
原文链接:https://arxiv.org/pdf/1904.08920
Task
VQA (visual question answering) 是视觉推理的一个方向,给定图片和与图片相关的问题,期望得 到问题的答案。现有模型在VQA数据集上效果较好,但在VQA的一个子任务上表现不佳。这个子任务是 与提取图片中文本有关的VQA,答案通常与图片中的文本相关(对识别文本进行筛选,或者基于识别文本生成回答)。
Dataset
为了解决这个任务,研究者基于Open Images提出了TextVQA数据集,对前者中的图片提出了各种需要识别文本才能解决的问题以及相应的答案。

图中为TextVQA数据集中的部分数据示例。研究者将现有的VQA模型在该数据集上运行,正确率仅有14%左右,可见该任务仍有很大的研究价值。

上图为数据集中对于问题长度、答案长度、文本数目、常见问题、常见回答等的统计图。
问题的答案可能直接来自文本提取结果,也可能需要模型自己生成,后者需要给定一个答案空间,对应VQA领域普遍的方法,但对于答案空间中未出现的、图片中出现的文本,现有VQA模型表现不佳。
图片中的文本提取对应OCR(optical character recognition),是一项研究历史比较久的领域,并已经有了很多成熟方法。因此TextVQA的主要难点在于根据问题选择答案应该来自OCR结果还是答案空间,并在OCR结果或答案空间中选择答案。
基于此,作者提出了LoRRA(look, read, reason and answer)模型。
Model
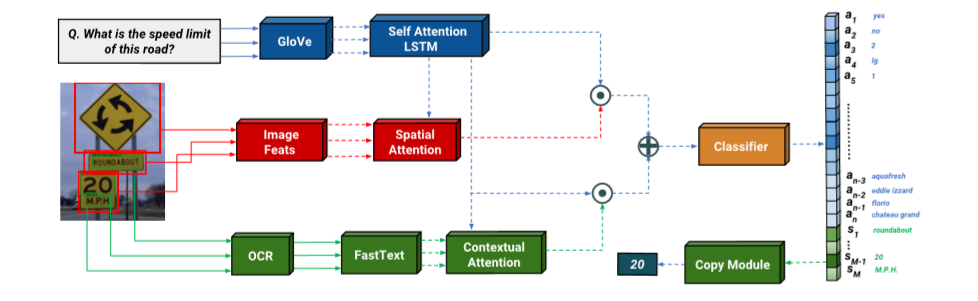
如图,模型分为VQA部分、读取部分和回答部分。VQA部分根据问题对图片提取的特征进行注意力加权,对应传统VQA;读取部分根据问题对OCR结果进行注意力加权;回答部分根据前两部分的结果输出答案。
VQA部分
本部分基于VQA竞赛的冠军模型Pythia。首先通过GloVe对问题q进行解析,得到词嵌入(embedding),然后经过LSTM得到问题的嵌入fQ(q),用于后续对图片特征以及OCR样本进行注意力加权平均。
图片的空间特征分别经过了grid-based和region-based两种方式提取,前者使用了ResNet152,后者使用了Faster R-CNN。提取的特征fI(v)与fQ(q)一起经过注意力机制得到加权的空间注意力,得到的结果与fQ(q)进行组合。整体计算过程可以写为:
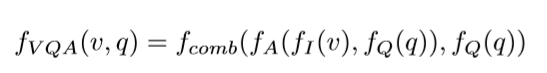

fVQA(v,q)随后经过全连接层MLP生成答案空间上a1~aN的概率分布p1~pN。
读取部分
读取部分中OCR基于Rosetta OCR模型(核心为Faster R-CNN和全卷积模型CTC)。
后续部分与VQA部分类似,区别在于将fI(v)更换为OCR结果fO(s)。虽然fA和fcomb与VQA部分结构一致,但参数是独立训练的。
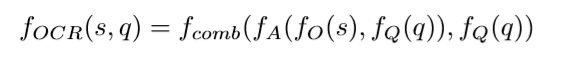
此外,上述过程中忽略了OCR结果的顺序信息,因此将OCR的注意力权重与上述结果拼接在一起,以向模型提供原始OCR结果的顺序信息。
回答部分
回答部分决定答案来源,包括答案空间a1~aN以及OCR结果s1~sM,如果来自OCR结果则使用复制模块输出答案。计算过程写为
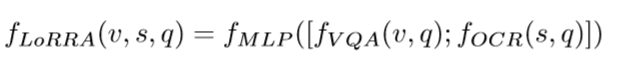
其中";"代表拼接。经过MLP后对于答案空间a1~aN以及OCR结果s1~sM分别进行log运算(而非softmax),以应对答案同时在答案空间以及OCR结果中的可能。
注意对于部分问题,答案需要组合多个OCR结果,这方面本篇论文没有解决,留作未来工作。
Experiment

作者衡量了启发性基准(左图)以及训练模型(右图)的准确率。
左图从上到下依次为人类表现、只从OCR预测的上限(预测一定正确)、只从LA(大词汇表)预测的上限、LA+OCR预测的上限、从最常见的100个答案中随机采样、从最常见的100个答案中按频率采样、始终预测最常见答案(即"yes")、从相应图的OCR结果中随机采样、从相应图的OCR结果中选择频率最高的结果。LA+OCR UB的准确率代表TextVQA的研究仍然有很大的进步空间。
右图为Ablation,从上到下分别为只有fQ(q)、只有fI(v)、Pythia(VQA部分)、Pythia+OCR、Pythia+OCR+复制模块、Pythia+LoRRA、Pythia+LoRRA+SA(小词汇表)、BAN、BAN+LoRRA,可见LoRRA取得了最佳性能,达到了27%左右的正确率。
实验的具体细节如学习率大小、迭代次数等参见原文。
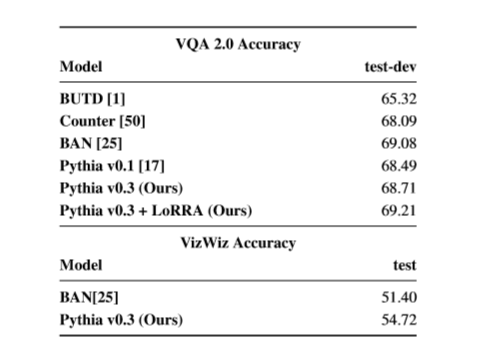
研究者还发现LoRRA模型能够提升Pythia在原有的VQA数据集上的准确率,可见TextVQA的任务有助于提升VQA模型对于图像的理解。

研究者最后给出了LoRRA模型在TextVQA数据集上的部分预测结果以及答案来源,绿色为正确,蓝色为部分正确,红色为错误。