结合自己工作中的使用和收集的一些经验,谈谈对Kettle中的ETL的一些优化。
1. 数据库方面
1.1 配置连接池
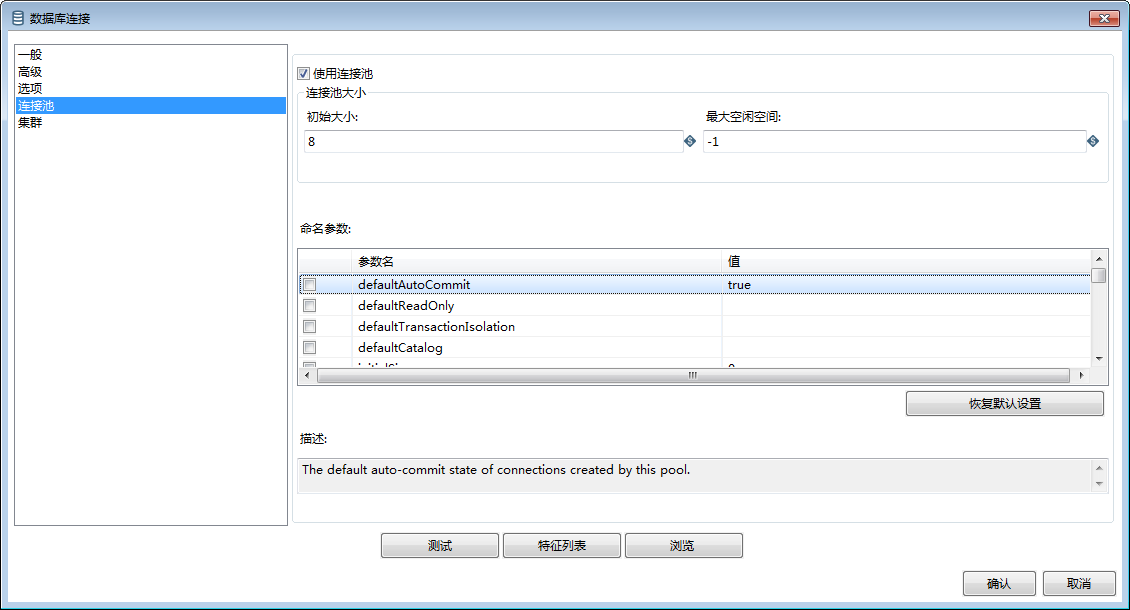
如果业务数据量很多和短连接很多,可以考虑使用数据库连接池,在这个时候,每次数据库连接建立和断开所花费的时间远长于进行数据库操作的时间,配置连接池可以更好的利用网络资源,将连接建立和断开的开销降低到最小。因此在大多数情况下,配置Kettle数据库连接池均可提高ETL的性能,如果没有配置连接池,那么在数据量大时候很容易出现Error Connecting Database Error。
1.2 数据库参数优化
defaultRowPrefetch = 200; (default = 10)
这个参数是修改每次从数据库取回的记录的行数,默认为10,修改为200后可以减少从数据库取值的次数。
(Oracle Only) readTimeout = 60;
这个参数是修改从数据库读数据时的超时时间,单位是秒,将这个值改大一点可以防止大量数据读取时的超时问题。
(Mysql Only) useServerPrepStmts=false; rewriteBatchedStatements=true ; useCompression=true ;
1.3 查询优化
可以使用sql来做的一些操作尽量用SQL。group,merge,stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用SQL就用SQL;
避免在索引列上使用函数或计算,在where子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描;
避免在索引列上使用 NOT和 “!=”,索引只能告诉什么存在于表中,而不能告诉什么不存在于表中,当数据库遇到NOT和 “!=”时,就会停止使用索引转而执行全表扫描;
索引列上用 >=替代 >;
另外需要注意,在设计步骤时,需要关注查询表的数据量,因为一般情况下开发者可能会使用“表输入组件”将表中的所有结果集抽出再使用其他组件进行处理,如果表的数据量在十万级别以下,Kettle会支持;但到百万或者千万级别的数据量,运行步骤,Kettle的效率将极为缓慢。此时数据处理能在SQL中进行应尽量使用SQL,并将步骤进行分片,才能避免速度缓慢或者内存占用过高。
1.4 提高数据库操作中的Commit Size(批处理使用)
在写入数据库的时候,有一个Commit size的选项,这个值在默认的情况下是1,我们可以根据服务器的性能,将这个值改大一些,通常会改为100以上的值。这个值在写入量比较大的时候可以显著提升数据库的性能,但是并不是越大越好,通常范围在100〜10000,需要根据实际情况进行配置,具体数值可以根据性能监控的记录来确定。
这个值从1调整到合适值性能大约可以翻倍,一般情况下也有20%左右的效率提升。
1.5 Insert/Update/Delete优化
1.6 数据库分组和排序优于ETL分组和排序
在ETL中减少排序和分组的操作,尽量使用数据库完成排序和分组。在KTR中,数据是使用流的方式在不同的步骤间传递数据,使用排序和分组的操作会在这一步阻塞KTR的执行,直到接收到前面所有步骤传过来的数据为止,导致ETL的运行时间增长,占用的内存增大。
使用Blocking Step也会将流阻塞到这一步,和以上情况类似。
1.7 尽量使用数据库原生的方式装载文本文件
如Oracle的sqlloader, mysql的bulk loader步骤。
2. 步骤优化
2.1 调整步骤之间的缓存
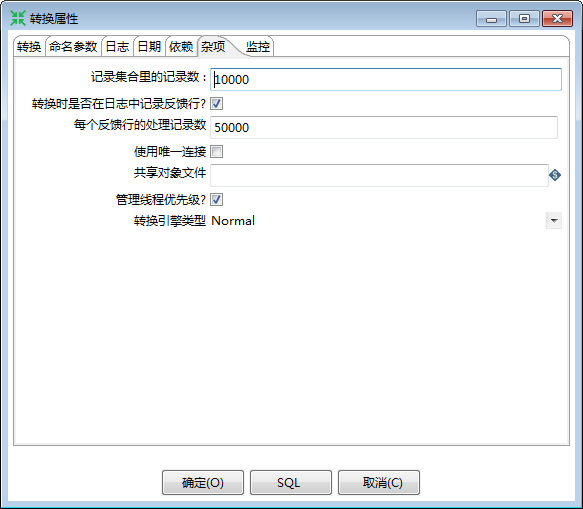
这个值的大小需要根据机器的配置来选择,如果可用内存足够,一般的设置是10000,也就是缓存10000行数据,如果内存比较紧张,可以将该值调小一些,保证不会占用过量内存。
在性能监测时,这也是一个用来找到瓶颈的核心参数。如果某一步的输入和配置的缓存大小接近,但是输出很小,那么这一步就是性能的瓶颈。如果缓存大小配置了10000,但是几乎所有步骤的输入输出都只有很低的一个值,比如50,那么,性能的瓶颈就是输入。
2.2 延迟转化
很多字段在读入到最后输出,实际上都没有被操作过,开启延迟转化可以让kettle在必要的时候再进行转化。这里的转化是指从二进制到字符串之间的转化,在输入和输出都是文本的时候更为明显。事实上,Select Values在转化的效率上也高于读取时直接转化。
2.3 使用复制并行处理某个步骤
现在的机器都是多核的,使用多CPU并行处理对CPU使用密集的步骤可以提升ETL的执行效率。
在需要并行处理的步骤上,选择Change Number of Copies to Start, 修改这个值为小于机器核心总数的一个值,一般2〜4就可以满足要求。
2.4 KTR中,尽量减少步骤的数量
步骤的数量会在影响KTR的执行效率,包含并行处理时复制的数量。KTR中步骤的数量为机器核心总数的3〜4倍最佳,如果超过这个范围,可以考虑通过减少步骤数量的方式以提高KTR的执行效率。
2.5 不要在Select Values的步骤删除某个字段
如果在Select Values的步骤删除某个字段,kettle会需要调整现有的存储结构,在可以不删除的时候尽量不要删除字段。
3. 日志和监控
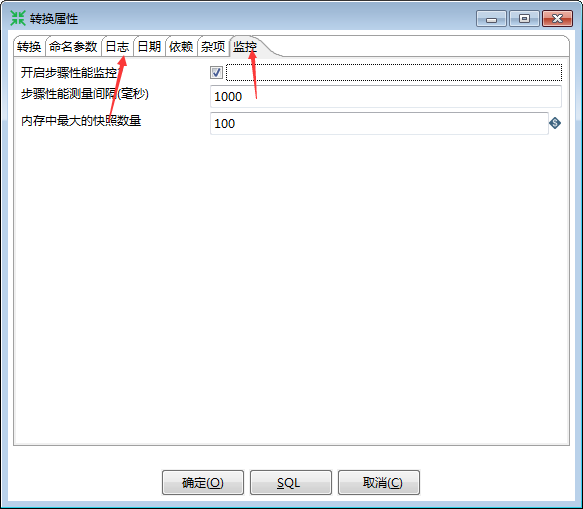
通过监控知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,通过观察kettle log生成的方式来了解你的ETL操作最慢的地方。
4. 其他优化
- Kettle是Java语言实现的,尽量用大一点的内存参数启动Kettle
- 使用Carte管理KJB和KTR减小内存消耗
- 使用定时器定时处理
- 使用集群并行运行
- 使用数据仓库及缓慢更新进行同步增量更新
- 远程数据库用文件+FTP的方式来传数据,文件要压缩
总结下来,当初技术选型时选定Kettle听到了一些担心,如开源工具本身的不稳定,大数据量下的低效,吃内存问题等,使用下来,Kettle这个工具本身还是不错的,但是设计中需要注意对包括数据库本身、ETL步骤、SQL及组件使用、内存使用的预估、监控等方面尽最大可能、全方位的考虑与优化。
参考: