Sqoop Export应用场景——直接导出
直接导出
我们先复制一个表,然后将上一篇博文(Sqoop Import HDFS)导入的数据再导出到我们所复制的表里。
sqoop export --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' --username root --password-file /user/hadoop/.password --table user_info_copy --export-dir /user/hadoop/user_info --input-fields-terminated-by "," //此处分隔符根据建表时所用分隔符确定,可查看博客sqoop导出hive数据到mysql错误: Caused by: java.lang.RuntimeException: Can't parse input data
运行过程如下:
18/06/21 20:53:58 INFO mapreduce.Job: map 0% reduce 0% 18/06/21 20:54:19 INFO mapreduce.Job: map 100% reduce 0% 18/06/21 20:54:20 INFO mapreduce.Job: Job job_1529567189245_0010 completed successfully 18/06/21 20:54:20 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=371199 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=696 HDFS: Number of bytes written=0 HDFS: Number of read operations=21 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=3 Data-local map tasks=3 //map数为3,在下面可以指定map数来执行导出操作 Total time spent by all maps in occupied slots (ms)=53409 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=53409 Total vcore-seconds taken by all map tasks=53409 Total megabyte-seconds taken by all map tasks=54690816 Map-Reduce Framework Map input records=3 Map output records=3 Input split bytes=612 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=2554 CPU time spent (ms)=2920 Physical memory (bytes) snapshot=300302336 Virtual memory (bytes) snapshot=6184243200 Total committed heap usage (bytes)=85327872 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 18/06/21 20:54:20 INFO mapreduce.ExportJobBase: Transferred 696 bytes in 38.2702 seconds (18.1865 bytes/sec) 18/06/21 20:54:20 INFO mapreduce.ExportJobBase: Exported 3 records.
导入成功后我们再手动查看一下数据库。
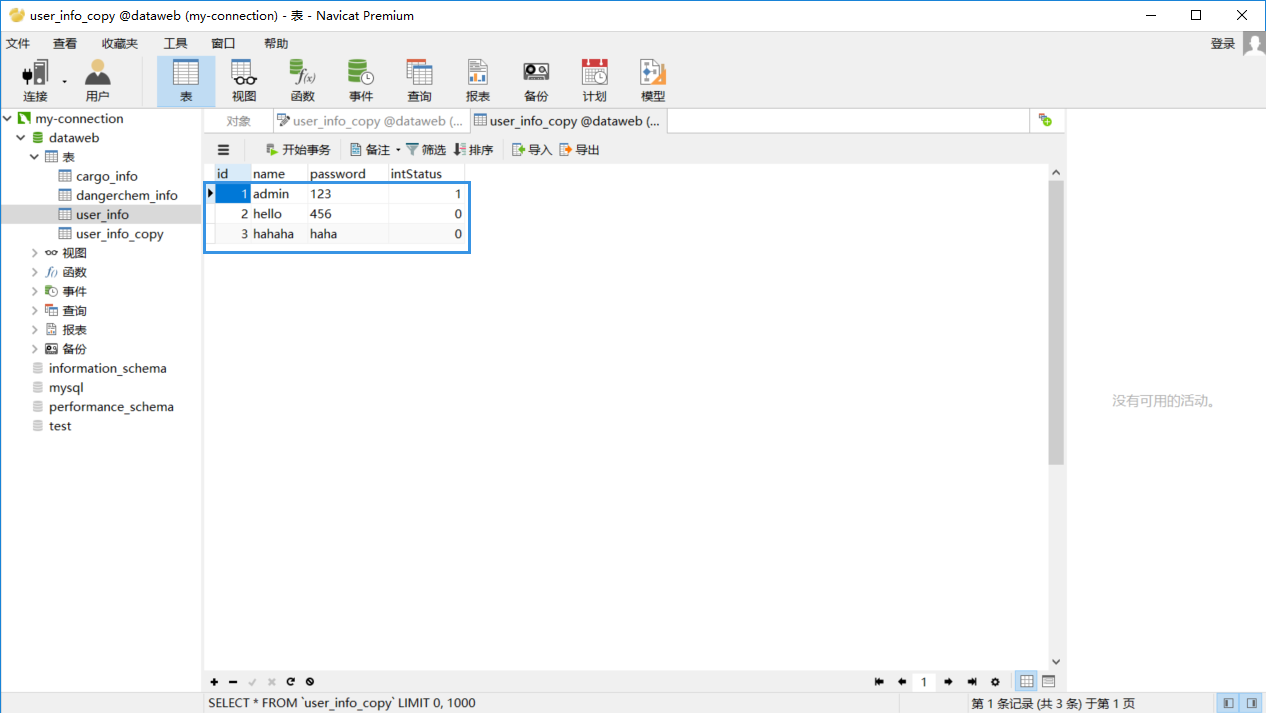
上图表示我们的导入是成功的。
指定Map个数
sqoop export --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' --username root --password-file /user/hadoop/.password --table user_info_copy --export-dir /user/hadoop/user_info --input-fields-terminated-by "," -m 1 //map数设定为1
先清除本地数据库数据之后再测试。

18/06/21 21:15:08 INFO mapreduce.Job: map 0% reduce 0% 18/06/21 21:15:17 INFO mapreduce.Job: map 100% reduce 0% 18/06/21 21:15:17 INFO mapreduce.Job: Job job_1529567189245_0011 completed successfully 18/06/21 21:15:18 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=123733 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=327 HDFS: Number of bytes written=0 HDFS: Number of read operations=10 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=1 Data-local map tasks=1 //map数变为了1个 Total time spent by all maps in occupied slots (ms)=6101 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=6101 Total vcore-seconds taken by all map tasks=6101 Total megabyte-seconds taken by all map tasks=6247424 Map-Reduce Framework Map input records=3 Map output records=3 Input split bytes=274 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=114 CPU time spent (ms)=900 Physical memory (bytes) snapshot=100720640 Virtual memory (bytes) snapshot=2061414400 Total committed heap usage (bytes)=28442624 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 18/06/21 21:15:18 INFO mapreduce.ExportJobBase: Transferred 327 bytes in 25.1976 seconds (12.9774 bytes/sec) //执行时间也较上面减少了 18/06/21 21:15:18 INFO mapreduce.ExportJobBase: Exported 3 records.
Sqoop Export应用场景——插入和更新
先将已经插入的信息作一点修改,然后重新导入,导入之后会将我们修改的信息又给复原回去。

执行命令
sqoop export --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' --username root --password-file /user/hadoop/.password --table user_info_copy --export-dir /user/hadoop/user_info --input-fields-terminated-by "," -m 1 --update-key id --update-mode allowinsert //默认为updateonly(只更新),也可以设置为allowinsert(允许插入)
执行完毕后,信息又重新修改了回来。

Sqoop Export应用场景
事务处理
在将HDFS上的数据导入到数据库中之前先导入到一个临时表tmp中,如果导入成功的话,再转移到目标表中去。
sqoop export --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' --username root --password-file /user/hadoop/.password --table user_info_copy --staging-table user_info_tmp //临时表需要提前创建,可直接复制再重命名 --clear-staging-table --export-dir /user/hadoop/user_info --input-fields-terminated-by ","
18/06/21 21:43:38 INFO mapreduce.Job: map 0% reduce 0% 18/06/21 21:43:58 INFO mapreduce.Job: map 100% reduce 0% 18/06/21 21:43:59 INFO mapreduce.Job: Job job_1529567189245_0014 completed successfully 18/06/21 21:43:59 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=371196 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=696 HDFS: Number of bytes written=0 HDFS: Number of read operations=21 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=3 Data-local map tasks=3 Total time spent by all maps in occupied slots (ms)=52133 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=52133 Total vcore-seconds taken by all map tasks=52133 Total megabyte-seconds taken by all map tasks=53384192 Map-Reduce Framework Map input records=3 Map output records=3 Input split bytes=612 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=617 CPU time spent (ms)=2920 Physical memory (bytes) snapshot=301137920 Virtual memory (bytes) snapshot=6184226816 Total committed heap usage (bytes)=85327872 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 18/06/21 21:43:59 INFO mapreduce.ExportJobBase: Transferred 696 bytes in 36.8371 seconds (18.894 bytes/sec) 18/06/21 21:43:59 INFO mapreduce.ExportJobBase: Exported 3 records. 18/06/21 21:43:59 INFO mapreduce.ExportJobBase: Starting to migrate data from staging table to destination. 18/06/21 21:43:59 INFO manager.SqlManager: Migrated 3 records from `user_info_tmp` to `user_info_copy`
字段不对应问题
先将数据库中的表内容导入到hdfs上(但不是所有的内容都导入,而是只导入部分字段,在这里就没有导入id字段),然后再从hdfs导出到本地数据库中。
[hadoop@centpy hadoop-2.6.0]$ sqoop import --connect jdbc:mysql://202.193.60.117/dataweb
> --username root
> --password-file /user/hadoop/.password
> --table user_info
> --columns name,password,intStatus //确定导入哪些字段
> --target-dir /user/hadoop/user_info
> --delete-target-dir
> --fields-terminated-by ","
> -m 1
[hadoop@centpy hadoop-2.6.0]$ hdfs dfs -cat /user/hadoop/user_info/part-m-* admin,123,1 hello,456,0 hahaha,haha,0
可以看到我们此处导入的数据和数据库相比少了“id”这个字段,接下来,我们如果不使用上面的columns字段,仍然按照原来的方式导入,肯定会报错,因为这和我们的数据库格式和字段不匹配。如下所示:
[hadoop@centpy hadoop-2.6.0]$ sqoop export
> --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8'
> --username root
> --password-file /user/hadoop/.password
> --table user_info_copy
> --export-dir /user/hadoop/user_info
> --input-fields-terminated-by ","
> -m 1
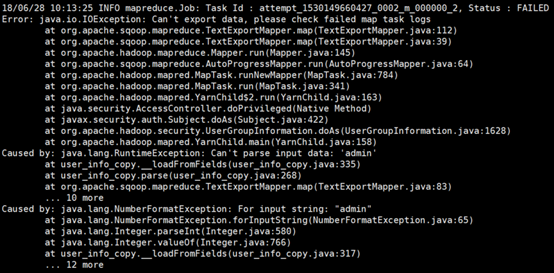
要实现字段不匹配导入必须使用columns字段导出。
[hadoop@centpy hadoop-2.6.0]$ sqoop export
> --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8'
> --username root
> --password-file /user/hadoop/.password
> --table user_info_copy
> --columns name,password,intStatus
> --export-dir /user/hadoop/user_info
> --input-fields-terminated-by ","
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!