源码地址:https://github.com/ZhixiuYe/NER-pytorch
本篇正式进入源码的阅读,按照流程顺序,一一解剖。
一、流程图
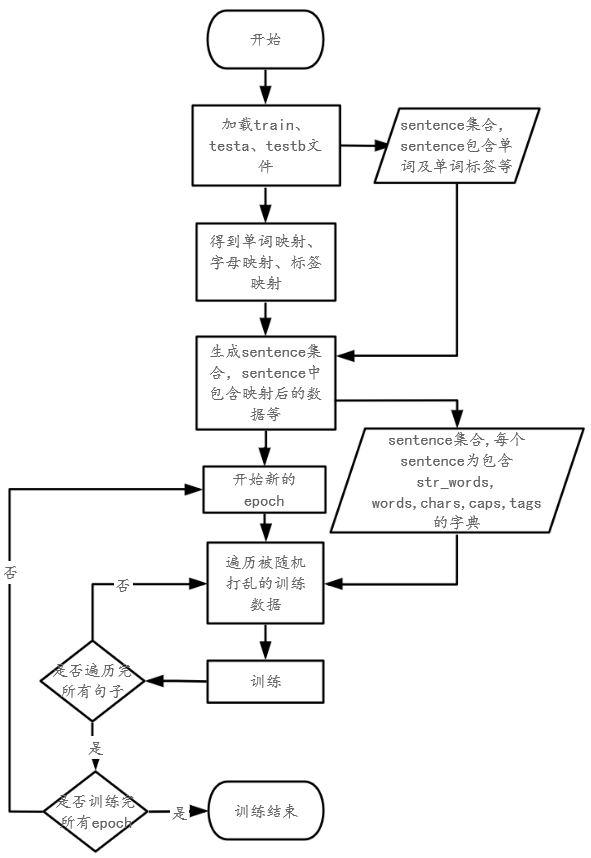
二、详细步骤
1、数据预处理
1)将数据集从文件中加载出来,如果句子中出现了数字,会将其置零(可选),删除![]() 无用句。
无用句。
2)转换标注模式,将iob1(数据集原有标注模式)转换为iob2,如果选用的是IOBES则将iob2转换成iobes,选用的是IOB,则将iob2返回。iob1和iob2都是表示里面只有I、O、B,不同的是iob1中的B是为了隔断同类实体不同实体名的,而iob2中的B是为了作为实体名的开头的。iobes中包含I(实体名内部)、O(非实体)、B(实体的开头)、E(实体的结尾)、S(单字实体名)。
下例将说明iob1、iob2、iobes的形式:

3)创建word、char、tag、cap字典(根据训练集)。
word字典:统计单词词频,筛选出词频大于3的单词,按照词频逆序、单词顺序对单词由0开始编号并加入字典中。除此,加入'<PAD>'、'<UNK>'这两个单词,分别表示pad和未知词汇,赋予最大的两个编号。
char字典:统计字母频数,按照词频逆序、字母顺序对字母由0开始编号并加入字典中,除此,加入'<PAD>'并赋予最大的编号。
tag字典:统计标签频数,按照标签频数逆序、标签顺序对标签由0开始编号并加入字典中,除此,加入'<START>'和'<STOP>'并分别赋予-1和-2编号
cap字典:无法创建字典,映射关系为全小写:0,全大写:1,首字母大写:2,其他:3。
4)根据3创建的字典和映射关系,分别对训练集、验证集、测试集的word、char、cap、tag等特征做数值化。得出的数据集中每一句由{'str_words': str_words,'words': words,'chars': chars,'caps': caps,'tags': tags,}字典组成,句中每个单词对应一个这样的字典。
2、进入训练
从上面的数据预处理中,假如我们得到这么一个句子数据:
{'str_words': ['Amy','goes','to','Beijing','to','visit','Peking','University'],
'chars': [[0, 1, 2], [3, 4, 5, 6], [7, 4], [8, 5, 9, 10, 9, 11, 3], [7, 4], [12, 9, 6, 9, 7], [13, 5, 14, 9, 11, 3], [15, 11, 9, 12, 5, 16, 6, 9, 7, 2]],
'tags': [0,1,1,2,1,1,3,3], }
注:该示例的words、chars、tags并未按照1所说的根据词频进行的编码,只是按照出现的先后顺序进行的编码。
1)char Embedding
① 对'chars'根据word长度进行排序,得到排序后的列表,与原列表对比生成索引映射关系。
② 对排序后的列表进行mask处理,即对word进行尾部填充0知道达到最长word长度。本例中,即是生成:[[15, 11, 9, 12, 5, 16, 6, 9, 7, 2],[8, 5, 9, 10, 9, 11, 3, 0, 0, 0],......],为8×10的矩阵。
③ 将生成的char新矩阵输入Embedding层,设置的size为25,在本例中将得到8×10×25的矩阵,并进行转置,成为10×8×25的矩阵。
④ 对得到的矩阵进行pack操作(去除pad),成为39×25的PackedSequence,batchsize为(10,7,6,5,4,3,2,2)。
⑤ 将PackedSequence输入到双向LSTM中,然后把输出的output的pack操作还原回去,再进行转置操作。
⑥ 提取出output中最后一个字母的out和第一个字母的out进行拼接,并且将排序的结果还原。
注:如果在进行pack操作时,选择batch_first=True,则不用进行转置操作;进行长度排序是pack操作必经的过程;双向lstm的结果的第三维长度为2*size,拼接时选择第一个字母的后size长度(t→1)和最后一个字母的前size长度(1→t)。
2)word Embedding
输入embedding层
3)cap Embedding
输入embedding层
4)拼接所有的Embedding并输入LSTM中
① 拼接char、word、cap Embedding
② 对最终的Embedding增加第二维(unsqueeze)
③ 输入到dropout层
④ 输入到双向LSTM层
⑤ 减去第二维
⑥ 输入到dropout层
⑦ 输入到一个线性层
5)无crf的话,使用交叉熵作为loss函数。