一.基础数据类型的补充
1.其他类型之间的相互转换
例如:str = int(str) str => int;
int = list(int) int => list;
tuple = dict(tuple) tuple => dict;
但是:str => list时用的是str = str.split(元素)
list => str时用的是str = 元素.join(list)
代码展示:
1 s = "|".join(["美国往事","当幸福来敲门","穿靴子的猫"]) 2 print(s) 3 s = s.split("|") 4 print(s) 5 #输出结果: 6 7 美国往事|当幸福来敲门|穿靴子的猫 8 9 ['美国往事', '当幸福来敲门', '穿靴子的猫']
二.关于for的一些解释
1.for在运行的过程中,会有一个指针来记录当前循环的元素是哪一个,一开始这个指针指向第0个,
然后获取到第0个,紧接着删除第0个,这个时候,原来是第一个的元素会自动的变成第0个,然后指针向后移动一次,指向1元素,这时所有元素向前移了一位.
2.总结:字典,列表在for循环过程中,不论是del还是remove,pop都不能实现
3.怎样在for循环的过程中删除元素:
代码展示:
1 lst = ["周杰伦","周润发","周星星","马化腾"] 2 li = [] 3 for i in lst: 4 if i.startswith("周"): 5 li.append(i) 6 for c in li: 7 lst.remove(c) 8 print(lst) 9 #输出结果:['马化腾']
这是把以"周"开头的字符串去除掉;
(1)要新建一个列表,先把符合条件的添加进列表,
(2)然后再遍历该列表,用原来的列表删除遍历到的新列表赋值给变量c的字符串;
*注意转成False的数据:
0,"",None,[],(),{},set() ==>False;
三.set集合
1.set最大的的用处就是去除集合中的重复;set中的元素必须是可哈希的(int,str,tuple,bool);
所以列表,字典,和set(set本身是不可hash的.set是可变的),set中得元素也是无序的;
1 set1 = {'1','alex',2,True,[1,2,3]} # 报错 2 set2 = {'1','alex',2,True,{1:2}} # 报错 3 set3 = {'1','alex',2,True,(1,2,[2,3,4])} # 报错
2.1 增加
代码展示:
1 s = {"刘嘉玲", '关之琳', "王祖贤"} 2 s.add("郑裕玲") 3 print(s) 4 s.add("郑裕玲") # 重复的内容不不会被添加到set集合中 5 print(s) 6 #集合和字典长得很像,但是没有key和value;
2.2 删除
s.remove(元素)#直接删除元素;
s.pop()#随机
3.常用操作:
s1 = {"刘能", "赵四", "⽪皮⻓长⼭山"}
s2 = {"刘科⻓长", "冯乡⻓长", "⽪皮⻓长⼭山"}
# 交集 # 两个集合中的共有元素
print(s1 & s2) #结果: {'⽪皮⻓长⼭山'}
print(s1.intersection(s2)) # 结果:{'⽪皮⻓长⼭山'}
# 并集
print(s1 | s2) # {'刘科⻓长', '冯乡⻓长', '赵四', '⽪皮⻓长⼭山', '刘能'}
print(s1.union(s2)) # {'刘科⻓长', '冯乡⻓长', '赵四', '⽪皮⻓长⼭山', '刘能'}
# 差集
print(s1 - s2) # {'赵四', '刘能'} 得到第⼀个中单独存在的
print(s1.difference(s2)) # {'赵四', '刘能'}
# ⼦集
print(s1 < s2) # set1是set2的⼦子集吗? True
print(s1.issubset(s2))
# 超集
print(s1 > s2) # set1是set2的超集吗? False
print(s1.issuperset(s2))
三.深浅拷贝
1.浅拷贝
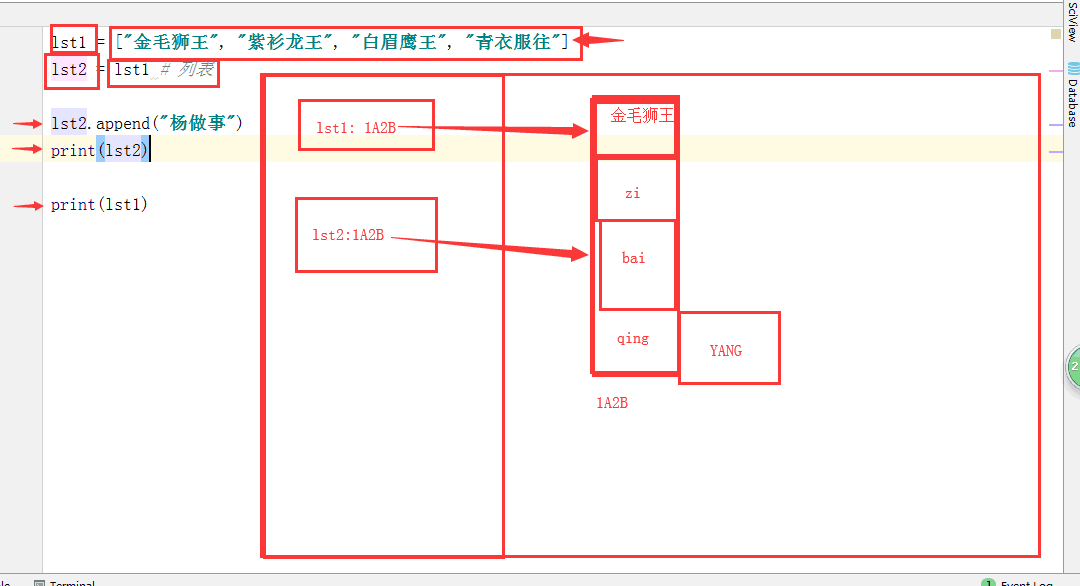
从图可以看出:在列表进行赋值时,两个列表对应一个内存地址的对象;一个列表发生改变,那另一个列表也发生相应改变;
总结:对于列表和字典来说,直接赋值,其实是把内存地址交给变量,并不是复制了一份,所以列表1和列表2的指向是一样的;
浅拷贝格式:lst2 = lst1.copy() print(id(lst1),id(lst2))这时候两个列表内存地址就不一样了,而不互相影响;
代码展示:
1 lst = ["周杰伦","周润发","周星星","马化腾"] 2 lst1 = lst.copy() 3 lst1.append("马鹏林") 4 print(lst,id(lst)) 5 print(lst1,id(lst1)) 6 #输出结果 7 ['周杰伦', '周润发', '周星星', '马化腾'] 2259879557704 8 ['周杰伦', '周润发', '周星星', '马化腾', '马鹏林'] 2259879558408
两个列表不一样,而且内存地址不一样;浅拷贝只会拷贝第一层,所以称为浅拷贝;
浅拷贝还有一种格式:
1 lst1 = ["赵本山", "刘能", "赵四"] 2 lst2 = lst1[:] # 切片会产生新的对象 3 lst1.append("谢大脚") 4 print(lst1,id(lst1)) 5 print(lst2,id(lst2)) 6 #输出结果: 7 ['赵本山', '刘能', '赵四', '谢大脚'] 1400279607368 8 ['赵本山', '刘能', '赵四'] 1400280414792
所以通过上面可以看出,切片也可以进行浅拷贝;切片相当于从源列表copy出一段范围,成为新的列表;
2.深拷贝
1 lst1 = ["超人", "七龙珠", "葫芦娃", ["王力宏", "渣渣辉"]] 2 lst2 = lst1.copy() # 拷贝. 浅拷贝 拷贝第一层 3 lst1[3].append("大阳哥") 4 print(lst1,id(lst1[3])) 5 print(lst2,id(lst2[3])) 6 #输出结果: 7 ['超人', '七龙珠', '葫芦娃', ['王力宏', '渣渣辉', '大阳哥']] 1172889937992 8 ['超人', '七龙珠', '葫芦娃', ['王力宏', '渣渣辉', '大阳哥']] 1172889937992
从上面可以看出,浅拷贝只拷贝第一层,所以列表1和列表2的地址是一样的;
引出深拷贝:
代码展示:
1 #深拷贝 2 import copy 3 lst1 = ["超人", "七龙珠", "葫芦娃", ["王力宏", "渣渣辉"]] 4 lst2 = copy.deepcopy(lst1) # 把lst1扔进去进行深度拷贝 , 包括内部的所有内容进行拷贝 5 lst1[3].append("大阳哥") 6 print(lst1,id(lst1[3])) 7 print(lst2,id(lst2[3])) 8 #输出: 9 ['超人', '七龙珠', '葫芦娃', ['王力宏', '渣渣辉', '大阳哥']] 3012638897480 10 ['超人', '七龙珠', '葫芦娃', ['王力宏', '渣渣辉']] 3012638898888