对于训练出的一个稀疏自动编码器,现在想看看学习出的函数到底是什么样子。对于训练一个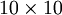 的图像,
的图像,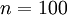 .计算每一个隐层节点
.计算每一个隐层节点  的输出值:
的输出值:
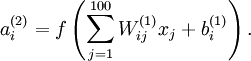
我们要可视化的函数,就是这个以一副2D图像为输入,以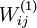 为参数(忽略偏置项),由隐层节点 计算出来的函数。特别是,我们把
为参数(忽略偏置项),由隐层节点 计算出来的函数。特别是,我们把 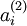 看作是输入
看作是输入  的非线性特征。我们很想知道:什么样的的图像 能使得 成为最大程度的激励? 还有一个问题,就是必须对 加上约束。如果假设输入的范数约束是
的非线性特征。我们很想知道:什么样的的图像 能使得 成为最大程度的激励? 还有一个问题,就是必须对 加上约束。如果假设输入的范数约束是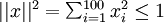 ,可以证明,能够使得隐层神经元得到最大程度激活的像素输入
,可以证明,能够使得隐层神经元得到最大程度激活的像素输入 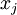 (所有100个像素点,
(所有100个像素点,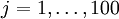 ):
):
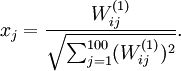
展示出由这些像素灰度值的构成的图像,我们就可以看到隐层节点学习出了什么样的特征。
如果训练出一个含有100个隐层节点的自动编码器,那么我们可视化将会产生100幅图像(每个隐层节点对应一幅)。通过测试这100幅图像,试着理解隐层学习出的整体效果。
下面给出了一个稀疏编码器(100个隐层节点,输入是的图像)学习出的结果:
 上图的每个小方块都给出了一个输入图像,它可使这100个隐藏单元(隐层节点)中的某一个获得最大激励。我们可以看到,不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。这些特征对于物体识别和其他视觉学习任务很有用。当应用到其他领域(如音频),这个算法同样可以学习出很有用的表示或者特征。
上图的每个小方块都给出了一个输入图像,它可使这100个隐藏单元(隐层节点)中的某一个获得最大激励。我们可以看到,不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。这些特征对于物体识别和其他视觉学习任务很有用。当应用到其他领域(如音频),这个算法同样可以学习出很有用的表示或者特征。
学习来源:http://deeplearning.stanford.edu/wiki/index.php/Visualizing_a_Trained_Autoencoder