模块
os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dir1/dir2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","new") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 用于分割文件路径的字符串 os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdin 输入相关
sys.stdout 输出相关 (没有回车)
sys.stderror 错误相关
hashlib模块
import hashlib # ######## md5 ######## hash = hashlib.md5() # help(hash.update) hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) print(hash.digest()) ---------------md5 带salt值----------- hash = hashlib.md5(bytes('898oaFs09f',encoding="utf-8")) hash.update(bytes('admin',encoding="utf-8")) print(hash.hexdigest()) ######## sha1 ######## hash = hashlib.sha1() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest())
时间模块
time & datetime
关系图

import time print(time.time()) #返回当前系统时间戳 print(time.ctime()) #输出Tue Jan 26 18:23:48 2016 ,当前系统时间 print(time.ctime(time.time()-86640)) #将时间戳转为字符串格式 print(time.gmtime(time.time()-86640)) #将时间戳转换成struct_time格式 print(time.localtime(time.time()-86640)) #将时间戳转换成struct_time格式,但返回 的本地时间 print(time.mktime(time.localtime())) #与time.localtime()功能相反,将struct_time格式转回成时间戳格式 print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将struct_time格式转成指定的字符串格式 print(time.strptime("2016-01-28","%Y-%m-%d") ) #将字符串格式转换成struct_time格式
import datetime print(datetime.date.today()) #输出格式 2016-01-26 print(datetime.date.fromtimestamp(time.time()-864400) ) #2016-01-16 将时间戳转成日期格式 current_time = datetime.datetime.now() # print(current_time) #输出2016-01-26 19:04:30.335935 print(current_time.timetuple()) #返回struct_time格式 #datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]]) print(current_time.replace(2014,9,12)) #输出2014-09-12 19:06:24.074900,返回当前时间,但指定的值将被替换 str_to_date = datetime.datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M") #将字符串转换成日期格式 new_date = datetime.datetime.now() + datetime.timedelta(days=10) #比现在加10天 new_date = datetime.datetime.now() + datetime.timedelta(days=-10) #比现在减10天 new_date = datetime.datetime.now() + datetime.timedelta(hours=-10) #比现在减10小时 new_date = datetime.datetime.now() + datetime.timedelta(seconds=120) #比现在+120s print(new_date)
re模块
1 python 支持的正则表达式和语法
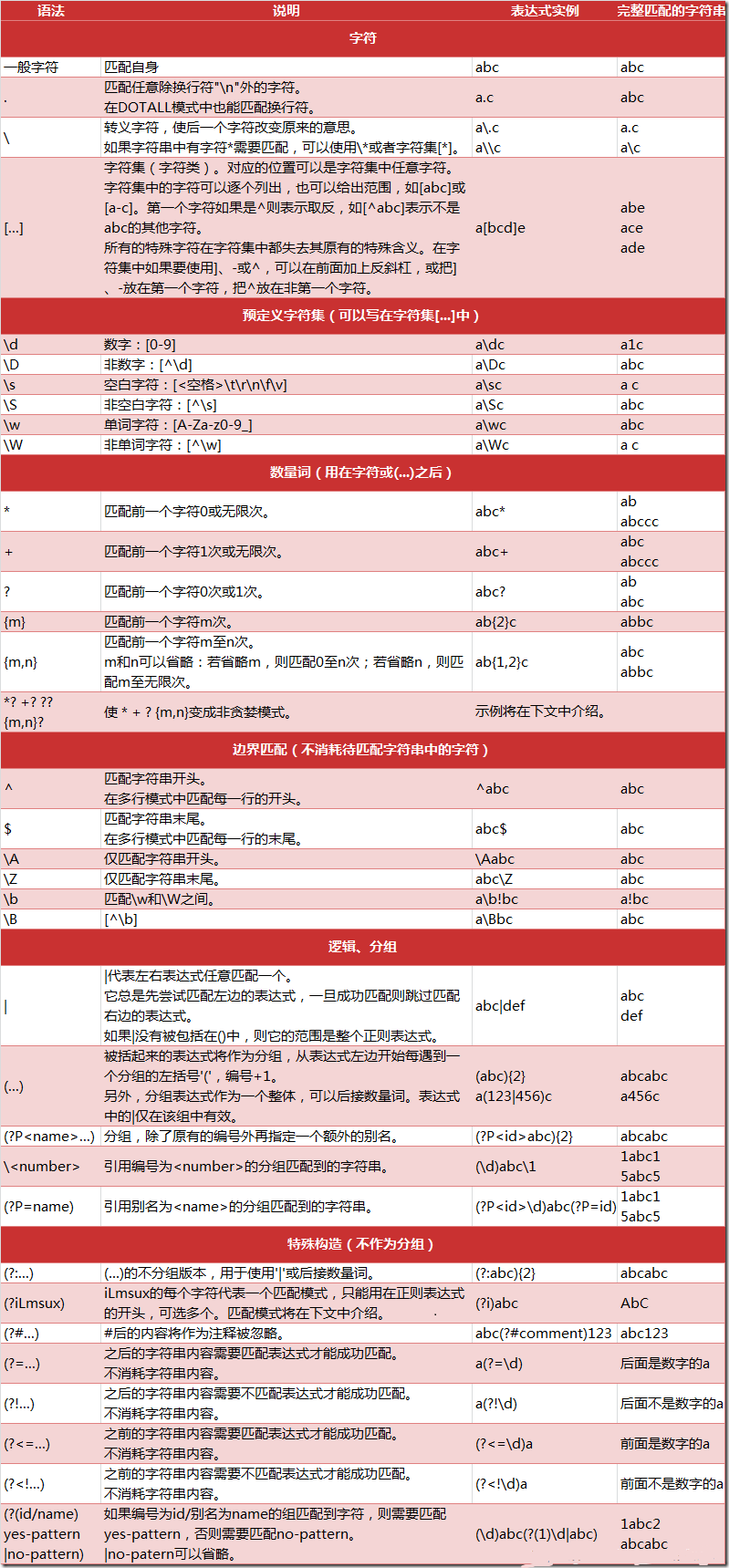
2 match 方法
match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用match提供的可读属性或方法来获取这些信息。
# 无分组 r = re.match("h\w+", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 # 有分组 # 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来) r = re.match("h(\w+).*(?P<name>\d)$", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
3 search
# search,浏览整个字符串去匹配第一个,未匹配成功返回None # search(pattern, string, flags=0)
# 无分组 r = re.search("a\w+", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 # 有分组 r = re.search("a(\w+).*(?P<name>\d)$", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
4 findall
# findall,获取非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖; # 空的匹配也会包含在结果中 #findall(pattern, string, flags=0)
# 无分组 origin = "hello alex bcd abcd lge acd 19" r = re.findall("a\w+", origin) print(r) # 有分组" r = re.findall("a((\w*)c)(d)", origin) print(r)
5 sub
# sub,替换匹配成功的指定位置字符串
sub(pattern, repl, string, count=0, flags=0) # pattern: 正则模型 # repl : 要替换的字符串或可执行对象 # string : 要匹配的字符串 # count : 指定匹配个数 # flags : 匹配模式
origin = "hello alex bcd alex lge alex acd 19" r = re.sub("a\w+", "999", origin, 2) print(r)
6 split
# split,根据正则匹配分割字符串 split(pattern, string, maxsplit=0, flags=0) # pattern: 正则模型 # string : 要匹配的字符串 # maxsplit:指定分割个数 # flags : 匹配模式
origin = "hello alex bcd alex lge alex acd 19" r = re.split("alex", origin, 1) print(r) # 有分组 origin = "hello alex bcd alex lge alex acd 19" r1 = re.split("(alex)", origin, 1) print(r1) r2 = re.split("(al(ex))", origin, 1) print(r2)
序列化
Python中用于序列化的两个模块
- json 用于【字符串】和 【python基本数据类型】 间进行转换
- pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
json
import json data = {'k1': 123, 'k2': 456} s1 = json.dumps(data) print(s1) # s1 {"k1": 123, "k2": 456} 注意 json格式中括号是双引号 s2 = json.loads(s1) print(s2) # s2 {'k2': 456, 'k1': 123} 又变回那个字典 # load, dump 使用方法类似 loads,dumps只是进行了对文件的读写
pickle
import pickle data = {'k1': 123, 'k2': 456} s1 = pickle.dumps(data) print(s1) # s1 b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01K{X\x02\x00\x00\x00k2q\x02M\xc8\x01u.' 一种python自己认识的格式 s2 = pickle.loads(s1) print(s2) # s2 {'k2': 456, 'k1': 123} 又变回那个字典 # load, dump 使用方法类似 loads,dumps只是多了对文件的读写
反射
动态加载导入模块和加载模块中的类或函数
动态导入:__import__
os = __import__('os') #导入了os模块
path = __import__('os.path', fromlist=True) # 导入这中点分式的模块,需要将其中的一个参数fromlist设置为True,才能导入成功。
动态加载:getattr
例如:func = getattr('os','getcwd') ,导入了函数
hasattr 在加载前可以做判断,返回布尔值
hasattr('os','getcwd') 返回 True
setattr(模块,方法)
delattr(模块,方法)
以上方法都是在内存级别上操作的
上代码
代码中被导入模块是 commons, 执行的文件是index
# commons def login(): print('login') def logout(): print('logout') def home(): print('home')
index文件 import commons inp = input('请输入url:') m, f = inp.split('/') obj = __import__(m) if hasattr(obj, f): # func = getattr(commons, inp) func = getattr(obj, f) func() else: print('404')
其中一个执行例子 请输入url:commons/home home