zoukankan
html css js c++ java
Hadoop综合大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
启动hadoop:
上传到wc文件中
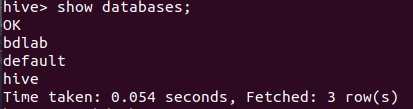
启动Hive
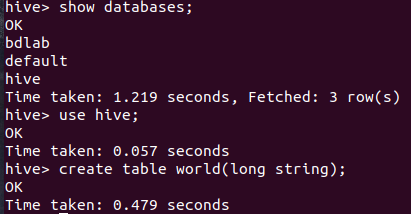
在hive数据库创建表 world:
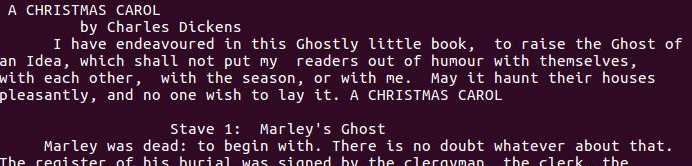
导入文本test.txt并查看
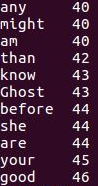
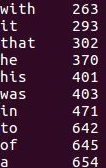
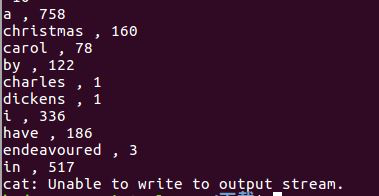
用HQL进行词频统计
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
创建用于存放csv数据目录
把文件放入文件夹中
查看文件中的数据:
导入数据库表中
查看全文
相关阅读:
劳动节CF题总结
「联合省选 2020 A」作业题 做题心得
bzoj3784 树上的路径
[AGC039E] Pairing Points
[AGC012E] Camel and Oases
[AGC011F] Train Service Planning
[AGC039F] Min Product Sum
Pedersen commitment原理
标准模型(standard model)与随机语言模型(random oracle model)
会议论文引用缩写标准 PDF
原文地址:https://www.cnblogs.com/605-mk/p/9089040.html
最新文章
面试
总结2
总结1
面经[快手]
踩坑日记(2)
拉格朗日插值
一个程序弄懂C++面向对象编程
C++程序计时器模版(用于计算某个代码块用时)
OI中的C++语法基础&进阶技巧
P5514 [MtOI2019]永夜的报应
热门文章
CSP-S 2019 解题报告(格雷码)
扩展欧几里得算法(exgcd)
线性代数
回文自动机 笔记
exkmp(Z函数) 笔记
线段树优化建图 笔记
树链剖分 笔记
树套树 笔记
主席树 笔记
线段树历史最值问题
Copyright © 2011-2022 走看看