多线程
线程:实现多任务的另一种方式
-
一个进程中,也经常需要同时做多件事,就需要同时运行多个‘子任务’,这些子任务,就是线程
-
线程又被称为轻量级进程(lightweight process),是更小的执行单元
-
一个进程可拥有多个并行的(concurrent)线程,当中每一个线程,共享当前进程的资源
-
一个进程中的线程共享相同的内存单元/内存地址空间可以访问相同的变量和对象,而且它们从同一堆中分配对象通信、数据交换、同步操作
-
由于线程间的通信是在同一地址空间上进行的,所以不需要额外的通信机制,这就使得通信更简便而且信息传递的速度也更快
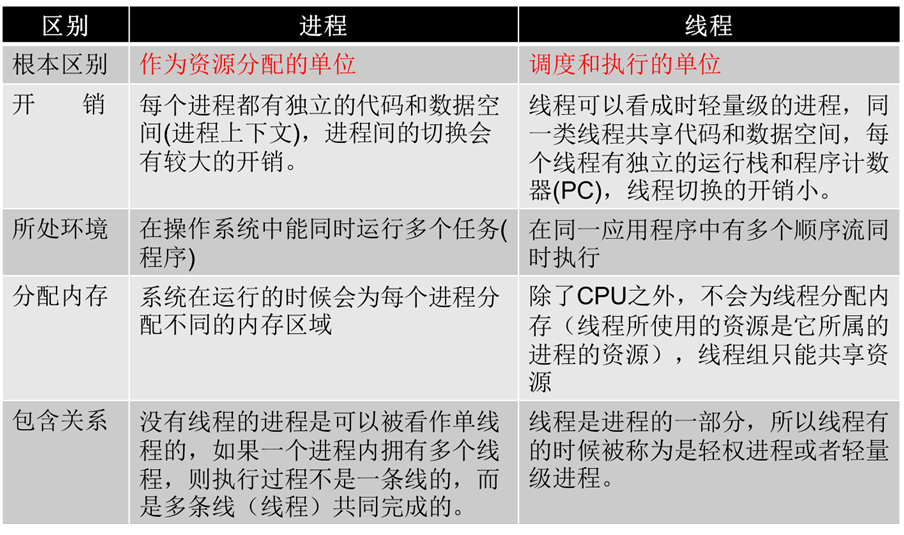
线程与进程的区别
一般来讲:我们把进程用来分配资源,线程用来具体执行(CPU调度)
多线程的创建(函数和类)
创建线程的两种方式:
-
第一:通过
threading.Thread直接在线程中运行函数;import threading,time def saySorry(): print("子线程%s启动" %(threading.current_thread().name)) #当前线程的名字 time.sleep(1) print("我能吃饭了吗?") if __name__ == "__main__": print('主线程%s启动' %(threading.current_thread().name)) for i in range(5): t = threading.Thread(target=saySorry) #Thread():指定线程要执行的代码 t.start() 加了time.sleep(1) 执行结果: 主线程MainThread启动 子线程Thread-1启动 子线程Thread-2启动 子线程Thread-3启动 我能吃饭了吗? 我能吃饭了吗? 我能吃饭了吗? 不加time.sleep(1)执行结果: 主线程MainThread启动 子线程Thread-1启动 我能吃饭了吗? 子线程Thread-2启动 我能吃饭了吗? 子线程Thread-3启动 我能吃饭了吗? 说明线程是异步执行 -
第二:通过继承
threading.Thread类来创建线程- 这种方法只需要重载
threading.Thread类的 run 方法,然后调用 start()开启线程就可以了
- 这种方法只需要重载
import threading
class MyThread(threading.Thread):
def run(self):
for i in range(5):
print(i)
if __name__ == "__main__":
t1 = MyThread()
t2 = MyThread()
t1.start()
t2.start()
线程5种状态
-
1、新状态:线程对象已经创建,还没有在其上调用start()方法。
-
2、可运行状态:当线程有资格运行,但调度程序还没有把它选定为运行线程时线程所处的状态。当start()方法调用时,线程首先进入可运行状态。在线程运行之后或者从阻塞、等待或睡眠状态回来后,也返回到可运行状态。
-
3、运行状态:线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一一种方式。
-
4、等待/阻塞/睡眠状态:这是线程有资格运行时它所处的状态。实际上这个三状态组合为一种,其共同点是:线程仍旧是活的(可运行的),但是当前没有条件运行。但是如果某件事件出现,他可能返回到可运行状态。
-
5、死亡态:当线程的run()方法完成时就认为它死去。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦死亡,就不能复生。如果在一个死去的线程上调用start()方法,会抛出异常。
线程同步
-
当多个线程⼏乎同时修改某⼀个共享数据的时候, 需要进⾏同步控制
-
线程同步能够保证多个线程安全访问竞争资源, 最简单的同步机制是引⼊互
斥锁 -
互斥锁保证了每次只有⼀个线程进⾏写⼊操作,从⽽保证了多线程情况下数据的正确性(原子性)
-
互斥锁为资源引入一个状态:锁定/非锁定。某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
线程同步-互斥锁
import threading
num = 0
def test1():
global num
if mutex.acquire(): #acquire()方法获得锁
for i in range(1000):
num += 1
mutex.release() #release()方法释放锁
def test2():
global num
if mutex.acquire(): #acquire()方法获得锁
for i in range(1000):
num += 1
mutex.release() #release()方法释放锁
mutex = threading.Lock()
p1 = threading.Thread(target=test1)
p1.start()
p2 = threading.Thread(target=test2)
p2.start()
print(num)
当一个线程调用Lock对象的acquire()方法获得锁时,这把锁就进入“locked”状态。
因为每次只有一个线程可以获得锁,所以如果此时另一个线程2试图获得这个锁,该线程2就会变为同步阻塞状态
直到拥有锁的线程1调用锁的release()方法释放锁之后,该锁进入“unlocked”状态。
线程调度程序继续从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态
一个线程有锁时别的线程只能在外面等着
同步和异步
同步调⽤:确定调用的顺序
提交一个任务,自任务开始运行直到此任务结束,我再提交下一个任务
异步调⽤:不确定顺序
一次提交多个任务,然后我就直接执行下一行代码
线程同步-多个线程有序执⾏
import threading,time
class Task1(threading.Thread):
def run(self):
while True:
if lock1.acquire():
print('-----Task1-----')
time.sleep(1)
lock2.release()
class Task2(threading.Thread):
def run(self):
while True:
if lock2.acquire():
print('-----Task2-----')
time.sleep(1)
lock3.release()
class Task3(threading.Thread):
def run(self):
while True:
if lock3.acquire():
print('-----Task3-----')
time.sleep(1)
lock1.release()
lock1 = threading.Lock()
lock2 = threading.Lock()
lock2.acquire()
#创建另外一把锁,并且锁上
lock3 = threading.Lock()
lock3.acquire()
#再创建另外一把锁,并且锁上
t1 = Task1()
t2 = Task2()
t3 = Task3()
t1.start()
t2.start()
t3.start()
#按照逻辑总共创建3个锁,执行Task1时,锁2和锁3都已经上锁,if lock1.acquire():理解为锁1能抢到锁,锁1肯定能抢到锁1,然后执行时锁1的逻辑,释放锁2,这时锁2能抢到锁释放锁3,这样循环,可以有顺序的执行
信号量
- 信号量
semaphore:用于控制一个时间点内线程进入数量的锁,信号量是用来控制线程并发数的
import time
import threading
s1=threading.Semaphore(5)
def foo():
s1.acquire()
time.sleep(2)
print("ok")
s1.release()
for i in range(20):
t1=threading.Thread(target=foo,args=())
t1.start() #此时可以控制同时进入的线程数
控制此时只有5个线程去执行print("ok") 剩下的线程等这信号量释放,如果不使用信号量,输出的时候20个ok差不多同时打印,如果使用了信号量,此时只是5个5个的打印
GIL全局解释器锁
-
Cpython独有的锁,牺牲效率保证数据安全 -
GIL锁是一把双刃剑,它带来优势的同时也带来一些问题
-
首先:执行Python文件是什么过程?谁把进程起来的?
操作系统将你的应用程序从硬盘加载到内存。运行python文件,在内存中开辟一个进程空间,将你的Python解释器以及
py文件加载进去,解释器运行py文件Python解释器分为两部分,先将你的代码通过编译器编译成C的字节码,然后你的虚拟机拿到你的C的字节码,输出机器码,再配合操作系统把你的这个机器码扔给
cpu去执行你的
py文件中有一个主线程,主线程做的就是这个过程。如果开多线程,每个线程都要进行这个过程-
理想的情况:
三个线程,得到三个机器码,然后交由CPU,三个线程同时扔给三个CPU,然后同时进行,最大限度的提高效率,但是CPython多线程应用不了多核 -
CPython到底干了一件什么事情导致用不了多核?
Cpython在所有线程进入解释器之前加了一个全局解释器锁(GIL锁)。这个锁是互斥锁,是加在解释器上的,导致同一时间只有一个线程在执行所以你用不了多核 -
为什么这么干?
之前写python的人只有一个cpu。。。所以加了一个锁,保证了数据的安全,而且在写python解释器时,更加好写了为什么不取消这个锁?解释器内部的管理全部是针对单线程写的 -
那我该怎么办?
虽然多线程无法应用多核,但是多进程可以应用多核(开销大) -
Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么我还要学互斥锁?
首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。所以,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理
-
⽣产者消费者模式
-
⽣产者消费者模式
-
在线程世界⾥, ⽣产者就是⽣产数据的线程, 消费者就是消费数据的线程(做包子,吃包子) 经常会出现生产数据的速度大于消费数据的速度,或者生产速度跟不上消费速度
-
⽣产者消费者模式是通过⼀个容器(缓冲区)来解决⽣产者和消费者的强耦合问题
-
例如两个线程共同操作一个列表,一个放数据,一个取数据
-
⽣产者和消费者彼此之间不直接通讯, ⽽通过阻塞队列来进⾏通讯
-
例子:
import threading
import time
from queue import Queue
class Pro(threading.Thread):
def run(self):
global queue
count = 0
while True:
if queue.qsize()<1000:
for i in range(100):
count = count + 1
msg = '生成产品' + str(count)
queue.put(msg)#队列中添加新产品
print(msg)
time.sleep(1)
class Con(threading.Thread):
def run(self):
global queue
while True:
if queue.qsize() > 100:
for i in range(3):
msg = self.name + '消费了' + queue.get()
print(msg)
time.sleep(1)
if __name__ == "__main__":
queue = Queue()
#创建一个队列。线程中能用,进程中不能使用 导的包都不一样
for i in range(500): #创建500个产品放到队列里
queue.put(‘初始产品’ + str(i))#字符串放进队列
for i in range(2):#创建了两个线程
p = Pro()
p.start()
for i in range(5):#5个线程
c = Con()
c.start()
协程
-
⽐线程更⼩的执⾏单元(微线程)
-
⼀个线程作为⼀个容器⾥⾯可以放置多个协程
-
只切换函数调用即可完成多线程,可以减少CPU的切换
-
协程⾃⼰主动让出CPU
python还有⼀个⽐greenlet更强⼤的并且能够⾃动切换任务的模块 gevent
原理是当⼀个greenlet遇到IO(指的是input output 输⼊输出)操作时, ⽐如访问⽹络, 就⾃动切换到其他的greenlet, 等到IO操作完成, 再在适当的时候切换回来继续执⾏
进程线程的任务切换是由操作系统自行切换的,你自己不能控制
协程可以通过自己的程序(代码)来进行切换,自己能够控制
gevent只有遇到模块能够识别的IO操作的时候,程序才会进行任务切换,实现并发效果,如果所有程序都没有IO操作,那么就基本属于串行执行了
import gevent
def A():
while True:
print(".........A.........")
gevent.sleep(1)#用来模拟一个耗时操作
#gevent中:当一个协程遇到耗时操作会自动交出控制权给其他协程
def B():
while True:
print(".........B.........")
gevent.sleep(1)#每当遇到耗时操作,会自用转到其他协程
g1 = gevent.spawn(A) # 创建一个gevent对象(创建了一个协程),此时就已经开始执行A
g2 = gevent.spawn(B)
g1.join() #等待协程执行结束
g2.join() #会等待协程运行结束后再退出