摘要
新闻推荐系统中,新闻具有很强的动态特征(dynamic nature of news features),目前一些模型已经考虑到了动态特征。
一:他们只处理了当前的奖励(ctr);、
二:有一些模型利用了用户的反馈,如用户返回的频率。(user feedback other than click / no click labels (e.g., how frequentuser returns) );
三:会给用户推送一些内容类似的新闻,用户看多了会无聊。
为了解决上述问题,我们提出了DQR,明确处理未来的奖励。为了获取更多的用户反馈信息,我们使用user return pattern 作为用户点击的补充,
同时也包含了探索特性去发现用户的兴趣。
1 INTRODUCTION
新闻太多啦,每个人都看不完,所以新闻推荐太有必要啦。新闻推荐技术总结如下:
content based methods [19, 22, 33],
collaborative fltering based methods [11, 28 ,34]
hybrid methods [12, 24, 25]
---------------------------------
deep learning models [8, 45, 52]
然而上述方法面临3个挑战
1、the dynamic changes in news recommendations are difcult to handle
1- 新闻很快 outdated. 新闻候选集变化很快。
2-用户在不同新闻上的兴趣也会不断变化,因此需要定期更新模型。尽管有一些在想模型可以捕获动态特征,但是只是最优化当前的奖励(ctr)
忽略了当前的推荐会对未来产生影响。
2、current recommendation methods [23, 35, 36, 43] usually only consider the click / no click labels or ratings as users’ feedback.
3、its tendency to keep recommending similar items to users, which might decrease users’ interest in similar topics.
一些方法加入了一些随机 比如,simple ϵ-greedy strategy [31] or Upper Confdence Bound (UCB) [23, 43] (mainly for Multi-Armed Bandit methods)
ϵ-greedy strategy may recommend the customer with totally unrelated items
UCB can not get a relatively accurate reward estimation for an item until this item has been tried several times
因此,提出了自己的模型,DQN 可以考虑当前的奖励与未来的奖励。
Second, we consider user return as another form of user feedback information, by maintainingan activeness score for each user ,
我们不是考虑最近的信息,我们考虑的是历史上的信息。
Third, we propose to apply a Dueling Bandit Gradient Descent (DBGD) method [16, 17, 49] for exploration, by choosing random item candidates in the neighborhood of the current recommender.

environment :user+news
state被定义为用户的特征表示,action被定义为新闻的特征表示。
每一个时刻,当用户想看新闻的时候,一个state(i.e., features of users) 和 action集合(i.e., features of news candidates)会传给agent.
The agent 会选择最好的action(i.e., recommending a list ofnews to user) 并且 得到用户的feedback作为reward。Specifcally ,reward 是
click label 与 用户活跃度的估计(estimation of user activeness )构成。
所有的推荐与feedback会存在memory里,每个小时更新算法。
创新点如下:
1、提出dqn用在新闻推荐,考虑了当前的奖励与未来的奖励。
2、用户活跃度辅助我们提高推荐准确率。
3、更有效的exploration 机制, Dueling Bandit Gradient Descent
4、已经在某应用中上线,效果好。
2 RELATED WORK
2.1 News recommendation algorithms
Conventional news recommendation methods can be divided into three categories.
1、Content-based methods [19, 22, 33] 使用 news term frequency features (e.g., TF-IDF) 和 用户画像(based on historical news),然后,选择跟用户画像相似的新闻进行推荐。
2、 collaborative fltering methods [11] usually make rating prediction utilizing the past ratings of current user or similar users [28, 34], or the combination of these two [11]
3、To combine the advantages of the former two groups of methods, hybrid methods [12, 24, 25] are further proposed to improve the user profle modeling.
4、deep learning models [8, 45, 52] have shown much superior performance than previous three categories of models due to its capability of modeling complex user-item relationship
2.2 Reinforcement learning in recommendation
2.2.1 Contextual Multi-Armed Bandit models
context 包括用户的特征跟 item的特征,论文【23】假设rewrad是context的函数。
2.2.2 Markov Decision Process models
capture the reward of current iteration, but also the potential reward in the future iterations
之前的模型是离散的,比较难train,我们的模型是连续的。
4.1 Model framework 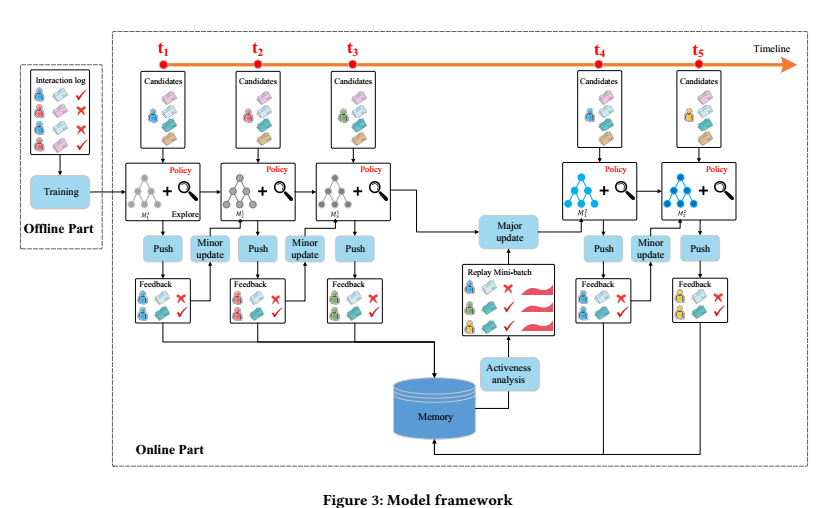
离线: 提取了4种特征( from news and users),用DQN预测 reward(.e., a combination of user-news click label and user activeness). 使用离线的点击日志训练。
在线:
1 push:
在每个 timestamp (t1, t2, t3, t4, t5, ...), 用户提出请求,agent根据输入(user feature 和 news candidates)产生 L top-k 个list of news(模型产生的 + exploration)
2 feedback
用户根据 L 返回点击情况。
3 minor update
在每个timestamp, 根据上一个用户u ,推荐列表 L,feedback B , agent G 通过比较 Q and Q˜ 的 performance来更新参数。
If Q˜ better recommendation result, the current network will be updated towards Q˜ . Otherwise, Q will be kept unchanged
4 major update
TR时刻后,G根据用户的feedback与memory中的活动记录,利用经验回放技术,更新Q.
(5) Repeat step (1)-(4)
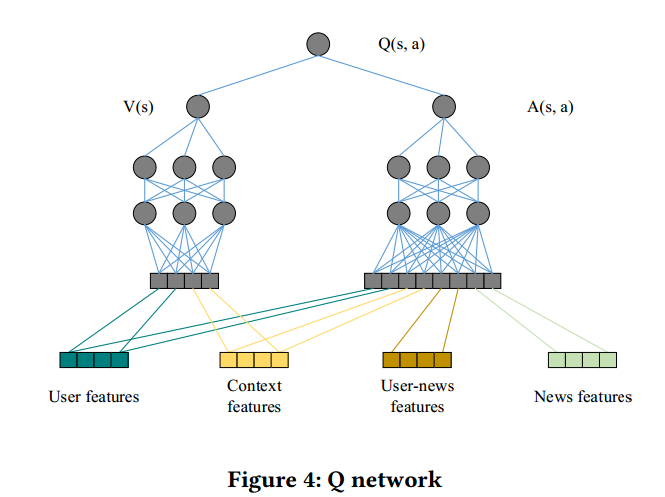
4.2 Feature construction
• News features includes 417 dimension one hot features that describe whether certain property appears in this piece ofnews,
including headline, provider, ranking, entity name,category, topic category, and click counts in last 1 hour, 6 hours, 24 hours, 1 week, and 1 year respectively.
新闻的特征:包括题目,作者,排名,类别等等,共417维
• User features mainly describes the features (i.e., headline, provider, ranking, entity name, category, and topic category) of the news that the user clicked in 1 hour, 6 hours, 24 hours,
1 week, and 1 year respectively. There is also a total click count for each time granularity. Therefore, there will be totally 413 × 5 = 2065 dimensions.
用户的特征:包括用户在1小时,6小时,24小时,1周,1年内点击过的新闻的特征表示,共413*5=2065维。
• User news features. These 25-dimensional features describe the interaction between user and one certain piece of news,
i.e., the frequency for the entity (also category, topic category and provider) to appear in the history of the user’s readings.
• Context features. These 32-dimensional features describe the context when a news request happens, including time, weekday,
and the freshness of the news (the gap between request time and news publish time).
上下文特征:32维的上下文信息,如时间,周几,新闻的新鲜程度等
在这四组特征中,用户特征和上下文特征用于表示当前的state,新闻特征和交互特征用语表示当前的一个action。
4.3 Deep Reinforcement Recommendation
这里深度强化学习用的是Dueling-Double-DQN。
将用户特征和上下文特征用于表示当前的state,新闻特征和交互特征用语表示当前的一个action,经过模型可以输出当前状态state采取这个action的预测Q值。
Q现实值包含两个部分:立即获得的奖励和未来获得奖励的折现:

rimmediate 代表 rewards (用户是否点击了this piece of news)
DDQN 公式:

4.4 User Activeness
传统方法只考虑ctr。用户活跃度也行重要。 是本文提出的新的可以用作推荐结果反馈的指标。用户活跃度可以理解为使用app的频率,好的推荐结果可以增加用户使用该app的频率,因此可以作为一个反馈指标。
如果用户在一定时间内没有点击行为,活跃度会下降,但一旦有了点击行为,活跃度会上升。
在考虑了点击和活跃度之后,之前提到过的立即奖励变为:

4.5 Explore
本文的探索采取的是Dueling Bandit Gradient Descent 算法,算法的结构如下:
在DQN网络的基础上又多出来一个exploration network Q ̃ ,这个网络的参数是由当前的Q网络参数基础上加入一定的噪声产生的,具体来说:
当一个用户请求到来时,由两个网络同时产生top-K的新闻列表,然后将二者产生的新闻进行一定程度的混合,然后得到用户的反馈。如果exploration network Q ̃的效果好的话,那么当前Q网络的参数向着exploration network Q ̃的参数方向进行更新,具体公式如下:
否则的话,当前Q网络的参数不变。
总的来说,使用深度强化学习来进行推荐,同时考虑了用户活跃度和对多样性推荐的探索,可以说是一个很完备的推荐框架了!
参考:
https://blog.csdn.net/r3ee9y2oefcu40/article/details/82880302
http://www.personal.psu.edu/~gjz5038/paper/www2018_reinforceRec/www2018_reinforceRec.pdf