1.MapReduce是什么?
MapReduce是一种编程模型,用于大规模数据集的并行运算。它借用了函数式的编程概念,是Google发明的一种数据处理模型。
主要思想为:Map(映射)和Reduce(化简)。
一个Map/Reduce作业(Job)通常会把输入的数据集切分为若干独立的数据块,由Map任务(Task)以完全并行的方式处理它们。框架会先对Map的输出进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架的分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这样可以使整个集群的网络带宽得到非常高效的利用。
Map/Reduce框架由一个单独的Master JobTracker和集群节点上的Slave TaskTracker共同组成。Master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上。Master监控它们的执行情况,并重新执行已经失败的任务,而Slave仅负责执行由Master指派的任务。
在Hadoop上运行的作业需要指明程序的输入/输出位置(路径),并通过实现合适的接口或抽象类提供Map和Reduce函数。同时还需要指定作业的其他参数,构成作业配置(Job Configuration)。在Hadoop的JobClient提交作业(Jar包/可执行程序)和配置信息给JobTracker之后,JobTracker会负责分发这些软件和配置信息给slave及调度任务,并监控它们的执行,同时提供状态和诊断信息给JobClient。
MapReduce是用来进行海量数据的并行计算的,需要将工作分配到大量的机器上去做,如果组件间可共享数据,那么数据节点间的数据同步会使系统变得低效且不可靠。实际上,MapReduce上的数据元素是不可变的,即便改变也不会反馈到输入文件,节点间通信只在新的键值对输出时发生,Hadoop会把输出键值对传到下一个阶段。
2.MapReduce基本流程
MapReduce的数据处理流程分为两个阶段:Map阶段和Reduce阶段。下图所示即是一个适应MapReduce进行单词个数统计的一个实例,大家看了之后就会更明白一点。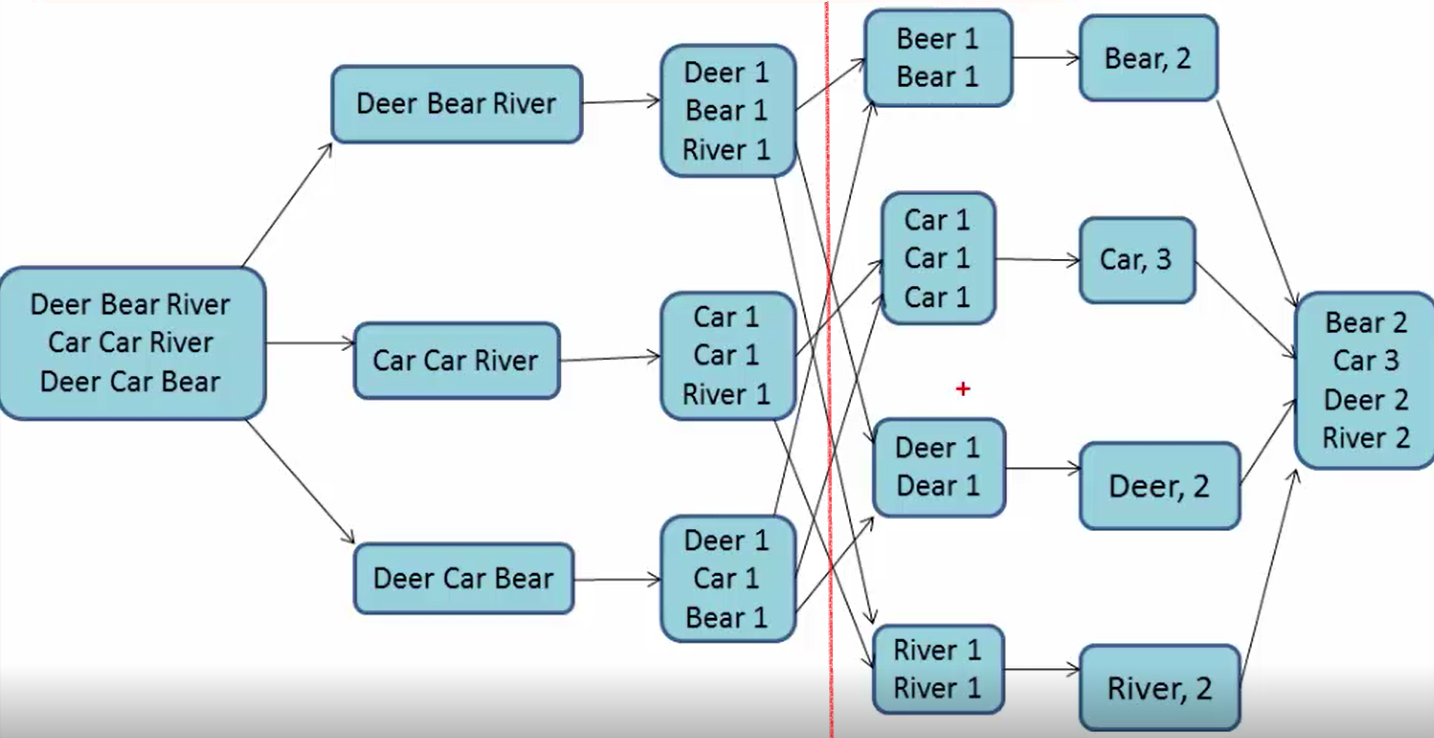
| 读取数据 |
分割后数据并行 |
Map线程 | 输出归类 |
Reduce处理(将相同单词合并然后输出) |
| Map(映射) | Reduce(化简) | |||
3.MapReduce基本设计思想

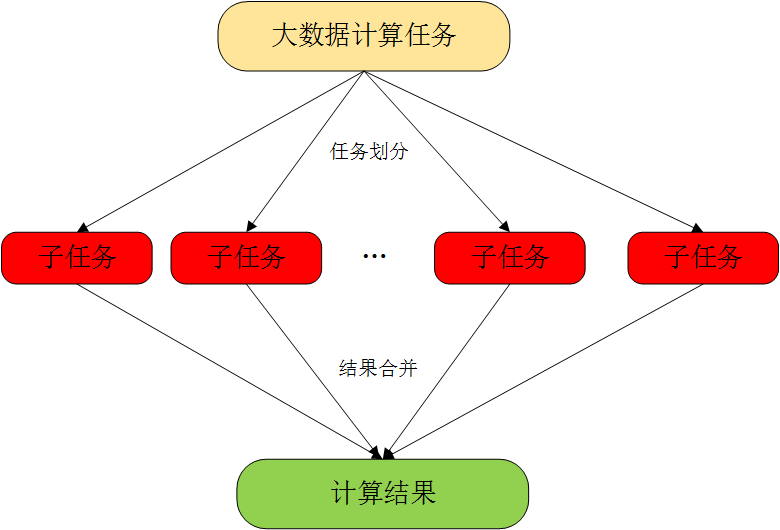
3.1 对付大数据并行处理:分而治之
3.2 上升到抽象模型:Map与Reduce
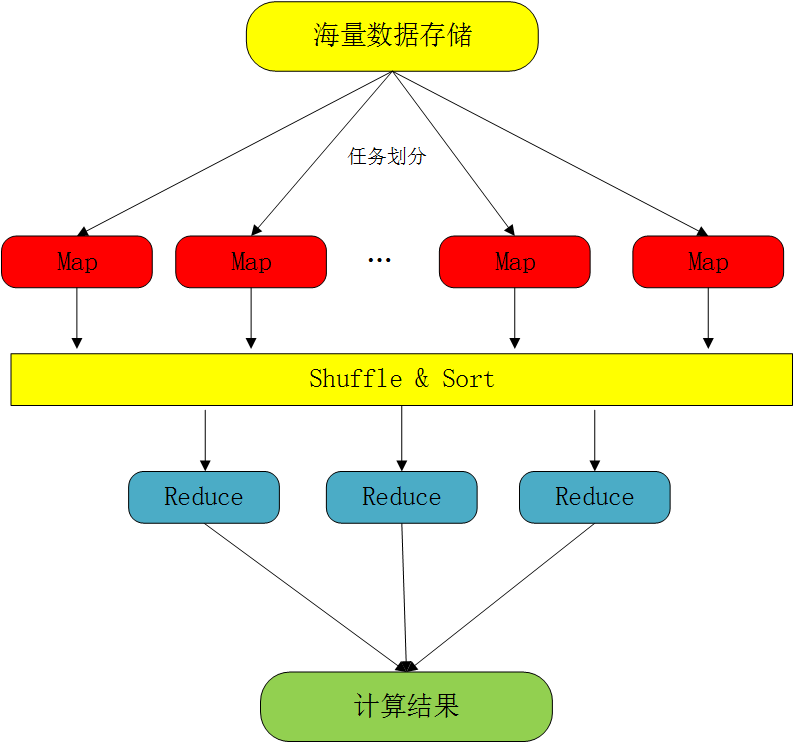
在此过程中,首先将输入数据划分成许多个块,并分别使用一个Map函数对每一个数据块进行 并行处理,第一步输出中间结果。然后将中间结果进行混洗和排序,再递交给Reduce进行处理。同理,Reduce也采用并行计算,最后输出最终结果。
3.3 上升到结构:自动并行化并隐藏底层细节

以上工作都是由MapReduce框架自动完成,用户不需要关心具体 细节的实现,用户只需要继承接口,实现Map()函数和Reduce()函数。
4.实例分析(邮箱域名次数统计)
1.wolys@21cn.com
2.zss1984@126.com
3.154686585@qq.com
4.simulateboy@163.com
5.isrdgol_158@163.com
6.wsiueryu453@126.com
7.lixueying@qq.com
8.897648378@gmail.com
9.785854675@qq.com
10.zsdf567@126.com ......
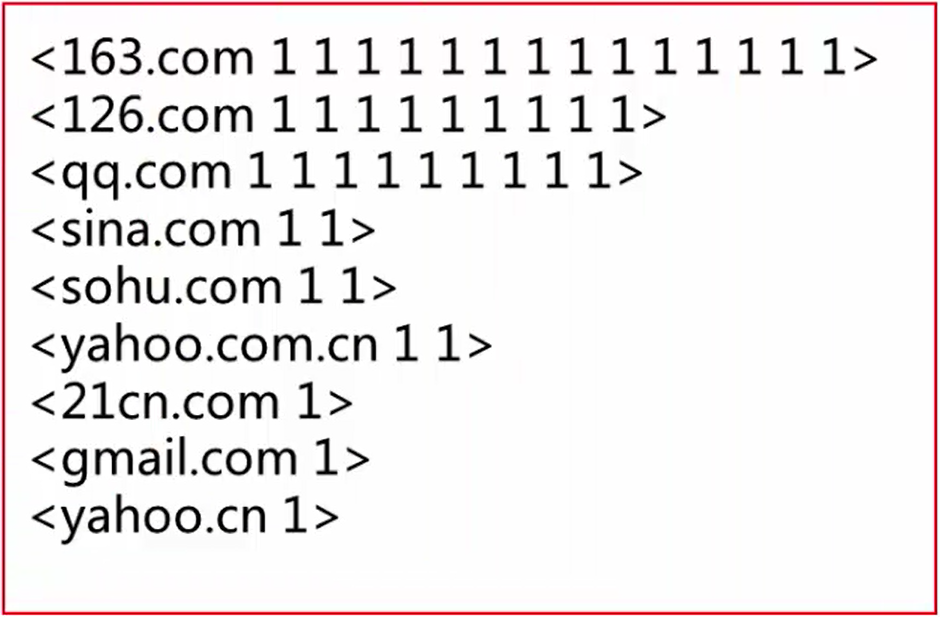
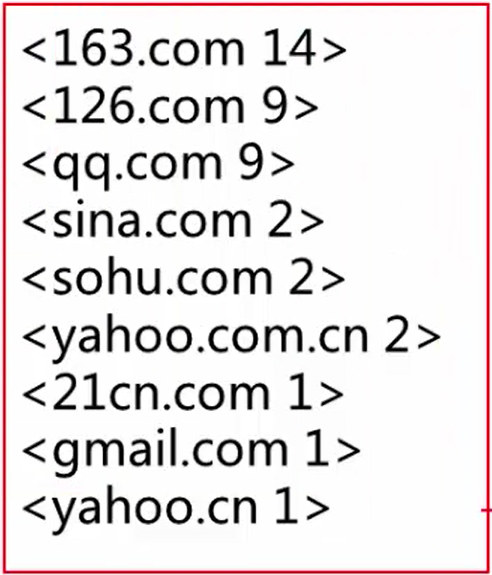
首先我们说明一下域名解析的计数原理,即@分隔符解析出邮箱域名,然后出现一次即统计一次,输出,再进行汇总和处理。我们使用MapReduce以zss1984@126.com邮箱为例进行解析和统计,流程如下。
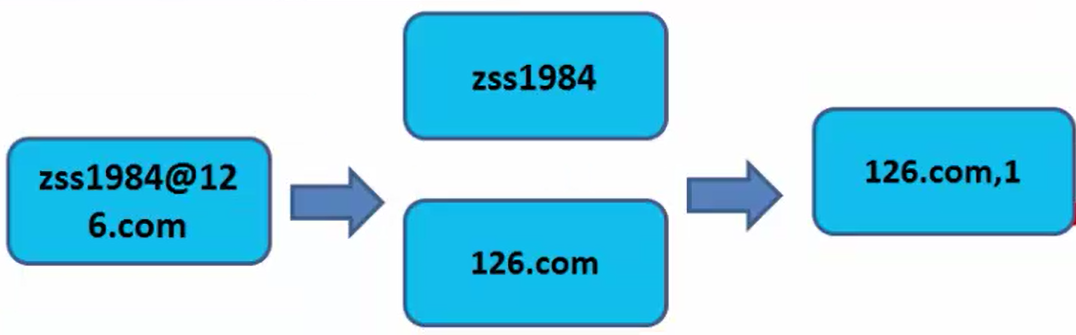
、 然后,对Map输出结果进行混洗和排序,将相同的邮箱域名放在一起,结果如下所示。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。