Flink是什么?
Flink是一个以Java及Scala作为开发语言的开源大数据项目,代码开源在github上,并使用 maven来编译和构建项目。其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序。一句话总结是一个流式计算的maven工程。
开发环境准备?
1 java环境: jdk 环境变量 2 maven环境 3 编辑器 idea or eclipse
基础的API ?
引用官方图片 

如何构建自己的第一个flink项目?
1) flink官网上有wordCount的例子可以自己下
2) 自己搭建 先搭建一个maven项目;
大体流程:ExecutionEnvironment (环境) ->DataStream or DataSet(接收流) -> fliter(过滤)->map(数据结构转换)---->keyBy(分流)--->window or process(业务代码)--->sink(输出)
注意:env.execute() 不能忘记,类似于线程的start
2.1) maven依赖引入
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
2.2)写自己的程序主类,并添加main方法

2.3)按flink套路来
准备环境:
ParameterTool params = ParameterTool.fromArgs(args);
//环境
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
准备环境(读哪里的数据? file kafka ???、):
读取数据flink提供了jar包如下
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>${flink.version}</version>
<scope> compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
接收数据(DataStream or DataSet 有界(固定大小)和无界(一直在增加或者写入)):
代码:kafka 
file: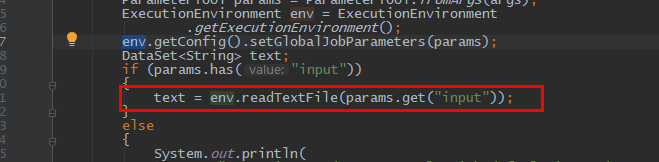
输出: print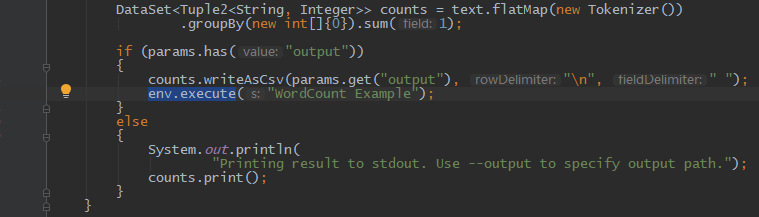
addSink: