1.整型数和浮点型数的表示
原码:第一位为符号位(0为正数,1为负数)。
反码:符号位不动,源码取反。
正数补码:和原码相同。
负数补码:符号位不动,反码加1。
例如5的二进制表示可以是00000101,-6的表示:原码10000110,反码11111001,补码11111010,-1的表示:10000001,反码11111110,补码11111111
补码的好处:0的表示唯一,数的符号位可以同数值部分作为一个整体参与运算,可以直接做加法,减法运算可以用加法来实现,即用求和来代替求差。
例如:0的表示:正数00000000,负数10000000。
-6+5 -4+5
11111010 11111100
+00000101 +00000101
= 11111111 = 00000001
打印正数的二进制表示
int a=-6;
for(int i=0;i<32;i++){
int t=(a & 0x80000000>>>i)>>>(31-i);
System.out.print(t);
}
IEEE754浮点数的表示格式:s eeeeeeee mmmmmmmmmmmmmmmmmmmmmmm
符号位(1) 指数位(8) 尾数(23)
e全0 尾数附加位全0,否则尾数附加位为1
s*m*2(e-127)
例如:1 10000001 0100000000000000000000
-1*2(129-127)*(20+2-2) = -5
将单精度浮点数转成IEEE754二进制表示的代码示例:
package work.jvm;
public class ftob {
public static final int BITS = 32;
public static void main(String[] args) {
int i;
ftob ftb = new ftob();
float f = -9f;
System.out.println("float is:" + f);
int[] b = ftb.printBinaryFloat(f);
System.out.print("Binary is:");
for(i = 0; i < BITS; i++){
System.out.print(b[i]);
}
}
public int[] printBinaryFloat(float f){
int j;
int r[] = new int[32];
int temp = Float.floatToIntBits(f);
for(j = BITS-1; j >= 0; --j){
r[BITS-1-j] = ((temp>>j)&0x01);
}
return r;
}
}
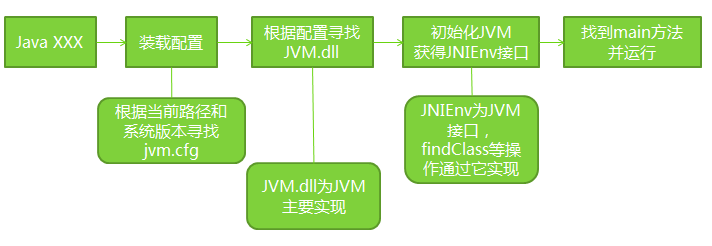
2.jvm运行机制
JVM启动过程:
JVM基本结构:
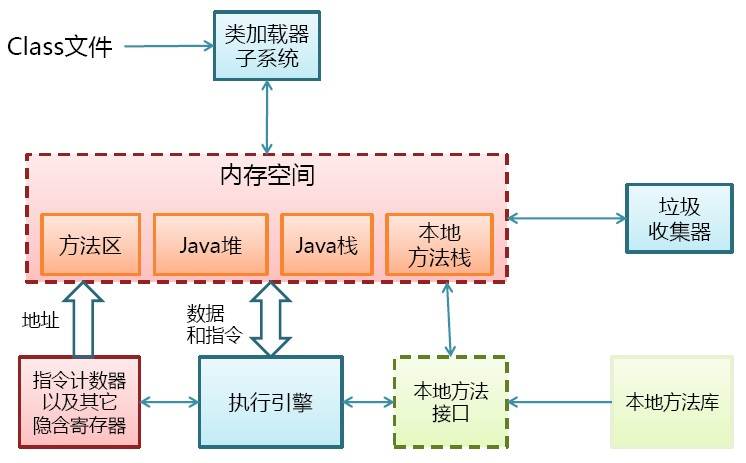
(1)PC寄存器:每个线程拥有一个PC寄存器,在线程创建时创建,指向下一条指令的地址,执行本地方法时,PC的值为undefined。
(2)方法区:保存装载的类信息,如i类型的常量池、字段和方法信息、方法字节码,通常和永久区(Perm)关联在一起。
(3)java堆:和程序开发密切相关,应用系统对象都保存在Java堆中,所有线程共享Java堆,对分代GC来说,堆也是分代的,GC的主要工作区间。

(4)java栈:线程私有,栈由一系列帧组成(因此Java栈也叫做帧栈),帧保存一个方法的局部变量、操作数栈、常量池指针,每一次方法调用创建一个帧,并压栈。
栈上分配:小对象(一般几十个bytes),在没有逃逸的情况下,可以直接分配在栈上,直接分配在栈上,可以自动回收,减轻GC压力,大对象或者逃逸对象无法栈上分配。
(5)堆、栈、方法区交互:
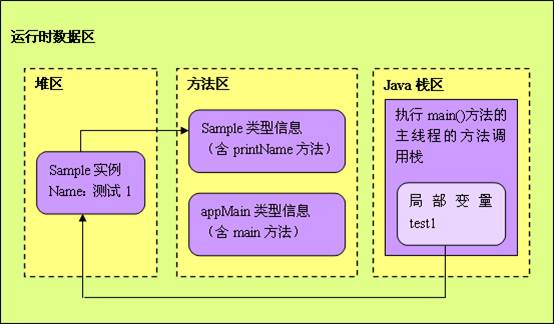
public class AppMain
//运行时, jvm 把appmain的信息都放入方法区
{
public static void main(String[] args)
//main 方法本身放入方法区。
{
Sample test1 = new Sample("测试1");
//test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
Sample test2 = new Sample("测试2");
test1.printName(); �test2.printName();
}
}
public class Sample
//运行时, jvm 把appmain的信息都放入方法区
{
�private name;
//new Sample实例后,name引用放入栈区里,name对象放入堆里
public Sample(String name)
{
this.name = name;
}
//print方法本身放入 方法区里。
public void printName()
{
System.out.println(name);
}
}
3.jvm配置参数
(1)Trace跟踪参数
-verbose:gc
-XX:+PrintGCDetails 打印GC详细信息
-XX:+PrintGCTimeStamps 打印CG发生的时间戳
-Xloggc:log/gc.log 指定GC log的位置,以文件输出
-XX:+TraceClassLoading 监控类的加载
-XX:+PrintClassHistogram 按下Ctrl+Break后,打印信息 分别显示:序号、实例数量、总大小、类型
(2)堆分配参数
-Xmx –Xms 指定最大堆和最小堆,例如:-Xmx20m -Xms5m
-Xmn 设置新生代大小
-XX:NewRatio 新生代(eden+2*s)和老年代(不包含永久区)的比值,比如4 表示新生代:老年代=1:4,即年轻代占堆的1/5。
-XX:SurvivorRatio 设置两个Survivor区和eden的比,比如8表示 两个Survivor :eden=2:8,即一个Survivor占年轻代的1/10。
-XX:+HeapDumpOnOutOfMemoryError,OOM时导出堆到文件。
-XX:+HeapDumpPath 导出OOM的路径。
-XX:OnOutOfMemoryError 在OOM时,执行一个脚本。例如:
-XX:OnOutOfMemoryError=D:/tools/jdk1.7_40/bin/printstack.bat %p,其中printstack.bat里脚本为D:/tools/jdk1.7_40/bin/jstack -F %1 > D:/a.txt。
当程序OOM时,在D:/a.txt中将会生成线程的dump
也可以在OOM时,发送邮件,甚至是重启程序
(3)栈分配参数
-Xss 通常只有几百K,决定了函数调用的深度,每个线程都有独立的栈空间,局部变量、参数 分配在栈上。
(4)永久区
-XX:PermSize -XX:MaxPermSize
(5)堆分配参数建议
根据实际事情调整新生代和幸存代的大小
官方推荐新生代占堆的3/8
幸存代占新生代的1/10
在OOM时,记得Dump出堆,确保可以排查现场问题
4.GC算法
(1)引用计数算法
引用计数器的实现很简单,对于一个对象A,只要有任何一个对象引用了A,则A的引用计数器就加1,当引用失效时,引用计数器就减1。只要对象A的应用计数器的值为0,则对象A就不可能再被使用,就可以清除了。像python和actionscript用的就是引用计数算法。引用计数有两个问题:i引用和去引用伴随加法和减法,影响性能;ii很难处理循环引用。这个算法java并没有采用。
(2)标记清除
标记-清除算法是现代垃圾回收算法的思想基础。标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。一种可行的实现是,在标记阶段,首先通过根节点,标记所有从根节点开始的可达对象。因此,未被标记的对象就是未被引用的垃圾对象。然后,在清除阶段,清除所有未被标记的对象。
(3)标记压缩
标记-压缩算法适合用于存活对象较多的场合,如老年代。它在标记-清除算法的基础上做了一些优化。和标记-清除算法一样,标记-压缩算法也首先需要从跟节点开始,对所有可达对象做一次标记。但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端。之后,清理边界外所有的空间。
(4)复制算法
与标记-清除算法相比,复制算法是一种相对高效的回收方法。不适用于存活对象较多的场合,如老年代。将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。年轻代的from和to两个区(也叫s1和s2)就是复制算法的两个区。
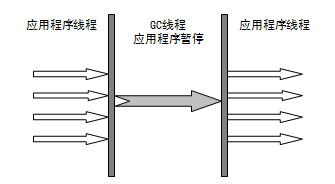
gc可能引发stop the world(STW)现象。STW是Java中一种全局暂停的现象,这个时候所有Java代码停止运行,native代码可以执行,但不能和JVM交互。原因多半由GC引起,还有dump线程,死锁检查,堆dump也有可能引发STW。危害:i长时间(零点几秒到几十秒,甚至更长)服务停止,没有响应;ii遇到HA系统,可能引起主备切换,严重危害生产环境。
5.分代思想与可触及性
分代思想:依据对象的存活周期进行分类,短命对象归为新生代,长命对象归为老年代。
根据不同代的特点,选取合适的收集算法:
少量对象存活,适合复制算法。
大量对象存活,适合标记清理或者标记压缩。
可触及性:
可触及的:-从根节点可以触及到这个对象。
可复活的:-旦所有引用被释放,就是可复活状态,因为在finalize()中可能复活该对象。
不可触及的:-在finalize()后,可能会进入不可触及状态,不可触及的对象不可能复活,可以被回收。
6.GC参数
(1)串行收集器。最古老,最稳定,
效率高,
可能会产生较长的停顿。
参数:
-XX:+UseSerialGC
–新生代、老年代使用串行回收
–新生代复制算法
–老年代标记-压缩
(2)并行收集器
ParNew收集器
-XX:+UseParNewGC
新生代并行,老年代串行
Serial收集器新生代的并行版本
复制算法
多线程,需要多核支持
-XX:ParallelGCThreads 限制线程数量
Parallel收集器
类似ParNew,新生代复制算法,老年代 标记-压缩,更加关注吞吐量。
-XX:+UseParallelGC 使用Parallel收集器+ 老年代串行。
-XX:+UseParallelOldGC 使用Parallel收集器+ 并行老年代。
-XX:MaxGCPauseMills 最大停顿时间,单位毫秒,GC尽力保证回收时间不超过设定值。
-XX:GCTimeRatio 0-100的取值范围,垃圾收集时间占总时间的比,默认99,即最大允许1%时间做GC。
(3)CMS收集器
Concurrent Mark Sweep 并发标记清除,这个并发的意思是与用户现场一起执行。
标记-清除算法
与标记-压缩相比,并发阶段会降低吞吐量
老年代收集器(新生代使用ParNew)
-XX:+UseConcMarkSweepGC
-XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次整理,整理过程是独占的,会引起停顿时间变长。
-XX:+CMSFullGCsBeforeCompaction,设置进行几次Full GC后,进行一次碎片整理。
-XX:ParallelCMSThreads,设定CMS的线程数量。
CMS运行过程比较复杂,着重实现了标记的过程,可分为
i.初始标记。根可以直接关联到的对象,速度快。
ii.并发标记。(和用户线程一起)。主要标记过程,标记全部对象。
iii.重新标记。由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正。
iv.并发清除(和用户线程一起)。基于标记结果,直接清理对象
特点:
尽可能降低停顿,会影响系统整体吞吐量和性能。比如,在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半。
清理不彻底,因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理。
因为和用户线程一起运行,不能在空间快满时再清理。-XX:CMSInitiatingOccupancyFraction设置触发GC的阈值,如果不幸内存预留空间不够,就会引起concurrent mode failure。
(4)几个实例
以32M堆启动tomcat
set CATALINA_OPTS=-server -Xloggc:gc.log -XX:+PrintGCDetails -Xmx32M -Xms32M -XX:+HeapDumpOnOutOfMemoryError -XX:+UseSerialGC -XX:PermSize=32M
以512M堆启动tomcat
set CATALINA_OPTS=-Xmx512m -Xms64m -XX:MaxPermSize=32M -Xloggc:gc.log -XX:+PrintGCDetails -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:ParallelGCThreads=4
(5)最后汇总一下GC参数:
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:SurvivorRatio:设置eden区大小和survivior区大小的比例
-XX:NewRatio:新生代和老年代的比
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发
-XX:+UseCMSCompactAtFullCollection:设置CMS收集器在完成垃圾收集后是否要进行一次内存碎片的整理
-XX:CMSFullGCsBeforeCompaction:设定进行多少次CMS垃圾回收后,进行一次内存压缩
-XX:+CMSClassUnloadingEnabled:允许对类元数据进行回收
-XX:CMSInitiatingPermOccupancyFraction:当永久区占用率达到这一百分比时,启动CMS回收
-XX:UseCMSInitiatingOccupancyOnly:表示只在到达阀值的时候,才进行CMS回收
这一篇文章先写到这里,下一篇继续^-^