好久没有用python写爬虫了,好多xpath语法都已经有点生疏了。
结合自己之前整理的资料,在这里做一下xpath常用语法总结,以及本次用到的需求是爬取某个节点下的所有内容(包含标签也需要获取)
常用定位语句实例
首先解决获取标签下所有内容的问题:
以 三人行书屋为例:
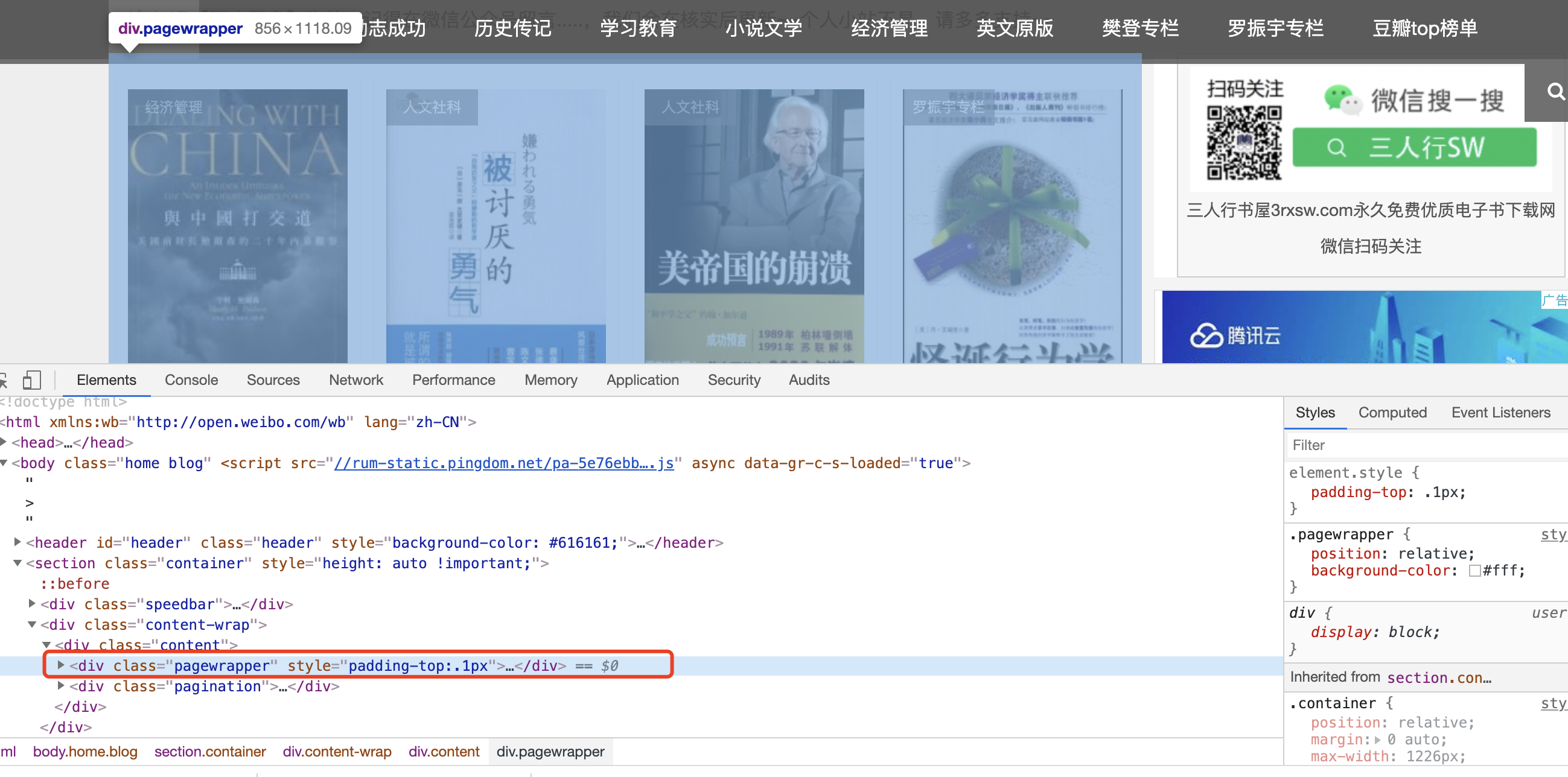
我要获取 class="pagewrapper"的div下的所有内容,xpath写法:content_list = div[@class="pagewrapper"]这样我就获取到整个dom。使用scrapy的xpath提取方法:
content_list.getall()
1. //NODE[not(@class)] 所有节点名为node,且不包含class属性的节点
2. //NODE[@class and @id] 所有节点名为node,且同时包含class属性和id属性的节点
3. //NODE[contains(text(),substring] 所有节点名为node,且其文本中包含substring的节点
//A[contains(text(),"下一页")] 所有包含“下一页”字符串的超链接节点
//A[contains(@title,"文章标题")] 所有其title属性中包含“文章标题”字符串的超链接节点
4. //NODE[@id="myid"]/text() 节点名为node,且属性id为myid的节点的所有直接text子节点
5. BOOK[author/degree] 所有包含author节点同时该author节点至少含有一个的degree孩子节点的book节点
6. AUTHOR[.="Matthew Bob"] 所有值为“Matthew Bob”的author节点
7. //*[count(BBB)=2] 所有包含两个BBB孩子节点的节点
8. //*[count(*)=2] 所有包含两个孩子节点的节点
9. //*[name()='BBB'] 所有名字为BBB的节点,等同于//BBB
10. //*[starts-with(name(),'B')] 所有名字开头为字母B的节点
11. //*[contains(name(),'C')] 所有名字中包含字母C的节点
12. //*[string-length(name()) = 3] 名字长度为3个字母的节点
13. //CCC | //BBB 所有CCC节点或BBB节点
14. /child::AAA 等价于/AAA
15. //CCC/descendant::* 所有以CCC为其祖先的节点
16. //DDD/parent::* DDD节点的所有父节点
17. //BBB[position() mod 2 = 0] 偶数位置的BBB节点
18. AUTHOR[not(last-name = "Bob")] 所有不包含元素last-name的值为Bob的节点
19. P/text()[2] 当前上下文节点中的P节点的第二个文本节点
20. ancestor::BOOK[1] 离当前上下文节点最近的book祖先节点
21. //A[text()="next"] 锚文本内容等于next的A节点
查找,某属性不为某值的节点
如内容:
<option value="">Club</option>
<option value="281">Manchester City</option>
<option value="985">Manchester United</option>
<option value="148">Tottenham Hotspur</option>
选择value不为 “”的节点
op = e_html.xpath('//option[not(@value="")]')
starts-with 顾名思义,匹配一个属性开始位置的关键字
contains 匹配一个属性值中包含的字符串
text() 匹配的是显示文本信息,此处也可以用来做定位用
eg
//input[starts-with(@name,'name1')] 查找name属性中开始位置包含'name1'关键字的页面元素
//input[contains(@name,'na')] 查找name属性中包含na关键字的页面元素
<a href="http://www.baidu.com">百度搜索</a>;
xpath写法为 //a[text()='百度搜索']
或者 //a[contains(text(),"百度搜索")]
找出table节点的class包含 tablesaw的所有table节点
>> '//table[contains(@class,"tablesaw")]'
xpath相对节点查找方法
XPath轴(XPath Axes)可定义某个相对于当前节点的节点集:
1、child 选取当前节点的所有子元素
2、parent 选取当前节点的父节点
3、descendant 选取当前节点的所有后代元素(子、孙等)
4、ancestor 选取当前节点的所有先辈(父、祖父等)
5、descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身
6、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
7、preceding-sibling 选取当前节点之前的所有同级节点
8、following-sibling 选取当前节点之后的所有同级节点
9、preceding 选取文档中当前节点的开始标签之前的所有节点
10、following 选取文档中当前节点的结束标签之后的所有节点
11、self 选取当前节点
12、attribute 选取当前节点的所有属性
13、namespace 选取当前节点的所有命名空间节点