NLP目前广泛使用预训练+fine-tuning的套路,而不同任务上做fine-tuning会得到不同的参数集合,在实际应用中就需要存放不同版本的weights,比如使用BERT在四个任务上做fine-tuning,就需要存放4个BERT weights,空间开销非常大,降低可扩展性。
已有解决fine-tune扩展性差问题的方法:
1 移除部分参数,只更新模型部分参数
2 插入新的参数,被称为task-specific adapter,只对adapter参数做更新,比如在MHA和FNN 之后再加一个sublayer
3 prompting,设计prompt连同原始输入一起输入到预训练模型,不会tune任何参数。
prompt-tuning使用prompt来指导预训练模型生成特定任务的输出,预训练模型本身的weights不做更新,而prompt的参数量相对预训练模型本身要小很多,这样不同的任务只需要存放少量的prompt参数即可,预训练模型可以复用。在个性化场景,甚至一个batch内可以同时存在不同任务、不同用户的prompt及其输入。
Prefix-Tuning: Optimizing Continuous Prompts for Generation,该论文提出的prefix-tuning主要做NLG任务,prefix是指人为构造的输入前缀,模型的输入变成了[prefix embedding,x],训练时只更新prefix embedding,其他模型参数保持不变。相对prompt 使用词表中的token 对应的embedding,prefix embedding就是单纯的训练参数,不会有对应的实际的token,这使得它具有更好的表达能力。论文在两个预训练模型上(GPT-2 & BART(encoder-decoder)),分别在两个任务上做了实验,(1) table-to-text,输入时结构化的table数据,输出是对table的描述性文本序列;(2) 文本摘要。
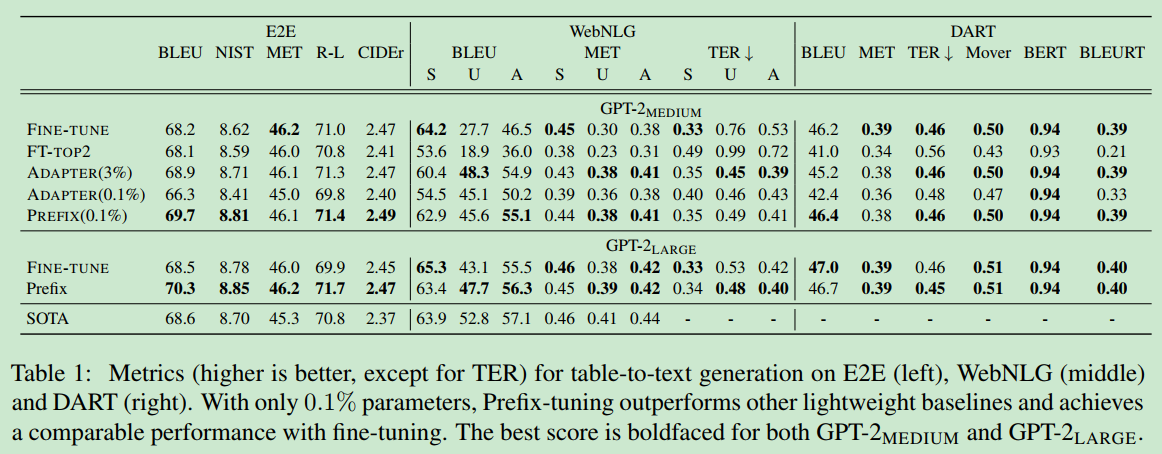
table-to-text任务上,prefix-tuning使用了0.1%的预训练模型参数量,取得了和fine-tuning相当的精度。adapter方法需要把参数量增加到3%才能达到0.1%的prefix-tuning精度。文本摘要任务上精度不佳:
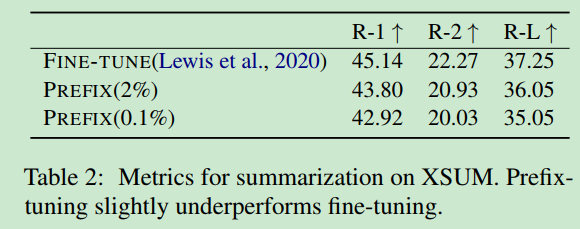
prefix-tuning在复杂、数据量较大的任务上表现并没有fine-tuning好。