1. 数据的分类
结构化数据: 查询方法 数据库
非结构化数据: 查询方法 :
(1)顺序扫描法 : 一行一行的看,从头看到尾
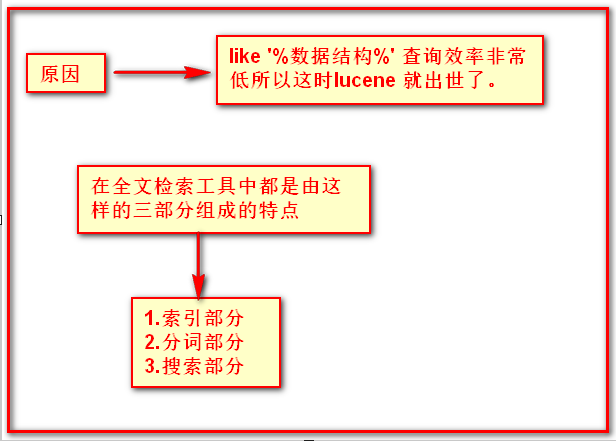
(2)全文检索 : 将一部分信息提取出来,重新组织将其变得有一定结构 然后对其搜索 这部分信息称为索引 例如:字典
这种先建立索引然后再对其扫描的过程就叫全文检索。
虽然创建索引的过程是非常耗时的,但是索引一旦创建可以多次使用,全文检索主要是做查询的所以耗时间创建索引是非常值得的。
2. 应用场景
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
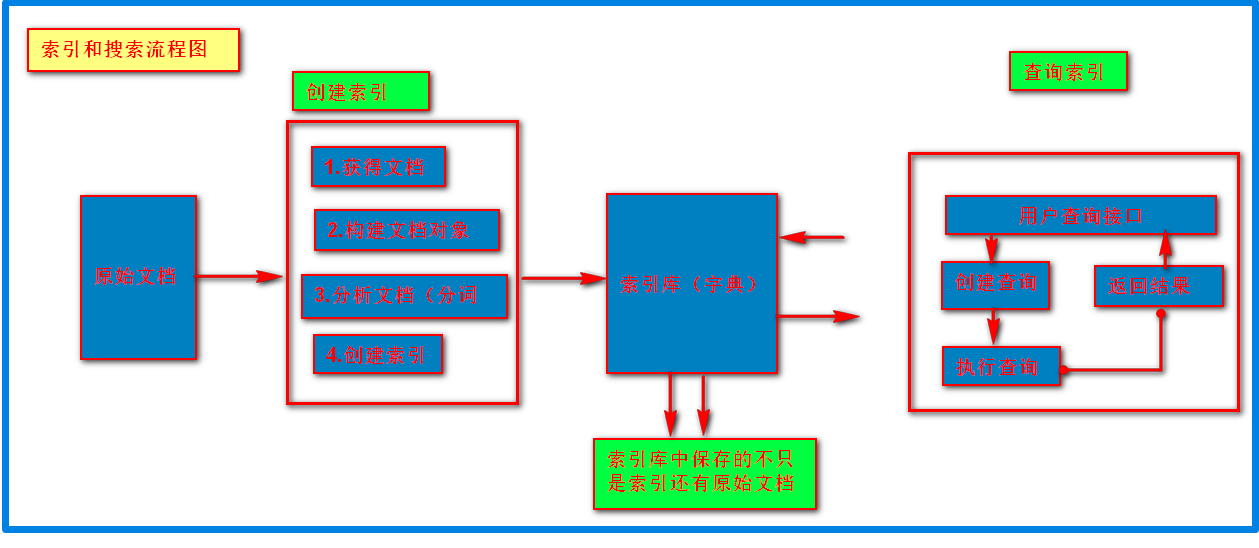
3. 解释部分
(1)首先需要获取原始内容然后进行索引,在索引前需要将原始内容创建成文档,文档中包含很多域,这些域主要用于存储内容。
先上代码演示:
创建
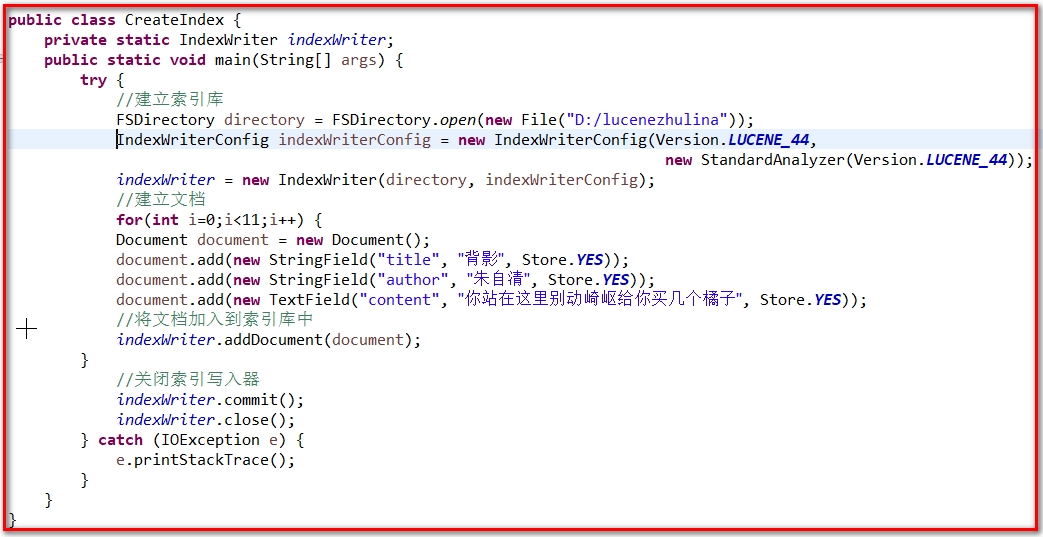


package com.baizhi.lucence; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.StringField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.store.RAMDirectory; import org.apache.lucene.util.Version; public class TestCreateIndexWriter { //创建索引写入器 (并且存入一篇文章) public static void main(String[] args) { IndexWriter indexWriter = null; try { //创建indexConfig对象 保存了两个主要的属性一个是 Lucene的版本 另外一个是分词器以及版本 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_44,new StandardAnalyzer(Version.LUCENE_44)); //创建内存索引目录 Directory direction = FSDirectory.open(new File("D:/lucenezhulina")); //创建 索引写入器对象 需要两个对象一个 索引目录 封装的需要的配置 indexWriter = new IndexWriter(direction, indexWriterConfig); //创建文档 for(int i=0;i<10;i++) { Document document = new Document(); document.add(new StringField("id", String.valueOf(i), Store.YES)); document.add(new StringField("title", "背影"+i, Store.YES)); document.add(new StringField("author", "朱自清", Store.YES)); document.add(new TextField("content", "你站这里不要动,我去给你买几个橘子", Store.YES)); //添加文章 indexWriter.addDocument(document); } indexWriter.commit(); indexWriter.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
搜索

package com.baizhi.lucence; import java.io.File; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; public class TestSearchIndex { /* * 八种基本数据类型 +String 类型不分词 * Text类型分词 标准分词器的规则 单字分词 * */ public static void main(String[] args) { try { //获取指定索引库 Directory direction = FSDirectory.open(new File("D:/lucenezhulina")); //将索引库放入DirectoryReader中 DirectoryReader reader = DirectoryReader.open(direction); //创建索引搜索对象 IndexSearcher indexSearcher = new IndexSearcher(reader); //搜索条件 TermQuery query = new TermQuery(new Term("content","橘")); //相关度排序 TopDocs topDocs = indexSearcher.search(query, 100); //获取索引编号 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for(int i=0;i<scoreDocs.length;i++) { System.out.println("索引编号 "+scoreDocs[i].doc); System.out.println("文章分数 "+scoreDocs[i].score); //获取一个文章 Document document = indexSearcher.doc(scoreDocs[i].doc); System.out.println("文章编号 "+document.get("id")); System.out.println("文章标题 "+document.get("title")); System.out.println("文章作者 "+document.get("author")); System.out.println("文章内容 "+document.get("content")); System.out.println("==================================="); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
更改
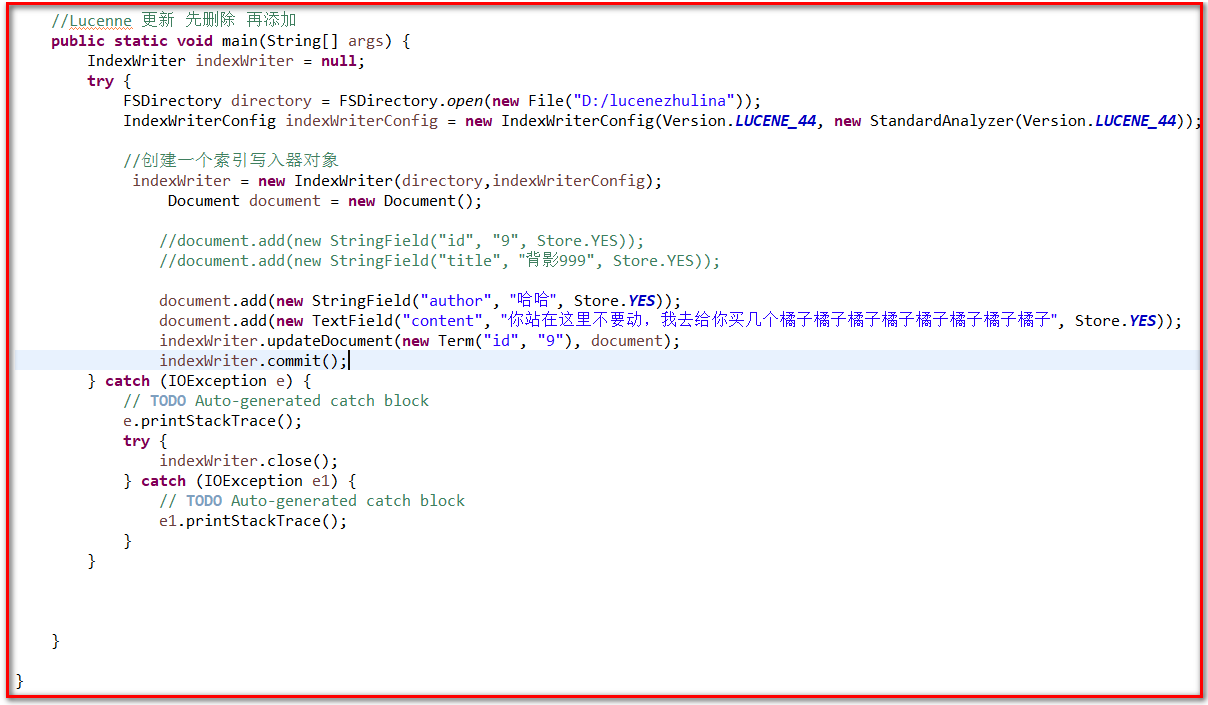
1 import static org.junit.Assert.assertNotNull; 2 3 import java.io.File; 4 import java.io.IOException; 5 6 import org.apache.lucene.analysis.standard.StandardAnalyzer; 7 import org.apache.lucene.document.Document; 8 import org.apache.lucene.document.StringField; 9 import org.apache.lucene.document.TextField; 10 import org.apache.lucene.document.Field.Store; 11 import org.apache.lucene.index.IndexWriter; 12 import org.apache.lucene.index.IndexWriterConfig; 13 import org.apache.lucene.index.Term; 14 import org.apache.lucene.store.FSDirectory; 15 import org.apache.lucene.util.Version; 16 public class TestUpdateIndex { 17 18 //Lucenne 更新 先删除 再添加 19 public static void main(String[] args) { 20 IndexWriter indexWriter = null; 21 try { 22 FSDirectory directory = FSDirectory.open(new File("D:/lucenezhulina")); 23 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_44, new StandardAnalyzer(Version.LUCENE_44)); 24 25 //创建一个索引写入器对象 26 indexWriter = new IndexWriter(directory,indexWriterConfig); 27 Document document = new Document(); 28 29 //document.add(new StringField("id", "9", Store.YES)); 30 //document.add(new StringField("title", "背影999", Store.YES)); 31 32 document.add(new StringField("author", "哈哈", Store.YES)); 33 document.add(new TextField("content", "你站在这里不要动,我去给你买几个橘子橘子橘子橘子橘子橘子橘子橘子", Store.YES)); 34 indexWriter.updateDocument(new Term("id", "9"), document); 35 indexWriter.commit(); 36 } catch (IOException e) { 37 // TODO Auto-generated catch block 38 e.printStackTrace(); 39 try { 40 indexWriter.close(); 41 } catch (IOException e1) { 42 // TODO Auto-generated catch block 43 e1.printStackTrace(); 44 } 45 } 46 47 48 49 } 50 51 }
删除
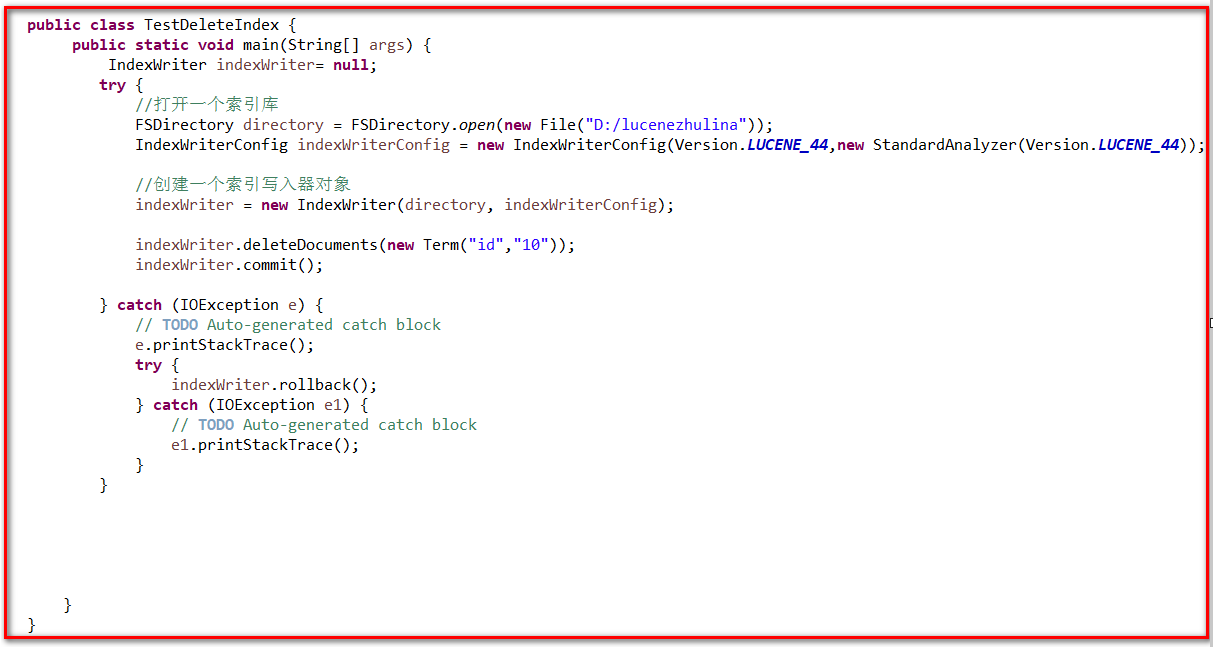
1 import java.io.File; 2 import java.io.IOException; 3 4 import org.apache.lucene.analysis.standard.StandardAnalyzer; 5 import org.apache.lucene.index.IndexWriter; 6 import org.apache.lucene.index.IndexWriterConfig; 7 import org.apache.lucene.index.Term; 8 import org.apache.lucene.store.FSDirectory; 9 import org.apache.lucene.util.Version; 10 11 public class TestDeleteIndex { 12 public static void main(String[] args) { 13 IndexWriter indexWriter= null; 14 try { 15 //打开一个索引库 16 FSDirectory directory = FSDirectory.open(new File("D:/lucenezhulina")); 17 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_44,new StandardAnalyzer(Version.LUCENE_44)); 18 19 //创建一个索引写入器对象 20 indexWriter = new IndexWriter(directory, indexWriterConfig); 21 22 indexWriter.deleteDocuments(new Term("id","10")); 23 indexWriter.commit(); 24 25 } catch (IOException e) { 26 // TODO Auto-generated catch block 27 e.printStackTrace(); 28 try { 29 indexWriter.rollback(); 30 } catch (IOException e1) { 31 // TODO Auto-generated catch block 32 e1.printStackTrace(); 33 } 34 } 35 36 37 38 39 40 } 41 }