在爬数据的时候,登录一直是一个比较麻烦的问题。我也一直在网上找过各种资料,都挺麻烦的,因为需要分析各种http过程,感觉太麻烦了。
不过最近在一个同学的帮助下,找到了使用cookie登录的方法。因为带cookie登录的话,server会认为你是一个已登录的用户,所以就会返回给你一个已登录的内容
本文介绍的方法,是使用python的scrapy框架登录的方法。而且也只能登录一些比较简单的网站,对于那种大型的网站,因为目前我也还没有验证过,所以不敢保证。但是经过验证,登录豆瓣是万试万灵的。
1. 获取cookie
这个是整个任务的关键所在。只有获得了cookie才能进行下一步的编码工作。cookie获取的大致过程是自己先手动登录一次你想要的网站,然后记录想登录过程中的cookie就可以了。而想要获取这个cookie,也有两种方法。
1.1 chrome方法——简单粗暴
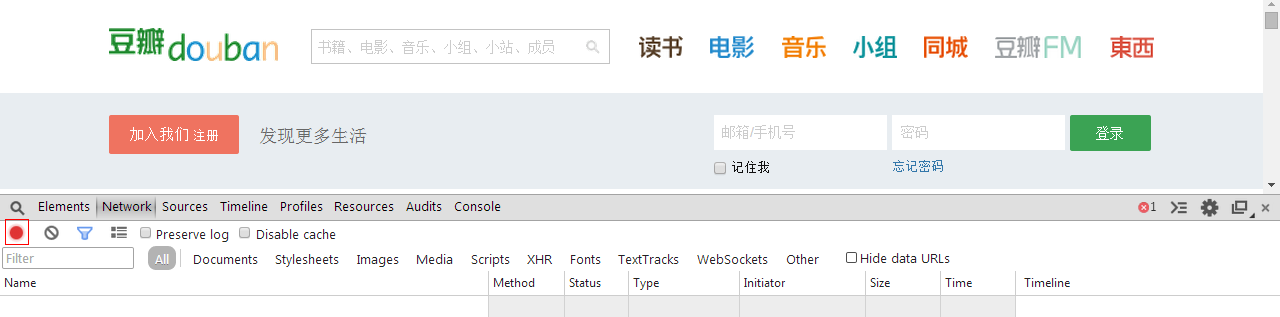
进入豆瓣首页后,F12-Network,就可以看到如上的截图。在这个截图中我们可以看到待会登录过程中各种http的请求的详细信息。注意右下角的红色按钮是红色的,红色表示正在记录,如果不是红色的话。。。就把它按一下保证是红色的就可以了。
在登录框中输入用户名和密码后就会看到下面的Network中出现了一大排的内容,如下图所示:
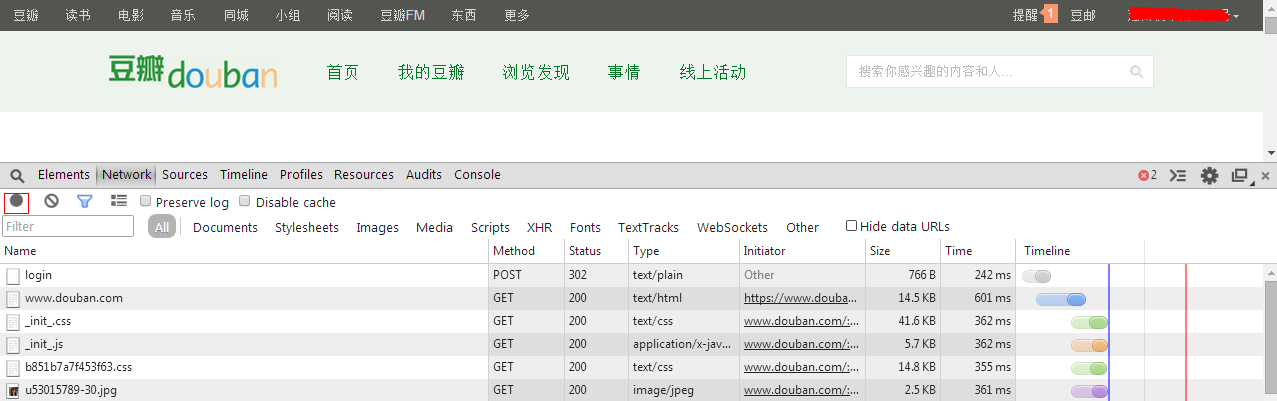
上图是登录成功后的截图,我们可以看到原本Network中的内容是空的,现在已经出现了很多了。为了防止不断出现内容干扰我们的分析,(其实不会干扰,但还是)将刚才的红色按钮关闭,也就是不再记录http消息,如上图中的灰色按钮。
然后这个时候我们就可以好好分析一下,在Network下的Name列中,从哪一项中我们才可以找到cookie了。
我们可以看到(如果出现了很多的话,就把滚动条拉到最上面可以看到)前面几行,除了第二行的“www.douban.com”是text/html类型的,其他的都是些网页的辅助内容,如css和图片。这样呢,我们可以想着说,cookie有可能是在这个html类型的项中,所以我们把“www.douban.com”点击一下,可以得到如下的图片: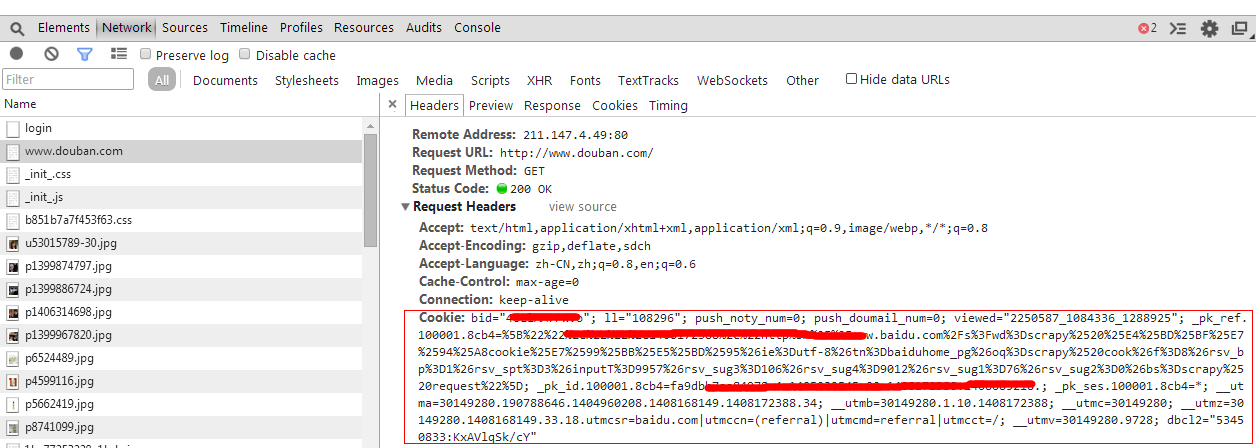
咦?我们在Headers中的Request Headers中找到了cookie诶?现在先假设它能用吧,我们要找的就是他了。那么我们就可以进入到第2步写代码了。
1.2 chrome获取cookie的方法简单粗暴,但是还有另外一种方法也是可以的,不过必须要firefox浏览器,叫做firebug的一个插件工具。这个需要大家自己装一下,挺简单的。
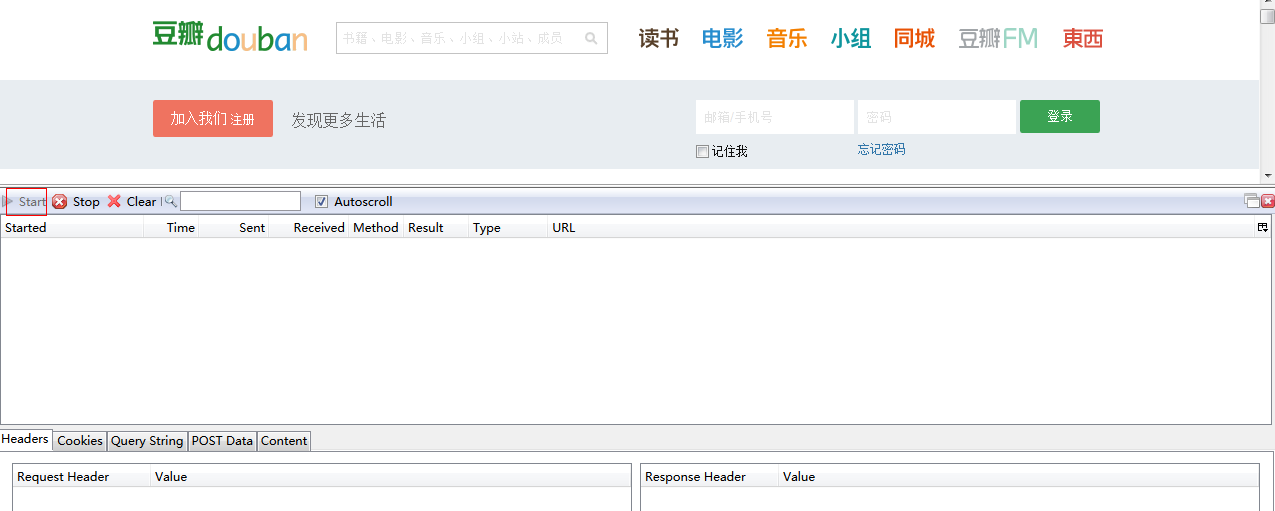
打开以后会出现如上所示的样子,现在还什么都没有。如果想要抓取http通信或者cookie的话,需要要左上角的“start”打开,表示需要firebug进行记录通信内容了。
这时就可以开始登陆了,登陆后相应的会出现很多firebug截取的内容,如下图:
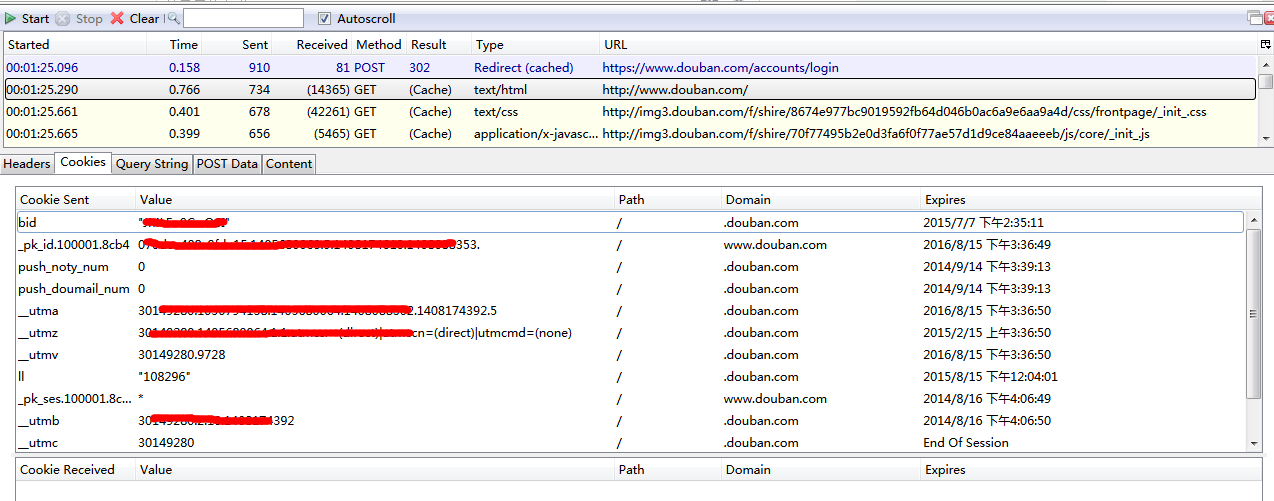
这时我们可以看到,在最上面的一栏中,出现了firebug截取到通信内容,和我们在chrome中看到的内容似乎是一样的。所以我们还是选择“http://www.douban.com”这一项。然后下面一栏中Headers, Cookies之类的就会出现相应的内容。我们要找的内容当然在cookies中,就如上图所示的样子。
我们可以看到,在firebug中获取的cookies的内容,似乎比chrome中获取的内容要少得多。但是没关系,chrome中的内容冗余比较多,只需要firebug中截取的cookies的内容就够了。
然后我们就开始进入到编码阶段了。
2. 编码
# -*- coding:UTF-8 -*- import re import json import codecs from scrapy.spider import Spider from scrapy.selector import Selector from scrapy.http import Request from scrapy import log from douban.items import DoubanItem import sys default_encoding = 'utf-8' reload(sys) sys.setdefaultencoding(default_encoding) class SanzhaSpider(Spider): name = "douban" allowed_domains = ["http://www.douban.com"] def start_requests(self): yield Request(response.url,cookies={'viewed':'"1083428"', '__utmv':'30149280.3975'}, callback=self.parse_with_cookie) def parse_with_cookie(self, response): file = codecs.open('page.html', 'w', encoding='utf-8') file.write(response.body) file.close()
插入代码的内容就如上所示,最重要的方法就是重写的“start_requests”方法。这个方法就不在这里详细讲了,大家可以去官网看。只解释下Request方法的3个参数
url #要带cookie访问的网页的url cookies #这是我们前面讨论了很久才获取的cookie的键值对的内容,需要按照一定的格式描述 callback #当我们提交了这个request请求并获得了相应的response后,我们应该用什么方法去处理返回的response,处理的方法就是callback中给出的方法
好了,按照这种方法,大家就可以顺利的登录豆瓣了。
补充:
1. 当我们抓取登录时http通讯内容时,有那么多的项都会有cookie的内容,为什么我们唯独选择“http://www.douban.com”这一项中的cookie内容呢?
其实这个问题我也没有太明白,如果对于比较复杂的网站,如淘宝新浪之类的,应该没有这么简单。需要后续的深入研究才能解答这个问题。
2. 那应该如何选择正确的cookie内容呢?
额,,,试一试就好了,反正我试过其他的cookie内容,并不能成功。
3. 豆瓣登录有时候可能需要验证码,这个是没关系的,你获取带验证码登录的cookie就没问题了。
Bon Appetite!