Storm基本概念
Storm是一个开源的实时计算系统,它提供了一系列的基本元素用于进行计算:Topology、Stream、Spout、Bolt等等。
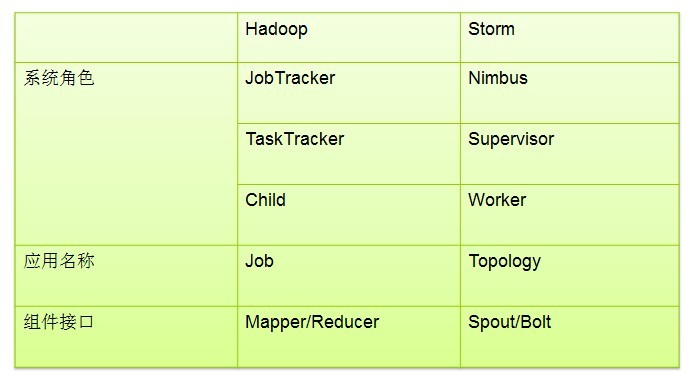
在Storm中,一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapReduce任务相似。但是有一点不同的是:在Hadoop中,MapReduce任务最终会执行完成后结束;而在Storm中,Topology任务一旦提交后永远不会结束,除非你显示去停止任务。
计算任务Topology是由不同的Spouts和Bolts,通过数据流(Stream)连接起来的图。下面是一个Topology的结构示意图:

其中包含有:
Spout:Storm中的消息源,用于为Topology生产消息(数据),一般是从外部数据源(如Message Queue、RDBMS、NoSQL、Realtime Log)不间断地读取数据并发送给Topology消息(tuple元组)。
Bolt:Storm中的消息处理者,用于为Topology进行消息的处理,Bolt可以执行过滤, 聚合, 查询数据库等操作,而且可以一级一级的进行处理。
最终,Topology会被提交到storm集群中运行;也可以通过命令停止Topology的运行,将Topology占用的计算资源归还给Storm集群。
Storm数据流模型
数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的tuple元组序列。在Topology中,Spout是Stream的源头,负责为Topology从特定数据源发射Stream;Bolt可以接收任意多个Stream作为输入,然后进行数据的加工处理过程,如果需要,Bolt还可以发射出新的Stream给下级Bolt进行处理。
下面是一个Topology内部Spout和Bolt之间的数据流关系:

Topology中每一个计算组件(Spout和Bolt)都有一个并行执行度,在创建Topology时可以进行指定,Storm会在集群内分配对应并行度个数的线程来同时执行这一组件。
那么,有一个问题:既然对于一个Spout或Bolt,都会有多个task线程来运行,那么如何在两个组件(Spout和Bolt)之间发送tuple元组呢?
Storm提供了若干种数据流分发(Stream Grouping)策略用来解决这一问题。在Topology定义时,需要为每个Bolt指定接收什么样的Stream作为其输入(注:Spout并不需要接收Stream,只会发射Stream)。
目前Storm中提供了以下7种Stream Grouping策略:Shuffle Grouping、Fields Grouping、All Grouping、Global Grouping、Non Grouping、Direct Grouping、Local or shuffle grouping,具体策略可以参考这里。
一种Storm不能支持的场景
以上介绍了一些Storm中的基本概念,可以看出,Storm中Stream的概念是Topology内唯一的,只能在Topology内按照“发布-订阅”方式在不同的计算组件(Spout和Bolt)之间进行数据的流动,而Stream在Topology之间是无法流动的。

这一点限制了Storm在一些场景下的应用,下面通过一个简单的实例来说明。
假设现在有一个Topology1的结构如下:通过Spout产生数据流后,依次需要经过Filter Bolt,Join Bolt,Business1 Bolt。其中,Filter Bolt用于对数据进行过滤,Join Bolt用于数据流的聚合,Business1 Bolt用于进行一个实际业务的计算逻辑。

目前这个Topology1已经被提交到Storm集群运行,而现在我们又有了新的需求,需要计算一个新的业务逻辑,而这个Topology的特点是和Topology1公用同样的数据源,而且前期的预处理过程完全一样(依次经历Filter Bolt和Join Bolt),那么这时候Storm怎么来满足这一需求?据个人了解,有以下几种“曲折”的实现方式:
1) 第一种方式:首先kill掉已经在集群中运行的Topology1计算任务,然后实现Business2 Bolt的计算逻辑,并重新打包形成一个新的Topology计算任务jar包后,提交到Storm集群中重新运行,这时候Storm内的整体Topology结构如下:

这种方式的缺点在于:由于要重启Topology,所以如果Spout或Bolt有状态则会丢失掉;同时由于Topology结构发生了变化,因此重新运行Topology前需要对程序的稳定性、正确性进行验证;另外Topology结构的变化也会带来额外的运维开销。
2) 第二种方式:完全开发部署一套新的Topology,其中前面的公共部分的Spout和Bolt可以直接复用,只需要重新开发新的计算逻辑Business2 Bolt来替换原有的Business1 Bolt即可。然后重新提交新的Topology运行。这时候Storm内的整体Topology结构如下:

这种方式的缺点在于:由于两个Topology都会从External Data Source读取同一份数据,无疑增加了External Data Source的负载压力;而且会导致同样的数据在Storm集群内被传输相同的两份,被同样的计算单元Bolt进行处理,浪费了Storm的计算资源和网络传输带宽。假设现在不止有两个这样的Topology计算任务,而是有N个,那么对Storm的计算Slot的浪费很严重。
注意:上述两种方式还有一个公共的缺点——系统可扩展性不好,这意味着不管哪种方式,只要以后有这种新增业务逻辑的需求,都需要进行复杂的人工操作或线性的资源浪费现象。
3) 第三种方式:OK,看了以上两种方式后,也许你会提出下面的解决方案:通过Kafka这样的消息中间件,实现不同Topology的Spout共享数据源,而且这样可以做到消息可靠传输、消息rewind回传等,好处是对于Storm来说,已经有了storm-kafka插件的支持。这时候Storm内的整体Topology结构如下:

这种实现方式可以通过引入一层消息中间件减少对External Data Source的重复访问的压力,而且可以通过消息中间件层,屏蔽掉External Data Source的细节,如果需要扩展新的业务逻辑,只需要重新部署运行新的Topology,应该说是现有Storm版本下很好的实现方式了。不过消息中间件的引入,无疑将给系统带来了一定的复杂性,这对于Storm上的应用开发来说提高了门槛。
值得注意的是,方案三中仍遗留有一点问题没有解决:对于Storm集群来说,这种方式还是没有能够从根本上避免数据在Storm不同Topology内的重复发送与处理。这是由于Storm的数据流模型上的限制所导致的,如果Storm实现了不同Topology之间Stream的共享,那么这一问题也就迎刃而解了。
一个流处理系统的数据流模型
个人工作中有幸参与过一个流处理框架的开发与应用。下面我们来简单看看其中所采用的数据流模型:

其中:
1)数据流(data stream):时间分布和数量上无限的一系列数据记录的集合体;
2)数据记录(data record):数据流的最小组成单元,每条数据记录包括 3 类数据:所属数据流名称(stream name)、用于路由的数据(keys)和具体数据处理逻辑所需的数据(value);
3)数据处理任务定义(task definition):定义一个数据处理任务的基本属性,无法直接被执行,必须特化为具体的任务实例。其基本属性包括:
- (可选)输入流(input stream):描述该任务依赖哪些数据流作为输入,是一个数据流名称列表;数据流产生源不会依赖其他数据流,可忽略该配置;
- 数据处理逻辑(process logic):描述该任务具体的处理逻辑,例如由独立进程进行的外部处理逻辑;
- (可选)输出流(output stream):描述该任务产生哪个数据流,是一个数据流名称;数据流处理链末级任务不会产生新的数据流,可忽略该配置;
4)数据处理任务实例(task instance):对一个数据处理任务定义进行具体约束后,可推送到某个处理结点上运行的逻辑实体。附加下列属性:
- 数据处理任务定义:指向该任务实例对应的数据处理任务定义实体;
- 输入流过滤条件(input filting condition):一个 boolean 表达式列表,描述每个输入流中符合什么条件的数据记录可以作为有效数据交给处理逻辑;若某个输入流中所有数据记录都是有效数据,则可直接用 true 表示;
- (可选)强制输出周期(output interval):描述以什么频率强制该任务实例产生输出流记录,可以用输入流记录个数或间隔时间作为周期;忽略该配置时,输出流记录产生周期完全由处理逻辑自身决定,不受框架约束;
5)数据处理结点(node):可容纳多个数据处理任务实例运行的实体机器,每个数据处理结点的IPv4地址必须保证唯一。
该分布式流处理系统由多个数据处理结点(node)组成;每个数据处理结点(node)上运行有多个数据任务实例(task instance);每个数据任务实例(task instance)属于一个数据任务定义(task definition),任务实例是在任务定义的基础上,添加了输入流过滤条件和强制输出周期属性后,可实际推送到数据处理结点(node)上运行的逻辑实体;数据任务定义(task definition)包含输入数据流、数据处理逻辑以及输出数据流属性。
该系统中,通过分布式应用程序协调服务ZooKeeper集群存储以上数据流模型中的所有配置信息;不同的数据处理节点统一通过ZooKeeper集群获取数据流的配置信息后进行任务实例的运行与停止、数据流的流入和流出。
同时,每个数据处理任务可以接受流系统中已存在的任意数据流(data stream)作为输入,并产出新的任意名称的数据流(data stream),被其他结点上运行的任务实例订阅。不同结点之间对于各个数据流(data stream)的订阅关系,通过ZooKeeper集群来动态感知并负责通知流系统做出变化。
二者在数据流模型上的不同之处
至于两个系统的实现细节,我们先不去做具体比较,下面仅列出二者在数据流模型上的一些不同之处(这里并不是为了全面对比二者的不同之处,只是列出其中的关键部分):
1) 在Storm中,数据流Stream是在Topology内进行定义,并在Topology内进行传输的;而在上面提到的流处理系统中,数据流Stream是在整个系统内全局唯一的,可以在整个集群内被订阅。
2) 在Storm中,数据流Stream的发布和订阅都是静态的,所谓静态是指数据流的发布与订阅关系在向Storm集群提交Topology计算任务时,被一次性生成的,这一关系在Topology的运行过程中是不能被改变的;而在上面提到的流处理系统中,数据流Stream的发布和订阅都是动态的,即数据处理任务task可以动态的发布Stream,也可以动态的订阅系统内已经生成的任意Stream,数据流的订阅关于通过分布式应用程序协调服务ZooKeeper集群的动态节点来维护管理。
有了以上的对比,我们不难发现,对于本文所举的应用场景实例,Storm的数据流模式尚不能很方便的支持,而在这里提到的这个流处理系统的全局数据流模型下,这一应用场景的需求可以很方便的满足。
1.什么是Topology?
2.如何创建Topology?
3.Topology的worker数由谁来配置?
4.Topology中某个bolt的executor数由谁来指定?
5.Supervisor、worker、Executor、Task、Spout、Bolt之间的关系?![]()
在创建Storm的Topology时,我们通常使用如下代码:
builder.setBolt("cpp", new CppBolt(), 3).setNumTasks(5).noneGrouping(pre_name);
Config conf = new Config();
conf.setNumWorkers(3);
参数1:bolt名称 "cpp"
参数2:bolt类型 CppBolt
参数3:bolt的并行数,parallelismNum,即运行topology时,该bolt的线程数
setNumTasks() 设置bolt的task数
noneGrouping() 设置输入流方式及字段
conf.setNumWorkers()设置worker数据。
经过多次试验总结,得出如下结论:
1)Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过storm rebalance 命令任意调整。
2) Topology中某个bolt的executor数,即parallelismNum,即执行该bolt的线程数,在setBolt时由第三个参数指定。它可以通过storm rebalance 命令调整,但最大不能超过该bolt的task数;
3) bolt的task数,通过setNumTasks()设置。(也可不设置,默认取bolt的executor数),无法在运行时调整。
4)Bolt实例数,这个比较特别,它和task数相等。有多少个task就会new 多少个Bolt对象。而这些Bolt对象在运行时由Bolt的thread进行调度。也即是说
builder.setBolt("cpp", new CppBolt(), 3).setNumTasks(5).noneGrouping(pre_name);
会创建3个线程,但有内存中会5个CppBolt对象,三个线程调度5个对象。
每台Supervisor上运行着若干个worker进程,在Configure对象中可以配置worker的数量,conf.setNumWorkers(number);
每个Workder进行上运行着若干个Executor执行线程,就是所谓的Task任务。
在TopologyBuilder对象中可以配置Task的数量,topologyBuilder.setNumTasks(number);这些Task任务指的是Spout或者Bolt任务。
在TopologyBuilder对象中可以配置Spout、Bolt的任务的数量。
topologyBuilder.setSpout(“spout tag name”,new XxSpout(),number);
topologyBuilder.setBolt(“bolt tag name”,new XxBolt(),number);
默认情况下# executor = #tasks即一个Executor中运行着一个Task。Spout或者Bolt的Task个数一旦指定之后就不能改变了,而Executor的数量可以根据情况来进行动态的调整。
一句话介绍,每台worker node上可以运行很多个worker,每个worker会开辟很多Executor线程来执行Task。在Storm看来,spout和bolt都是task。