transform方法
transform会讲一个函数运用到各个分组。
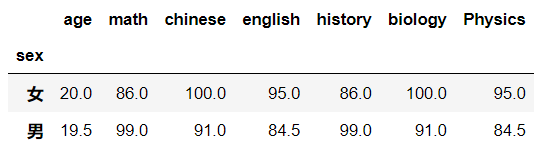
文件6.xlsx的内容如下:
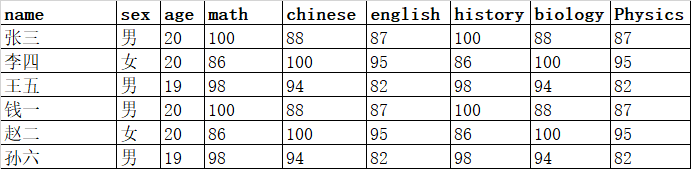
假设我们想为DataFrame添加一个用于存放各索引分组平均值的列。我们可以先聚合再合并:
from pandas import Series,DataFrame import pandas as pd df = pd.read_excel('F:/Jupyter/6.xlsx') sex_mean = df.groupby('sex').mean().add_prefix('mean_') sex_mean pd.merge(df,sex_mean,left_on='sex',right_index=True)
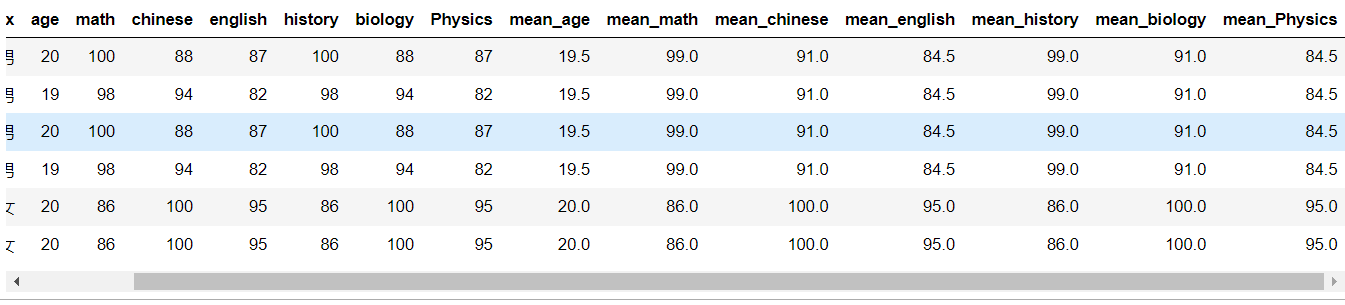
接下来,我们用transform方法解决这个问题:
from pandas import Series,DataFrame import pandas as pd import numpy as np df = pd.read_excel('F:/Jupyter/6.xlsx') key = ['sex'] sex_mean = df.groupby(key).transform(np.mean).add_prefix('mean_') sex_mean
运行结果:
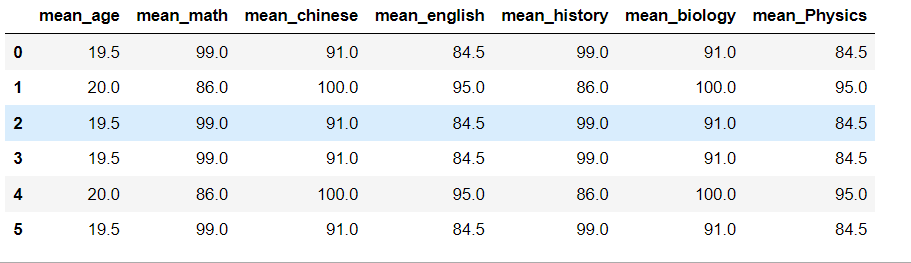
这个方法的好处是,假设我们现在要将每个人的平均分再减10分。我们只需要写一个函数 def minus()
from pandas import Series,DataFrame import pandas as pd import numpy as np df = pd.read_excel('F:/Jupyter/6.xlsx') # key = ['age'] def minus(arr): return arr-10 sex_mean = df.groupby('age').transform(minus).add_prefix('mean_') sex_mean
执行结果:
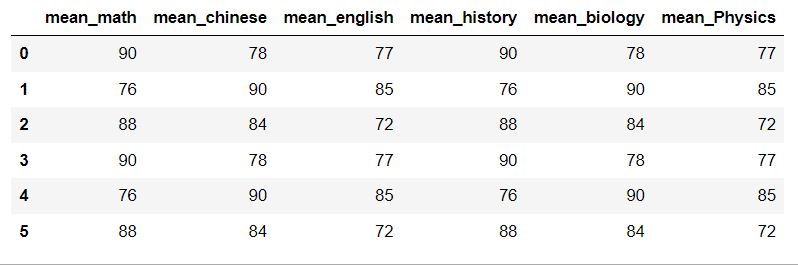
从结果中,我们可以看到列表中的每个数值均被减10。
applye方法
调用applye方法返回的是一个pandas对象或标量值。
题目:分别计算男生和女生每个科目的平均成绩。
from pandas import Series,DataFrame import pandas as pd import numpy as np df = pd.read_excel('F:/Jupyter/6.xlsx') def find(df): return df.mean() sex = df.groupby('sex').apply(find) sex
运行结果: