与统计的人名列表
name_list = ['宝玉', '黛玉', '宝钗', '元春', '探春', '湘云', '妙玉', '迎春', '惜春', '凤姐', '熙凤', '巧姐', '李纨', '可卿', '贾母', '贾珍', '贾蓉', '贾赦', '贾政', '王夫人', '贾琏', '薛蟠', '香菱', '宝琴', '袭人', '晴雯', '平儿', '紫鹃', '莺儿']
# 红楼梦txt文件所在路径
txt_path = 'F:红楼梦.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)
# coding=utf-8
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
# 此函数用于绘制条形图
def showNameBar(self,name_list_sort,name_list_count):
# x代表条形数量
x = np.arange(len(name_list_sort))
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制条形图,bars相当于句柄
bars = plt.bar(x,name_list_count)
# 给各条形打上标签
plt.xticks(x,name_list_sort)
# 显示各条形具体数量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
# 显示图形
plt.show()
# 此函数用于绘制饼状图
def showNamePie(self, name_list_sort, name_list_fracs):
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制饼状图
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
# 显示图形
plt.show()
def getNameTimesSort(self,name_list,txt_path):
# 将所有人名临时添加到jieba所用字典,以使jieba能识别所有人名
for k in name_list:
jieba.add_word(k)
# 打开并读取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分词
jieba_cut = jieba.cut(file_obj)
# Counter重新组装以方便读取
book_counter = Counter(jieba_cut)
# 人名列表,因为要处理李逵所以不直接用name_list
name_dict ={}
# 人名出现的总次数,用于后边计算百分比
name_total_count = 0
for k in name_list:
if k == '黑旋风':
# 将黑旋风出现的次数合并到李逵
name_dict['李逵'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新组装以使用most_common排序
name_counter = Counter(name_dict)
# 按出现次数排序后的人名列表
name_list_sort = []
# 按出现次数排序后的人名百分比列表
name_list_fracs = []
# 按出现次数排序后的人名次数列表
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
# print(k+':'+str(v))
# 绘制条形图
self.showNameBar(name_list_sort, name_list_count)
# 绘制饼状图
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
# 参与统计的人名列表
name_list = ['宋江', '李逵', '武松', '吴用', '林冲', '鲁智深', '戴宗', '卢俊义', '燕青','柴进']
# 红楼梦txt文件所在路径
txt_path = 'F:/水浒传.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)