数组:
数组存储区间是连续的,占用内存严重,故空间复杂度很大,但数组的二分查找时间复杂度很小,为 o(1),数组的特点:查找速度快、插入和删除效率低
链表:
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,为 o(n),链表的特点:查找速度慢、插入和删除效率高
ArrayList:底层是数组,查询快(有索引),增删慢。
LinkedList:底层是单向链表,查询慢(无索引),增删块。
List集合:有序可重复。Set集合:无序不可重复。
哈希表HashTable:
综合了数组和链表的特性,不仅查找速度快,插入和删除的效率也很高
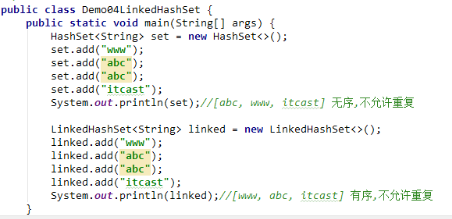
HashSet和HashTable:底层是哈希表(HashTable),即数组+链表+红黑树(链表超过8个就用红黑树),数组的初始容量为16。先把元素按照相同的hash值进行分组,再把相同哈希值的元素挂到一起,提高查询速度。是无序的集合。哈希表结构可以保证键唯一。
LinkedHashSet和LinkedHashMap:底层是哈希表+链表,是有序的集合。LinkedHashSet:底层是哈希表+链表,多了一条链表(记录元素的存储顺序),保证元素有序。
哈希表的实现方式----拉链法:
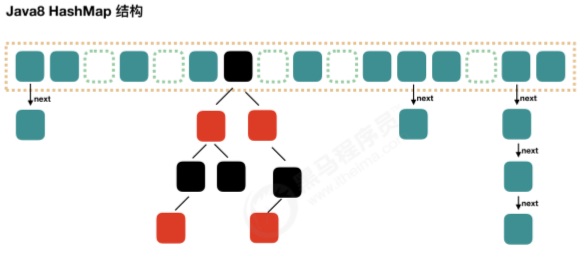
哈希表有多种不同的实现方式,下面我们就介绍一种最常用的方法——“拉链法”,就是我们理解的“链表的数组”,如下图所示:
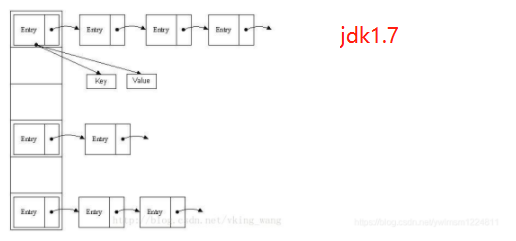
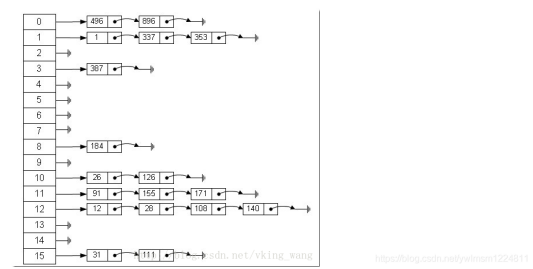
从上图可以看出,哈希表就是数组和链表组成的,一个长度为 16 的数组中,每个元素存储的是一个链表的头节点,这些元素是按照什么样的规则存储到数组的呢,一般是通过 hash(key)% len (也就是元素 key 的 hash 值对数组长度取模得到的)获得的,比如:12 % 16 = 12, 28 % 16 =12,108 % 16 = 12, 140 % 16 = 12,所以 12、28、108 和 140 都存储在数组下标为 12 的链表中
HashSet:无序不可重复
特点:
1、 不允许存储重复的元素。(List集合:有序可重复。Set集合:无序不可重复。)
2、 没有索引,没有带索引的方法,也不能使用普通的for循环遍历,可以用增强for循环和迭代器iterator。
3、是一个无序的集合,存储元素和取出元素的顺序有可能不一致。
4、底层是一个哈希表结构(查询的速度非常的快)
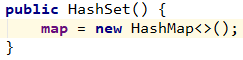
HashSet集合:底层是哈希表结构,HashSet 实际上是一个HashMap的实例,new的就是HashMap,但是只使用了Map集合中的Key,所以HashSet集合不允许存储重复元素。
Set集合不允许存储重复元素的原理:
前提:存储的元素必须重写hashCode()方法和equals()方法,如String、Integer。
Set集合在调用add方法的时候,add方法会调用元素的hashCode方法和equals方法,判断元素是否重复。add方法会调用对象的hashCode()计算对象的哈希值,然后在set集合中找是否有该哈希值的元素,如果没有,就会把该对象存储到集合中。如果set集合中有该哈希值的元素(hash冲突),则对象会调用equals方法和哈希值相同的元素进行比较,返回true的话,认定两个对象相同,就不会把对象存储到集合中。如果返回false,认定两个对象不相同,就会把对象存入集合中。

如果用HashSet集合存储自定义的对象,想要保证元素唯一,也要重写hashCode()和equals()。
哈希值:是一个十进制的整数,由系统随机给出(就是对象的地址值,是一个逻辑地址,是模拟出来的地址,不是数据实际存储的物理地址),是Jdk根据对象的地址/String/数字算出来一串数字(int)
获取hash值的方法:int hashCode(),返回对象的哈希码值。该方法是Object类的方法,所有类默认继承Object类。
若重写了hashCode()方法,你想返回多少就返回多少。若没有重写hashCode()方法,系统随机给一个地址值。
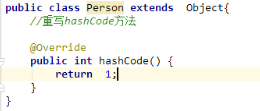
如果对象类型没有重写hashCode()方法,则两个内容相同的对象的哈希值是不同的,因为哈希值由系统随机给出。
如果对象类型没有重写equals方法,equals方法默认比较的是地址值,要想equals比较对象的内容,则要重写equals方法。
Person p1 = new Person('小美女',18);
Person p2 = new Person('小美女',18);
1、sout(p1.hashCode()); 和sout(p2.hashCode());由于没有重写hashCode()方法,打印的是十进制的逻辑地址,而逻辑地址是有系统随机给出的,不相等。若果重写了hashCode()方法,则哈希值相等
2、sout(p1);和sout(p2);由于没有重写toString()方法,打印出物理地址,相当于sout(p1.toString()),即打印对象时,将自动调用toString()方法,而Object对象的toString()方法是将哈希值转为16进制。

3、sout(p1.equals(p2)); // false 由于没有重写equals方法,equals方法比较的是物理地址。
如果对象类型没有重写equals方法,默认比较的是地址值,而物理地址是不同的,所以为false。
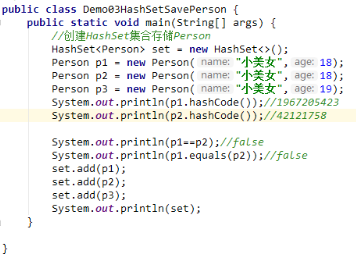

解析:由于没有重写hashCode()方法,故p1和p2的哈希值不相等。由于自定义对象没有重写equals方法,equals方法比较的是地址值。
注意:
1、==对于引用数据类型,比较的是对象的地址值。
2、equals方法默认实现是使用‘==’运算符比较两个对象的地址值,自定义类需要重写equals方法才能比较对象的内容。
3、object类的equals方法,默认比较的是两个对象的地址值,没有意义,所以我们要重写equals方法,比较对象的属性。
4、以后只要自己定义一个类,那么就要重写toString()方法,让他打印对象的属性,因为打印地址没有意义。
如果在person类中重写hashCode()和equals方法,则结果为:

LinkedHashSet:
底层是哈希表+链表,多了一条链表(记录元素的存储顺序),保证元素有序。
Map集合:

HashMap集合:
java为数据结构中的映射定义了一个接口 java.util.Map,此接口主要有四个实现类,分别是 HashMap、HashTable、LinkedHashMap 和 TreeMap,关系图如下所示:
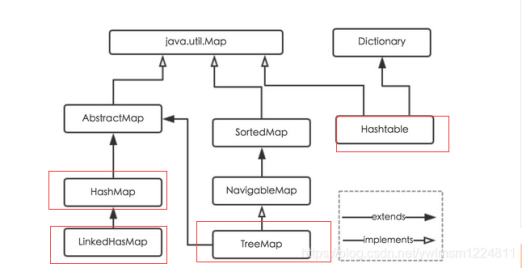
面对各自的特点做一下说明:
(1)HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。HashMap 最多允许一条记录的键为null,允许多条记录的值为null。ConcurrentHashmap、HashMap和Hashtable都是key-value存储结构,但他们有一个不同点是 ConcurrentHashmap、Hashtable不支持key或者value为null,而HashMap是支持的。HashMap 是非线程安全的,即任一时刻有多个线程同时写 HashMap ,可能会导致数据不一致。如果要满足线程安全,可以使用 Collections 的 SynchronizedMap 方法 或者使用 ConcurrentHashMap。
(2)HashTable:HashTable 是遗留类,很多常用的功能与 HashMap 类似,不同的是它继承 Dictionary,并且是线程安全的,任一时刻只能有一个线程写 HashTable,并发性不如 ConcurrentHashMap,因为 ConcurrentHashMap 引入了分段锁。HashTable 不建议在新代码中使用,不需要线程安全的场合使用 HashMap,需要线程安全的场合使用 ConcurrentHashMap。
(3)LinkedHashMap:LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 iterator 遍历 LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
(4)TreeMap:它实现了 SortedMap 接口,能够把保存的记录根据键(key)排序,默认是按照键值的升序排序,也可以指定排序的比较器,当用 iterator 遍历时得到的记录是排过序的。如果使用排序的映射,建议使用 TreeMap,在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的 Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常。

HashMap:底层是哈希表结构,查询速度特别快。是无序的集合,是不同步的,即
存储对象时,将 K/V 键值传给 put() 方法:
① 、调用 hash(K) 方法计算 Key 的 hash 值,然后结合数组长度,计算得数组下标;
② 、调整数组大小(当容器中的元素个数大于 capacity * loadfactor 时,容器会进行扩容resize 为 2n);
③ 、i.如果 Key 的 hash 值在 HashMap 中不存在,则执行插入。
ii.如果 Key 的 hash 值在 HashMap 中存在,且它们两者 equals 返回 true,则更新键值对;
iii. 如果 K 的 hash 值在 HashMap 中存在,且它们两者 equals 返回 false,则插入链表的尾部(尾插法)或者红黑树中(树的添加方式)。
获取对象时,将 K 传给 get() 方法:
①、调用 hash(K) 方法(计算 K 的 hash 值)从而获取该键值所在链表的数组下标;②、顺序遍历链表,equals()方法查找相同 Node 链表中 K 值对应的 V 值。
hashCode 是定位的,存储位置;equals是定性的,比较两者是否相等。
LinkedHashMap:
底层是哈希表+链表结构,多的一个链表可以保证元素有序,是一个有序的集合,即存储元素和取出元素的顺序是一致的。
通过上面的比较可以得知,HashMap 是 Map 家族中普通的一员,它可以满足大多数的使用场景,因此是使用频率最高的一个,下面我们就结合 HashMap 的源码,从存储结构、常用方法、扩容以及安全性方面深入分析 HashMap。
内部实现
存储结构-字段
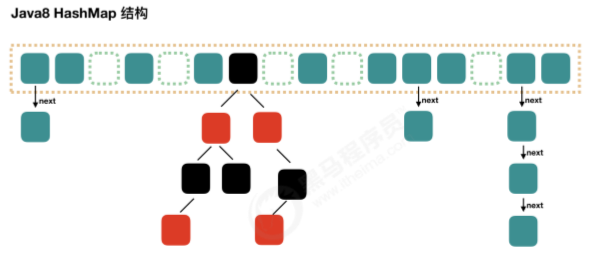
从结构上来讲,HashMap 是数组 + 链表 + 红黑树(JDK1.8 中新增的红黑树部分)实现的,如下图所示:
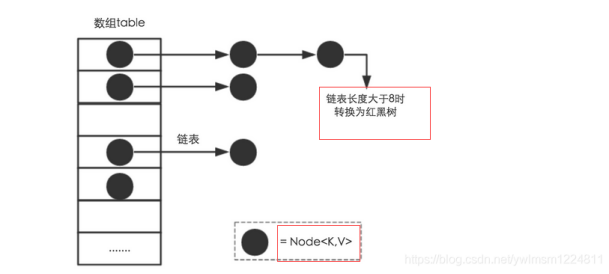
数组中每个元素存储的是链表的头节点。这些元素一般是通过key的hash值对数组长度取模得到的值作为下标存储到数组中的。
这里我们首先要弄明白两个问题:数据底层到底存储的是什么?这样的存储有什么优点?
(1)从源码中得知,HashMap 类有一个非常重要的字段,就是 Node<K,V>[] table,即哈希桶数组(Node数组,节点数组),我们看一下源码,即Node[JDK1.8]
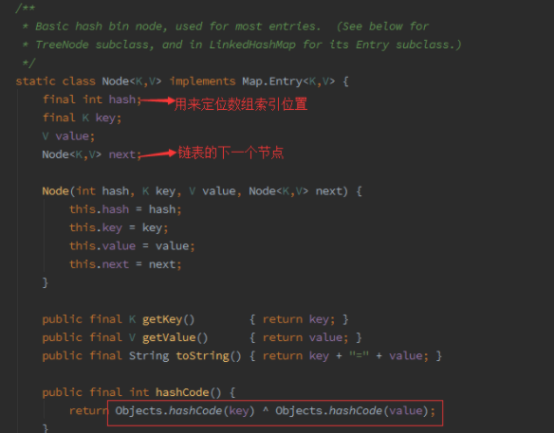
jdk7 中使用 Entry 来代表每个 HashMap 中的数据节点,jdk8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。 我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树 的。
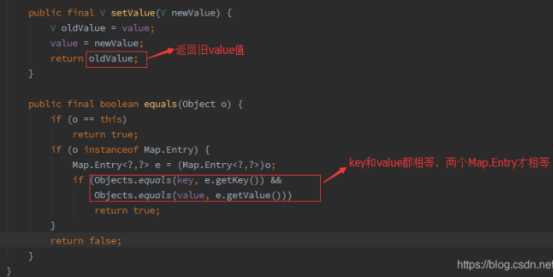
Objects类的equals方法对两个对象比较,可防止空指针异常。
Node 是 HashMap 的一个内部类,其实现了 Map.Entry 接口,本质就是一个映射(键值对),上图中的每一个黑点就是一个 Node 对象。
(2)HashMap 就是使用哈希表来存储的,哈希表为解决冲突,可以采用开放地址法和链地址法等来解决,Java 中的 HashMap 采用了链地址法。链地址法简单来说就是数组加链表的结合,在每个数组元素上都有一个链表结构,当数据被 hash 后,得到数组下标位置,把数据放在对应数组下标元素的链表上,例如程序执行下面的代码:

系统将调用“str”这个key的hashCode()方法得到其hashCode值,然后通过 hash 算法的后两步运算(高位运算和取模运算,下面将会介绍)来定位该键值对的存储位置,有时两个key对定位到相同的位置,表示发生了 Hash 碰撞,当然 Hash 算法计算结果越分散均匀,Hash 碰撞的概率就越小,map的存取效率就会越高。
如果哈希桶数组很大,即使较差的 Hash 算法也会比较分散,否则即使好的 Hash 算法也会出现较多碰撞,所以就需要在时间和空间成本之间权衡,其实就是根据实际情况确定哈希桶数组的大小,并在此基础上设计好的 Hash 算法减少 Hash 碰撞,那么通过什么方式来控制map使得 Hash 的碰撞概率低,哈希桶数组(Node[] table)占用较少的内存呢?答案就是好的 Hash 算法和扩容机制。
在理解 Hash 算法和扩容之前,先了解一下 HashMap 的一些重要的属性字段:
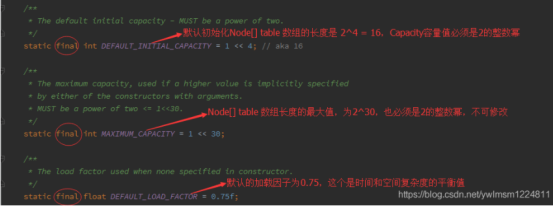
位运算1<<4
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
查看HashMap源码,发现这个static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 值为16。这个是位移算法。例如:4<<2,4的二进制是:0000 0100,<<表示往左移两位:00 010000,只要把4转换成二进制,往左移两位,再转换成10进制得出结果既是:16
更简单的计算方法就是 4<< n 等效于 4 乘以 2的 N 次方
1的二进制是:0000 0001,<<表示往左移4位:00 010000,再转换成10进制得出结果既是:16(1乘以2的4次幂)

Node<K,V>[] table数组默认初始容量为16,容量值capacity必须是2的整数幂。

Node<K,V>[] table最大容量MAXIMUM_CAPACITY是2的30次幂,当HashMap含参构造函数中指定一个比默认初始容量更大的值时使用

默认加载因子0.75在构造函数没有指定时使用。
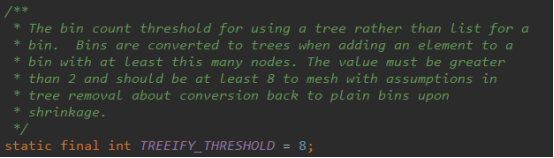
Treeify_threshold树化阈值,即链表转换成树的阈值,桶使用tree而不是list的数量阈值,

Untreeify_threshold树转换成链表的阈值:应该小于链表树化的阈值,最大值为6,
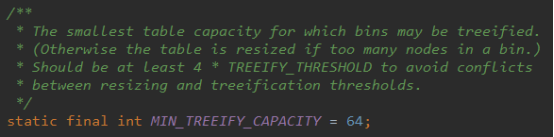
Min_treeify_capacity数组table最小树化容量,
当Node<K,V>[] table数组大于最小容量64时,链表才会转换成树。否则当链表有太多节点时,数组将先进行扩容。即table数组元素个数size的大小超过threshold且Node<K,V>[] table数组长度没有超过64时,进行数组扩容。当链表中节点个数超过8个且Node<K,V>[] table数组长度超过64时,再进行树化。

size:Map中键值对的数量
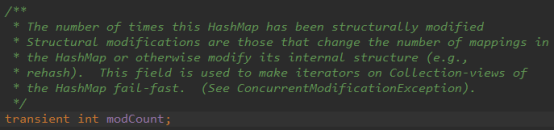
Map被结构性修改(改变size或修改Map内部结构,如rehash)的次数
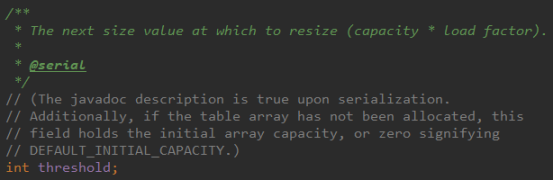
Threshold:table数组元素个数size的大小超过threshold时table数组扩容。当hashmap中的元素个数size超过数组长度*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。

键值对缓存,键值对映射关系保存在entrySet中。
1、HashMap 的 数组 Node[] table 初始化的长度 capacity 是16,哈希桶数组长度 length 大小(即capacity)必须是2的n次方,这种设计主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap 定位哈希桶索引位置时,也加入了高位参与运算的过程
2、loadFactor 为负载因子,默认值是 0.75,0.75 是对时间和空间效率的一个平衡选择,建议大家不要修改,除非在时间或者空间上比较特殊的情况下。例如:如果内存空间很多而又对时间效率要求很高,可以降低负载因子 loadFactor 的值,相反,如果内存空间较少而又对时间效率要求不高,可以增加负载因子 loadFactor 的值,这个值可以大于1
3、threshold 是 HashMap 所能容纳的最大的键值对的个数,threshold = capacity * loadFactor,也就是说 capacity 数组一定的情况下,负载因子越大,所能容纳的键值对个数越多,超出 threshold 这个数目就重新 resize(扩容),扩容后的 HashMap 的容量是之前的2倍。
4、size 是 HashMap 中实际存在的键值对的数量,注意和 Node[] table 的长度 capacity 、容纳最大键值对数量 threshold 的区别
5、modCount 主要用来记录 HashMap 内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化是指结构发生变化,例如 put 新的键值对,但是某个 key 对应的 value 值被覆盖不属于结构变化
6、TREEIFY_THRESHOLD 和 MIN_TREEIFY_THRESHOLD,即使 hash 算法 和负载因子设计的再完美,也避免不了拉链过长的情况,一旦出现拉链过长,严重影响 HashMap 的性能,于是在 JDK1.8 中对数据结构做了进一步的优化,引入了红黑树。当链表长度太长(超过 TREEIFY_THRESHOLD = 8)时,当Node[] table 数组长度超过 64(MIN_TREEIFY_THRESHOLD = 64) 时,链表就转化为了红黑树,利用红黑树快速增删改查的特点提高 HashMap 的性能。
构造方法源码
下面我们列出 HashMap 中的所有构造方法的源码,特别注意的是 tableSizeFor 方法,该方法将传入的 capacity 转化为 2的n次方的 threshold(容量的临界值,构造时数组长度 == 临界值):
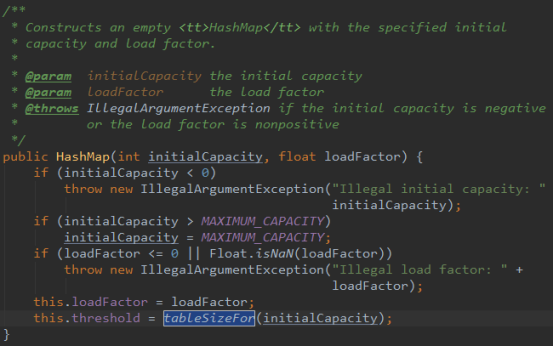
根据初始容量和加载因子构建一个空的HashMap,如果初始容量超出最大容量,则初始容量使用最大容量。tableSizeFor方法根据初始容量计算出当table数组扩容时table数组元素个数的大小,即size的大小,比如容量是30,30<2^5,所以临界值是2^5=32(必须是2^次方),再比如容量是33,33<2^6,所以临界值是64,当table数组实际大小size大于临界值(threshold)时会调用resize方法进行扩容,扩容为原来的2倍。
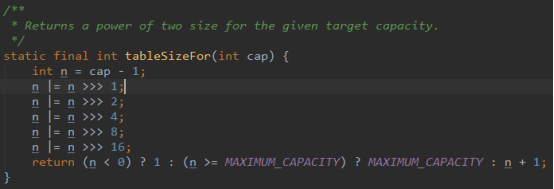
这个方法用于找到大于等于initialCapacity的最小的2的幂(initialCapacity如果就是2的幂,则返回的还是这个数)
首先,为什么要对cap做减1操作。int n = cap - 1;
这是为了防止,cap已经是2的幂。如果cap已经是2的幂, 又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。
n >>> 1,无符号右移,4的二进制为00000100,无符号右移1位为00000010,进行或运算为00000110,即00000100 | 00000010 = 00000110 6
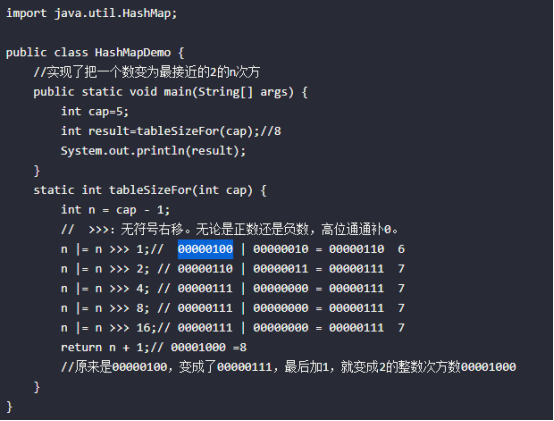
注意:00000110右移两位为00000001,而不是00000011.

功能实现-方法
HashMap 内部功能实现很多,下面主要对从根据 key 获取哈希桶数组索引位置、put、get等方法、扩容过程进行深入的分析
1、确定哈希桶数组索引位置
增加、删除、查找键值对需要定位到哈希桶数组索引位置都是很关键的第一步,HashMap 的数据结构是 链表+数组 的结合,所以希望 HashMap 里的元素位置尽量分布均匀些,使得每个位置上的元素只有一个,那么当我们用 hash 算法求得这个位置的时候,马上就知道对应位置的元素就是我们要找的,不用遍历链表,大大优化了查询的效率。HashMap 定位数组索引位置,直接决定了 hash 方法的离散性能,下面我们看看源码:
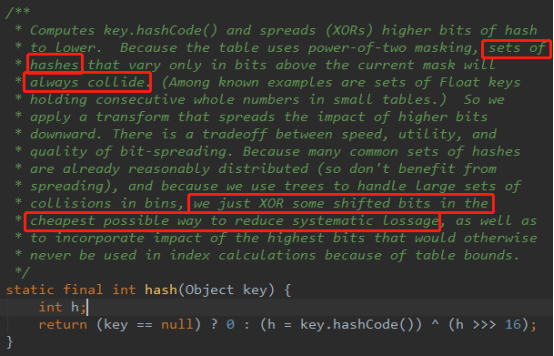

Hash 算法的本质就三步:
1、获取key的hashCode值
2、高位运算(hashCode的高16位异或低16位)
3、取模运算( h & (length -1))

hash值本为32位的int类型,散列表就是哈希表
从上面的代码可以看到key的hash值的计算方法。key的hash值高16位不变,低16位与高16位异或作为key的最终hash值。将高16位与低16位异或来减少碰撞,异或是减少系统开销最便宜的方式。另外使用树已经处理了大量的冲突。
在JDK1.8 中优化了高位运算的算法,通过hashCode的高16位异或低16位实现的:(h = key.hashCode())^ (h >>>16),主要从速度、功效、质量来考虑的,这么做可以在数组table的length较小的时候,也能保证考虑到高低Bit都参与到 Hash 的计算中,同时不会有太大的开销,下面具体说明,n 为table的长度:

由上图可以看到,只有hash值的低4位参与了运算。
取模运算设计方法非常巧妙,取模运算本来是很耗性能的,但是 HashMap 中是通过 h & (length -1)来获得该对象的保存位,而 HashMap 底层的数组长度length 总是2的n次方,这是 HashMap 在速度上的优化,当 length 总是2的n次方时, h & (length -1)运算等价于 h % length (对length 取模),& 比 % 具有更高的效率
因为,table的长度都是2的幂,因此index仅与hash值的低n位有关(此n非table.leng,而是2的幂指数,假设table.length=2^4=16,n为4),hash值的高位都被与操作置为0了。
put 方法
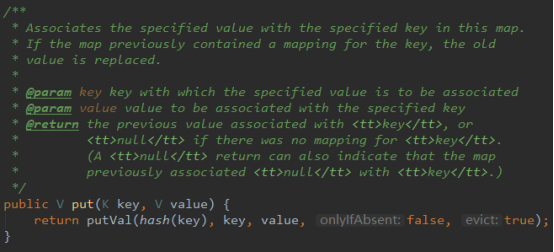
Hash(key):计算出key的hash值。

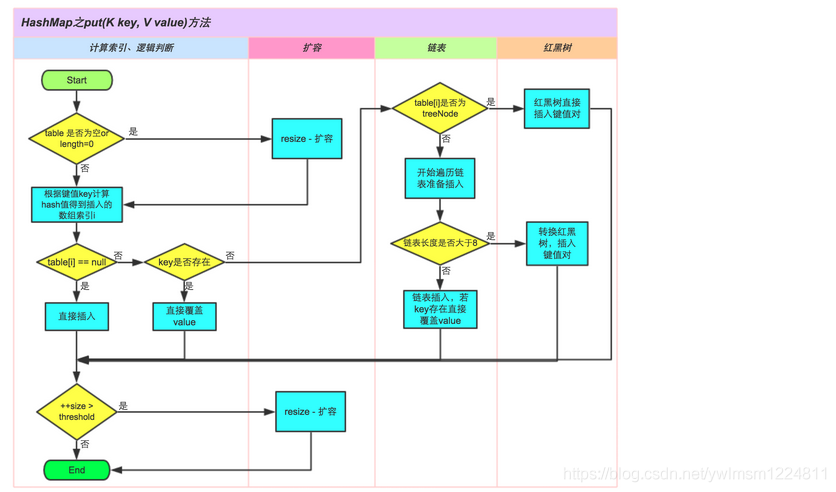
put方法详解:
1、如果table数组为null或者table数组的长度为0,则调用resize()方法扩容并创建table数组。数组的长度为n,(put时确保table数组不为空且长度不为0)
2、如果table数组不为null且数组的长度不为0,则根据table数组的长度n和key的hash值hash(key),计算出数组下标i,该下标对应的节点名称为p,p节点为头节点。
如果p节点为null,则根据hash值、key、value新建一个node节点,直接插入。(如果下标位置节点为空,则新建一个节点放在该下标位置)
其中hash值时key的hashCode()方法算出来的值h的低16位异或高16位算出来的结果,
3、如果table数组不为null且数组的长度不为0,下标i位置的节点p也不为null。
1)、如果p节点的hash值等于hash(key)且p节点的key等于key,将p节点赋值给e节点,即hash值和key均相同时,新的节点覆盖原来的节点,此时e节点不为空。
(如果下标位置有节点,节点的hash值与hash(key)相等且key也相等,则将该下标位置的节点赋值给e节点,此时e节点的value值为旧值。后面再将新添加的value覆盖e节点的value)
2)、如果p节点为红黑树节点,则进行红黑树处理,此时e节点不为空
3)、如果p节点的hash值等于hash(key)但是key不相等且p节点不为红黑树节点,即p节点为链表节点,如果p的下一个节点为空,
则根据hash值、key、value新建一个节点作为p节点的下一个节点,即直接插入,此时e节点不为空,且e节点为新添加的节点。
如果链表长度超出8时,则执行红黑树逻辑。
如果p的下一个节点e不为空且e节点的hash值等于hash(key)但是key不相等,则将e赋值给p节点,指向下一个寻找的节点。如果key相等,后面再用新添加的value覆盖e节点的value
4、如果e节点不为空且e节点的value值不为空,则将新添加的value覆盖e节点的value。
put 方法执行逻辑的图:
get 方法
我们都知道,HashMap中最常用的方法就是 put 和 get 方法,上面介绍了put方法的源码,下面分析一下 get 方法的源码:
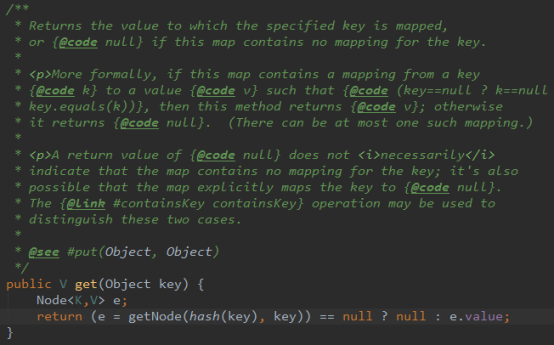
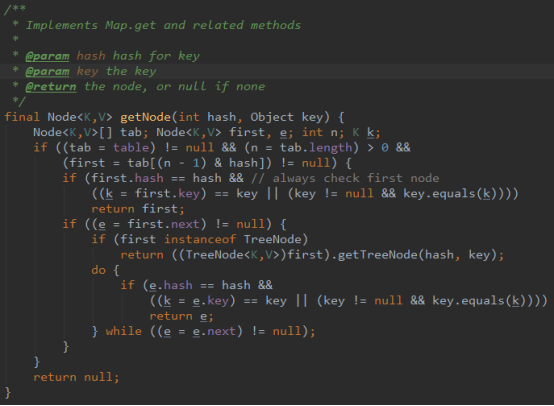
1、如果table数组不为null,、数组长度大于0、根据数组长度和hash计算的下标出的节点first不为null:
1)、如果下标位置节点first的hash值等于hash(key)且first的key等于key,则返回first节点。
2)、如果下标位置节点first的hash值等于hash(key)、first的key不等等于key、first节点的下一个节点e不为null,如果first节点是红黑树节点treeNode,则按照红黑树的算法查找节点。如果first节点不是红黑树节点,即为链表节点,当e节点的hash值等于hash(key)且e节点的key等于key时,则返回e节点,如果当e节点的hash值等于hash(key)但是e节点的key不等于key时,这指向下一个节点,当下一个节点不为null时,再重复上一次循环。
扩容机制
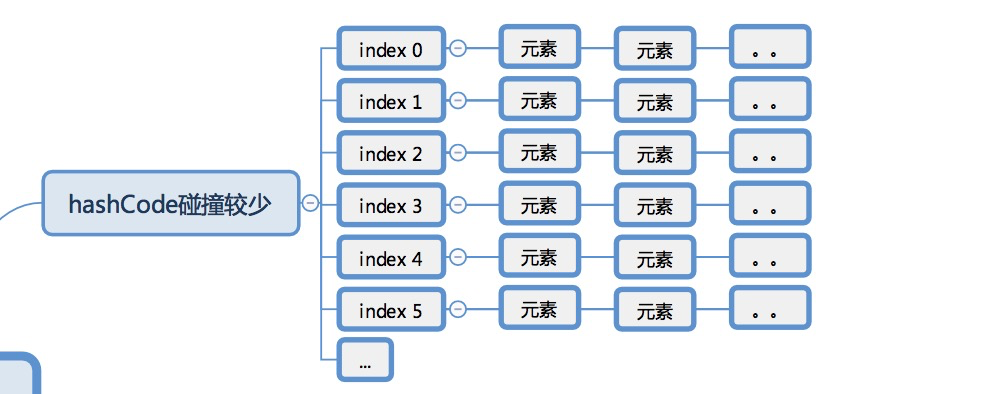
在说明hashMap如何进行扩容之前,先说下为什么要进行扩容?是因为hashMap初始化的容量不够用了吗?不是,是因为当hashMap元素的个数 > hashMap容量*0.75时,存储新元素发生hashcode碰撞的概率变得很大。那么,什么是hashcode碰撞?
hashcode碰撞就是当存入多个元素的时候,元素key的hashcode出现了一样的情况。当hashmap存入元素的时候,如果碰撞较少,那么出现的存储情况如图:
如果碰撞比较频繁,就会出现的存储情况如图:
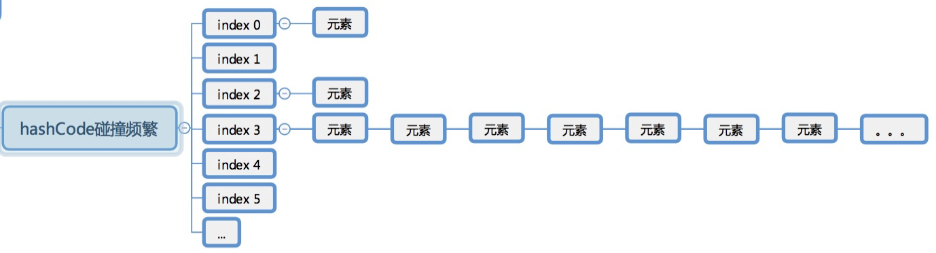
综上:hashcode碰撞会导致hashMap中元素分布不均衡,hashMap中元素分布不均衡就会导致查找元素的效率变得很低。
hashMap为了减少hashcode碰撞的几率,会在对key进行hash的时候进行扰动,也就是让计算出来的hashCode更随机。
// > java8 (h = key.hashCode()) ^ (h >>> 16)
但即使这样,当hashMap元素的个数 > hashMap容量*负载因子(默认0.75)时,hashcode碰撞的概率也会变得较为频繁。这时候就需要对hashmap进行扩容了。
扩容(resize)就是重新计算容量,向 HashMap 中不断的添加数据,HashMap 内部对象的数组无法承载更多的元素时就需要对象扩大数组的长度,以便能装入更多的元素。Java的数组是无法自动扩容的,方法就是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水就需要换大桶一样。
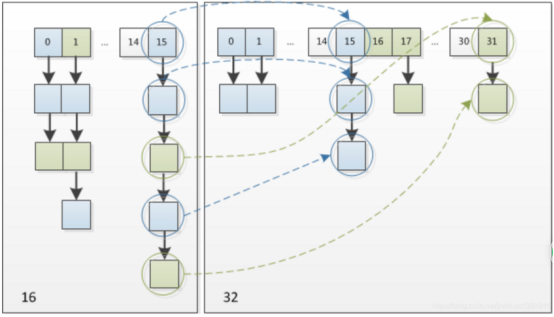
JDK1.7采用的是单链表的头插入方式,也就是同一位置上新元素总会被放在链表的头位置,在旧数组中同一条Node链表上的元素,通过重新计算索引位置后,有可能放到新数组的不同的位置上。 JDK1.7的源码:

解析:
1、src引用旧的table数组
2、遍历旧的table数组,获取旧table数组的每一个值src[j],
3、如果src[j]不为空,则释放旧table数组中的节点对象的引用;如果src[j]为空则不作处理
下面举个例子说明扩容的过程,假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。其中的哈希桶数组table的size=2, 所以key = 3、7、5,put顺序依次为 5、7、3。在mod 2以后(即对2取模)都冲突在table[1]这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小size 大于 table的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize成4,然后所有的Node重新rehash的过程。
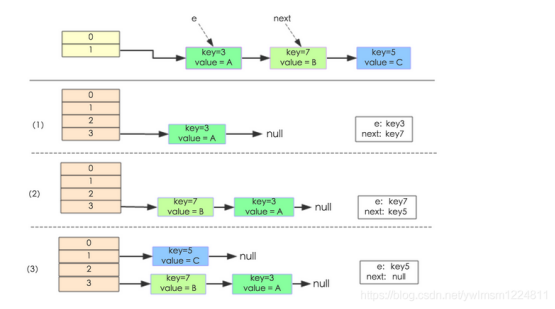
JDK1.7扩容步骤:
1、定义原数组的e和next
2、计算e在新数组中的位置i
3、将e.next置为null
4、将e放到指定位置上
5、将原数组的next赋值为e,遍历原数组该位置的所有节点并放到新数组不同位置。
JDK1.7中 rehash 的时候,旧链表迁移新链表的时候,如果新表的数组索引位置相同,则链表元素会倒置
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
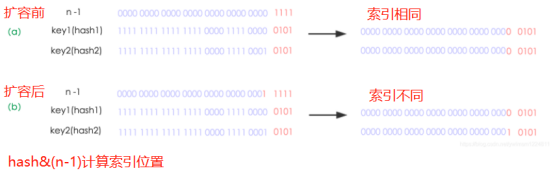
扩容前,key1和key2的hash值不同,但是通过hash寻址算法后索引相同;扩容后,key1和key2的hash值不同,通过hash寻址算法后索引不同。
元素在重新计算hash(rehash)之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),未扩容时,hash值的这个位置的值无论是0还是1对最终的结果都没有影响,因为对应的 n - 1的这个位置的值是0,进行&操作之后,无论何时都是0,而扩容之后hash值的这个位置,如果是0,那么rehash之后还是在原来的位置index;如果是1,那么rehash之后的位置是原来的位置 + 扩容前的数组容量,即index + oldCap。因此新的index就会发生这样的变化:
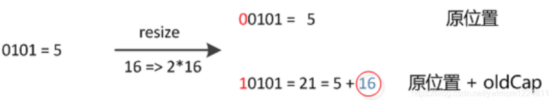
<<左移运算,>>右移运算,还有不带符号的位移运算 >>>
左移的运算规则:按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零。
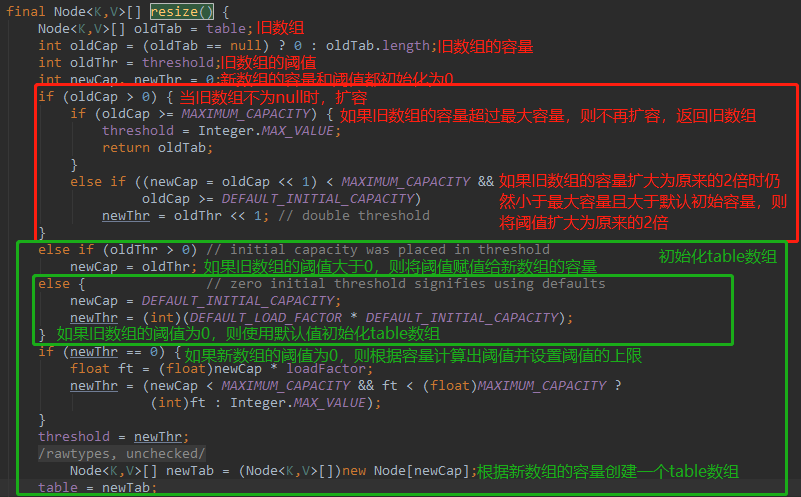
resize()函数有两种使用情况:
1、当table数组为null时初始化hash表。

2、当table数组不为null时进行扩容。
如果table数组的容量超过最大容量时,无法扩容,直接返回旧的数组。并将threshold值设置为Integer.MAX_VALUE(2^31-1),
如果table数组的容量扩展为原来的2倍时仍没有超过最大容量且table数组原来的长度已经大于默认的初始容量时,将threshold扩大为原来的2倍。
创建一个新的数组代替已有的容量小的数组
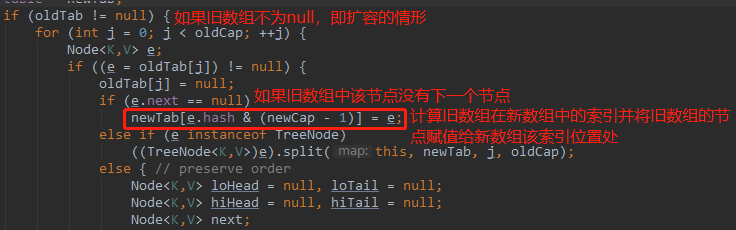


e.hash&oldCap=0表示e在新旧数组中的索引位置不变。


总结
(1)扩容是一个特别耗性能的操作,所以当程序员在使用 HashMap,正确估算 map 的大小,初始化的时候给一个大致的数值,避免 map 进行频繁的扩容
(2)负载因子 loadFactor 是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况特殊
(3)HashMap 是非线程安全的,不要在并发的情况下使用 HashMap,建议使用 ConcurrentHashMap
(4)JDK1.8 中引入了红黑树,大大的提高了 HashMap 的性能