经过前面五篇排序方法的介绍,我们了解到了递归思想以及分而治之的归并和快速排序,当然也涉及到了比较简单易懂的数据值传递冒泡,选择,以及插入排序。可以说每一种排序方式都各有千秋,都适合在不同的环境下进行使用,但是我们有时会不会思考一个问题,那就是我们在学习插入排序的时候的主题思想是将每一个数据取出来,然后和后边的前边的数据逐一进行比较,那么,我们是不是要进行N-1次的循环,或者说我们是不是要进行大约N的平方次比较,我们知道,在进行值的交换和比较是非常消耗时间的,那么是不是违背了我们算法的发展。有没有更好的方式去进行解决,在数据量浩大的时候,我们能否对插入进行修改,到达一个理想的结果。那么,我们将要介绍的希尔排序应运而生,如果你对插入排序不是很了解,那么我建议去看完插入排序再来看希尔排序,在我的认知里,希尔排序或者可以说成是插入排序的升级版,他用到的核心思想还是插入排序。我们前边就提到了分而治之的思想,在数据量浩大的时候,我们可不可以提取出其中的一部分作为一个小组,然后有N个小组,我们队这些小组进行排序,那么总体的数组我们可不可以看成是一个间断有序的数组,然后我们在进行整体的插入的时候我们是不是能避免很多次重复的比较,或者说是数据交换。所以,如果你看到这的时候,应该能够理解希尔排序,其实就是将一个整体单元化,进行预处理,然后再进行整体的处理,这和归并排序是不是有点不谋而合,分而治之。说话不能理解,那我们直接上图:
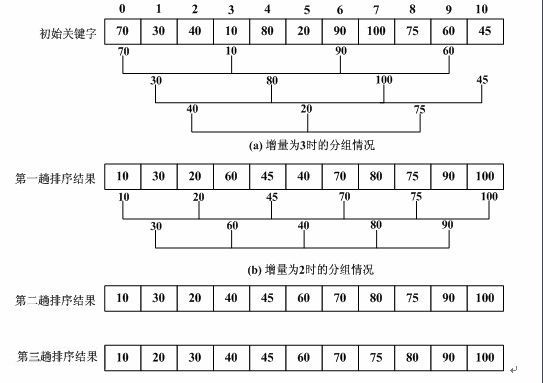
我们可以看到上图诉说的思想,我们选取的单元大小与我们的步长有关,也就是说我们的步长有多上种,那么我们就对这个数组进行过几次预处理,在这样的情况下,始终我们的步长会得到1,那么也就是说我们在进行最后的插入排序的时候是不是进行过必要的处理,那么我们将在最后;排序时使用最少的数据交换和比较。可以这么说,希尔排序为什么在处理大量数据是会比插入排序优秀,那也是缩小数据量以及让数据间断性的有序,减少其比较和交换数据的次数。举一个见到的例子,我们很不幸运,最后一个数据是最小的值,如果我们继续使用插入排序是不是意味着我们y要进行N-1次的比较,消耗的时间对于我们来说有一点不能接受,如果我们按照上图所示,进行一定步长的比较,让间断性有序,是不是会减少大量的比较步骤,代码奉上:
1 public static void shellSort(int arr[]){ 2 int n = arr.length; 3 //选择步长 4 for(int gap = n / 2;gap >= 1;gap /= 2){ 5 //选择组别 6 for(int i = 0;i < gap;i++){ 7 //需要进行插入的key值 8 for(int j = i + gap;j < n;j += gap){ 9 //对该值与前一个值进行比较,是否需要交换 10 if(arr[j] < arr[j - gap]){ 11 int key = arr[j]; 12 int k = j - gap; 13 while(k >= 0 && key < arr[k]){ 14 //进行值交换 15 arr[k + gap] = arr[k]; 16 } 17 //选取出来的key值归位 18 arr[k + gap] = key; 19 } 20 } 21 } 22 } 23 }
我们从以上的代码能够更直观的感受到,其实希尔排序就是先把一个整体分成无数个单元片段,根据步长,然后对这些单元进行排序,达到间断性有序的效果,最后在进行整体的插入排序,我们可以看到,在进行第一个for循环,我们其实就是想要获取一个步长,步长是在不断缩短的,那就意味着整体的分组在不断减少,直到为一结束。然后我们在第二个循环选取出不同的分组,其实这是我的理解,也可以说是根据不同的起始值加上步长也就获取了一定量的数据作为一个组别的数据。在第三个循环我们就对这个小组的数据进行正常的插入排序,希尔排序就是一个具有一定步长的插入排序,我们可以这么理解!
需要注意的问题:
一:关于希尔排序步长的选择问题:
说实话,我对于这个问题确实有点不太了解,不太方便做出相应的解释,但是在我看的算法第四版书籍以及数据结构和算法中对于这个问题的阐述说的是选择N/3作为步长,但是大部分人都选择N/2作为步长,其实我们发现一个完美的步长能够帮助我们很多,但是很遗憾,我给出不了这个解释,有兴趣可以去看一下其它专业的解释。步长的选取和希尔排序的效率息息相关,我们知道这一点足矣。
二:关于希尔排序的代码优化:
如果我们可以用心留意,看见很多人对于希尔排序都有着浓厚的兴趣,进行尝试性的不断优化,但是,我想说的是,这样导致很多地方的希尔已经变形,抛离了主旨思想,其实我们在学习一种算法的时候在自己水平不够的情况下掌握最基准的解释翻译过来的代码即可,我上边的代码或许看起来比较复杂,但是应该是最容易理解的一种理解方式。抓住两个关键问题,对步长变化的控制,对于用步长为基准的单元片段进行插入排序的方法,这就是最基础的希尔排序,如果以后我的水平提升,再和大家讨论关于希尔问题的步长问题。