sleuth + zipkin 链路分析
sleuth 链路跟踪
随着系统规模越来越大,微服务之间调用关系变得错综复杂,一条调用链路中可能调用多个微服务,任何一个微服务不可用都可能造整个调用过程失败
spring cloud sleuth 可以跟踪调用链路,分析链路中每个节点的执行情况
1. 添加 sleuth 依赖
在每个服务和zuul项目中添加sleuth依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
然后我们使用zuul访问业务层, 就能看到业务的调用流程, 会看到链路访问控制台的输出信息
[服务id,请求id,span id,是否发送到zipkin]
- 请求id:请求到达第一个微服务时生成一个请求id,该id在调用链路中会一直向后面的微服务传递
- span id:链路中每一步微服务调用,都生成一个新的id
[zuul,6c24c0a7a8e7281a,**6c24c0a7a8e7281a**,false]
[order-service,6c24c0a7a8e7281a,**993f53408ab7b6e3**,false]
[item-service,6c24c0a7a8e7281a,**ce0c820204dbaae1**,false]
[user-service,6c24c0a7a8e7281a,**fdd1e177f72d667b**,false]
zipkin 链路分析
zipkin 可以收集链路跟踪数据,提供可视化的链路分析
分析可分为2中:
- 使用消息队列转发 (推荐)
- 使用zipkin直接获取
使用RabbitMQ转发图解:
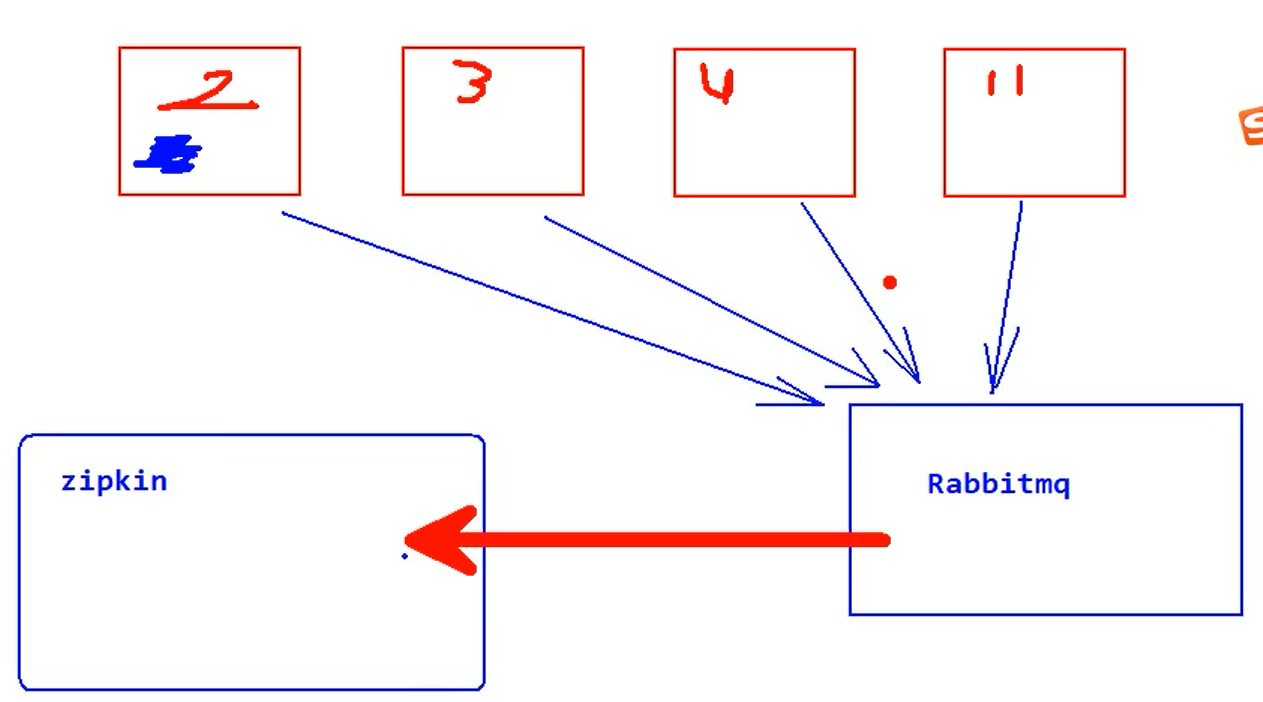
zipkin相当于RabbitMQ的消费者, 其他业务服务为提供者
链路数据抽样比例
默认 10% 的链路数据会被发送到 zipkin 服务。可以配置修改抽样比例
spring:
sleuth:
sampler:
probability: 0.1
准备前提
已经导入了sleuth链路跟踪的依赖
1. 添加依赖
添加两个依赖到服务器和zuul项目中Zipkin Client, Spring for RabbitMQ
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
如果配置了spring cloud bus依赖, 无序再添加RabbitMQ的依赖
2. 配置文件
在业务服务和zuul配置文件中假如RabbitMQ的配置和zipkin的转发类型配置
如果不配置zipkin的转发类型, 默认是直接获取业务服务的调用信息, 配置了rabbitMQ会使用RabbitMQ转发获取
spring
rabbitmq:
host: aarons.top
port: 5672
username: admin
password: admin
# virtual-host: /wht
zipkin:
sender:
type: rabbit # zipkin发送类型
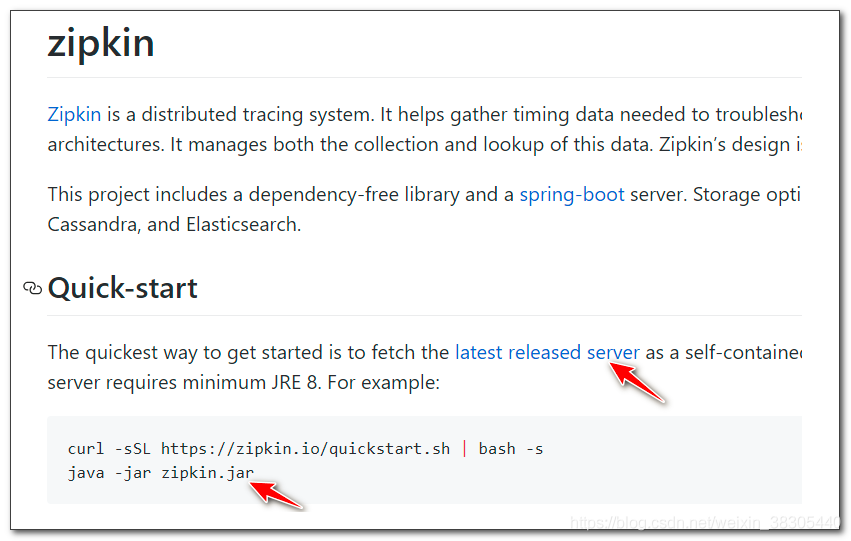
3. 下载zipkin服务器
github: https://github.com/openzipkin/zipkin
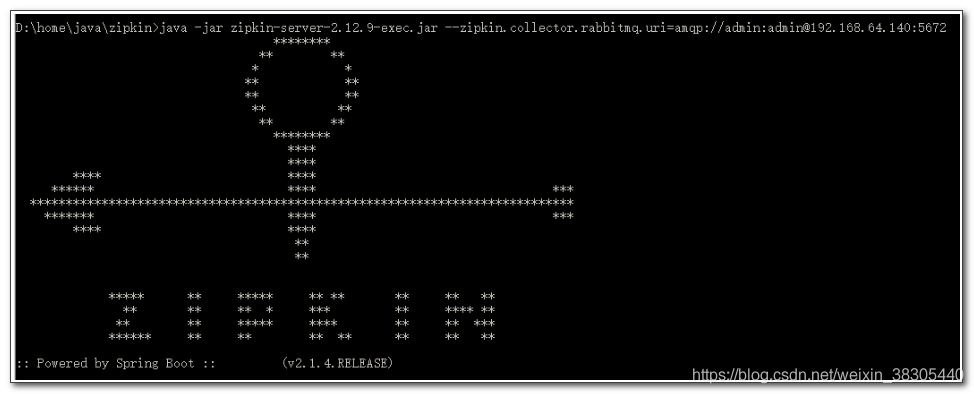
4. 启动zipkin
启动 zipkin 时,连接到 rabbitmq
使用命令启动下载下来的jar包 (一行命令, ip和端口, 用户名密码等改为自己的RabbitMQ的相关信息)
java -jar zipkin-server-2.12.9-exec.jar --zipkin.collector.rabbitmq.uri=amqp://admin:admin@192.168.64.140:5672
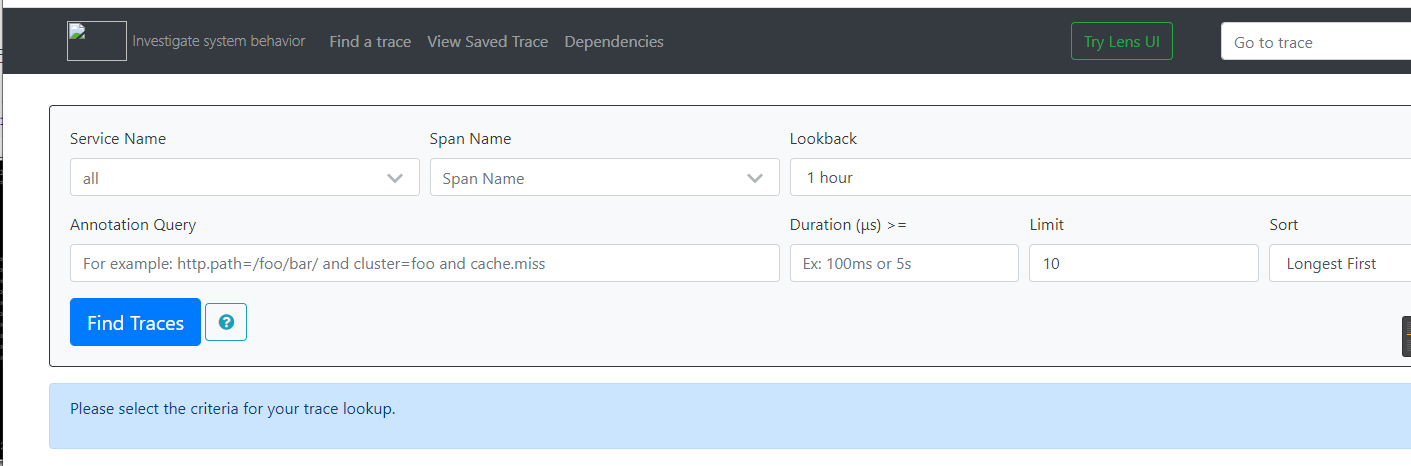
5. 访问zipkin页面
http://localhost:9411/zipkin/ 修改为自己的ip进行访问
6. 测试
访问zuul来访问其他的服务业务, 然后登陆RabbitMQ, 如果有数据波动, 说明配置成功