目录
1.hadoop概述
2.目前数据集主要特点
3.传统数据 VS 大数据
4.并行关系数据库 VS MPPorHadoop
5.Hadoop的子项目
6.谁在使用hadoop?
1.hadoop概述
Hadoop是一个开源的、可靠的、可扩展的分布式并行计算框架
主要组成(两大核心设计):分布式文件系统HDFS和MapReduce算法执行
HDFS:分布式存储系统,提供了高可靠性、高扩展性和高吞吐率的数据存储服务。
MapReduce:分布式计算框架,具有易于编程、高容错性、和高扩展性等优点。
作者:Doug Cutting
语言:Java,支持多种编程语言如Python、C++
Hadoop是Google的集群系统的开源实现
Google集群系统:GFS(Google File System)、MapReduce、BigTable
Hadoop主要由HDFS(Hadoop Distributed File System)、MapReduce和HBase组成
Hadoop的初衷是为解决Nutch的海量数据爬取和存储的需要
Hadoop于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
名称起源:Doug Cutting儿子的黄色大象玩具的名字
2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,一个微缩版:Nutch。
Hadoop于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。2006年3月份,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入常务Hadoop的项目中。
Google三篇论文:GFS(Google文件系统 底层)、MAPREDUCE(中间计算层)、BIGTABLE
对应hadoop: HDFS(Hadoop分布式文件系统 底层) 、MAPREDUCE(中间计算层)、HBASE(列式数据库(NOSQL)专门解决hadoop所不擅长的事情)
2.目前数据集主要特点
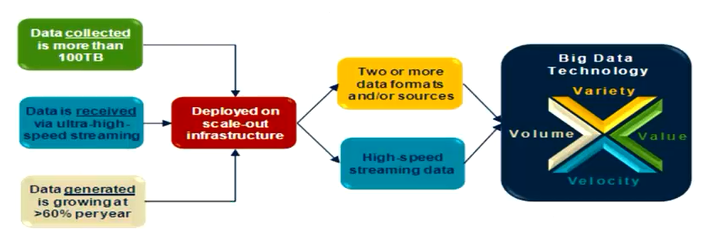
数据集主要特点:
Volum(容量):数据量从TB到PB级别
Variety(多样性):数据类型复制,超过80%的数据是非结构化的
Velocity(速度):数据量在持续增加(两位数的年增长率)
其他特征:
数据来自大量源,需要做相关性分析
需要实时或者准实时的流式采集,有些应用90%写vs10%读
数据需要长时间存储,非热点数据也会被随机访问
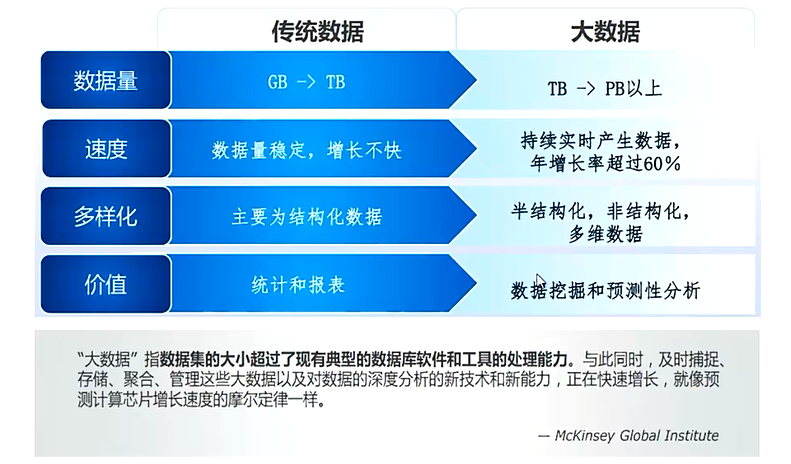
3.传统数据 VS 大数据
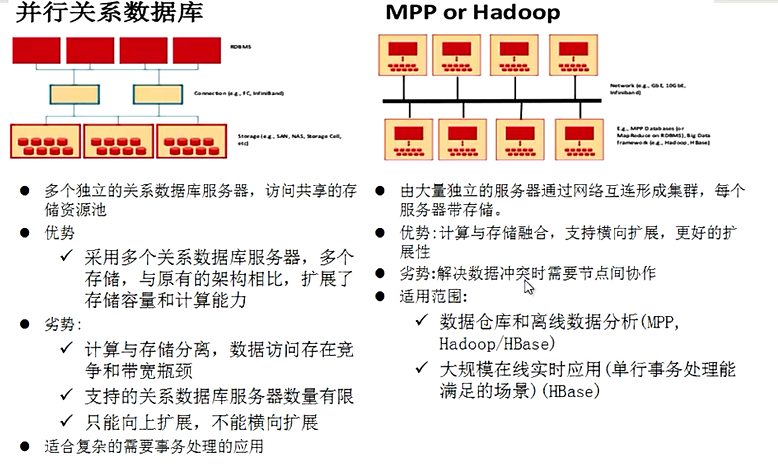
4.并行关系数据库 VS MPPorHadoop
5.Hadoop的子项目
注意:红色部分是属于hadoop家族的,黑色部分是不属于hadoop家族的。

6.谁在使用hadoop?
雅虎北京全球软件研发中心、中国移动研究院、英特尔研究院、金山软件、百度、腾讯、新浪、搜狐、淘宝、IBM、FaceBook、Amazon、Yahoo、华为等