1:ROWS BETWEEN UNBOUNDED PRECEDING and CURRENT ROW
unbounded:无界限
preceding:从分区第一行头开始,则为 unbounded。 N为:相对当前行向前的偏移量
following :与preceding相反,到该分区结束,则为 unbounded。N为:相对当前行向后的偏移量
current row:顾名思义,当前行,偏移量为0;
2.CUME_DIST函数
示例:
CREATE TABLE t_employee (id INT, emp_name VARCHAR(20), dep_name VARCHAR(20), salary DECIMAL(7, 2), age DECIMAL(3, 0)); INSERT INTO t_employee VALUES ( 1, 'Matthew', 'Management', 4500, 55), ( 2, 'Olivia', 'Management', 4400, 61), ( 3, 'Grace', 'Management', 4000, 42), ( 4, 'Jim', 'Production', 3700, 35), ( 5, 'Alice', 'Production', 3500, 24), ( 6, 'Michael', 'Production', 3600, 28), ( 7, 'Tom', 'Production', 3800, 35), ( 8, 'Kevin', 'Production', 4000, 52), ( 9, 'Elvis', 'Service', 4100, 40), (10, 'Sophia', 'Sales', 4300, 36), (11, 'Samantha','Sales', 4100, 38);
累积分布:
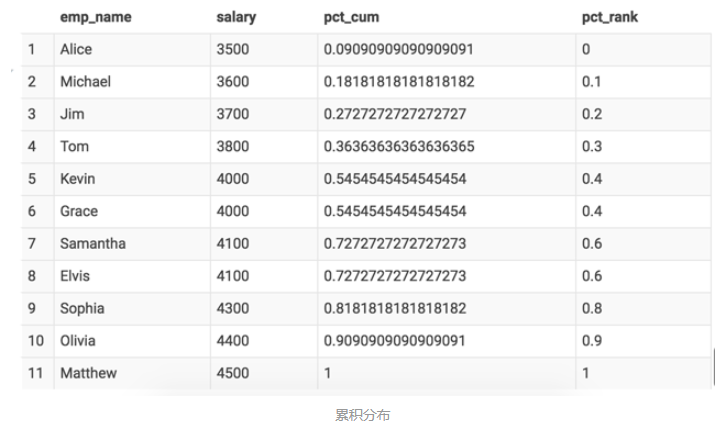
我们可以计算整个公司员工薪水的累积分布。如,4000 元的累计分布百分比是 0.55,表示有 55% 的员工薪资低于或等于 4000 元。计算时,我们先统计不同薪资的频数,再用窗口查询做一次累计求和操作:
方法一:
SELECT
salary
,SUM(cnt) OVER (ORDER BY salary)
/ SUM(cnt) OVER (ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
FROM (
SELECT salary, count(*) AS cnt
FROM t_employee
GROUP BY salary
) a;
方法二:
我们还可以使用 Hive 提供的 CUME_DIST() 来完成相同的计算。PERCENT_RANK() 函数则可以百分比的形式展现薪资所在排名。
SELECT
salary
,CUME_DIST() OVER (ORDER BY salary) AS pct_cum
,PERCENT_RANK() OVER (ORDER BY salary) AS pct_rank
FROM t_employee;
结果示例:
3.lag、lead函数 (统计环比,股票波峰波谷)
示例一(统计波峰波谷):
select * from (select id,time,price, "Peak" as t from (select id,price,time,t3.r1,t3.r2,t3.m t from (select id,price,`time`,maked m, lag(price) over (partition by id order by `time`) lu, lead(price) over (partition by id order by `time`) ll, round(price-lag(price) over (partition by id order by `time`),2) r1, round( price-lead(price) over (partition by id order by `time`),2) r2 from t22) t3 where t3.r1>0 and t3.r2>0) t4 union all select id,time,price, "Botton" as t from (select id,price,time,t3.r1,t3.r2,t3.m t from (select id,price,`time`,maked m, lag(price) over (partition by id order by `time`) lu, lead(price) over (partition by id order by `time`) ll, round(price-lag(price) over (partition by id order by `time`),2) r1, round( price-lead(price) over (partition by id order by `time`),2) r2 from t22) t3 where t3.r1<0 and t3.r2<0) t5) t6 order by time;
示例二(left join统计波峰波谷):
CREATE TABLE IF NOT EXISTS lp.study_2( `id` int commit "主键", `code` bigint commit "编号", `time` string commit "时间", `price` double commit "价格") ROW FORMAT DELIMITED FIELDS TERMINATED BY 'u0001' LINES TERMINATED BY ' ' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
实现sql:
select a.id,a.price, case when b.price is null then "未知" when c.price is null then "未知" when a.price>b.price and a.price>c.price then "波峰" when a.price<b.price and a.price<c.price then "波谷" else "未知" end as mark from lp.study_2 a left join lp.study_2 b on a.code=b.code and b.id=a.id-1 left join lp.study_2 c on a.code=c.code and c.id=a.id+1
示例3(统计环比):
select ds ,group_base, (num_1-lag(num_1) over (partition by group_base order by ds))/(lag(num_1) over (partition by group_base order by ds)) from (select ds, count (role_uid) as num_1 , group_base from dwb.dwb_active_role where gn='${gn}' and ds>='2021-08-08' and ds<='2021-08-09' group by ds,group_base ) a
参考:
Hive分析窗口函数(一) SUM,AVG,MIN,MAX (ROWS BETWEEN UNBOUNDED PRECEDING and CURRENT ROW)
Hive分析窗口函数(四) LAG,LEAD,FIRST_VALUE,LAST_VALUE
用hive实现判断股票价格的波峰 波谷 (此方法不用开窗,效率快)
https://www.jianshu.com/p/75a263d92b0d (hive各版本分析函数差异)