一切都要从一只蝙蝠说起。。
因为疫情原因,这个月远程办公(摸鱼),看漫画花了1000多大洋,看着自己的支付宝余额,起了白嫖的邪念。。
网上有些漫画网站,点击下一页的时候,会跳出某些网站,十分不便,而且每次换页都需要点击,所以我决定把漫画全都爬下来,每章拼接成一张长图,可以看得舒服一些
工具:pycharm
工具包:scrapy,re,urllib,os
一.创建爬虫程序:
1.scrapy startproject manhua2
2.cd 到目录内
3.scrapy genspider manhua fzdm.com /漫画为spider名称 ,后面的为漫画网站网址
二.修改配置和建立启动文件
setting页面里面修改:
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'
}
启动文件:
from scrapy import cmdline
cmdline.execute("scrapy crawl manhua".split())
三.写spider
打开这个py文件
打开我想看的漫画地址,填入start_urls

我是从126话开始看的,所以初始地址为126
分析一下页面:

整页的漫画都是一个jpg,那就好办了,只要找到这个图片的src就行了,而且这个元素还有ID,很容易找
在打印的response.body里面,找到该元素

明显返回的数据和我们在页面自己看见的src不一样,既然不直接给,就自己拼接好了,由图可知,知道mhpicurl就能拼出src
所以我们要找出来mhpicurl的赋值在哪里,在结果里面搜索mhpicurl,找到赋值公式发现还要找到mhss和mhurl
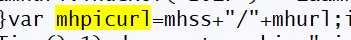
继续找mhss和mhurl
mhss:

mhurl:

所以自己拼接一下得到的就是http://p2.manhuapan.com/2014/12/071250072.jpg,也就是漫画图片的地址
后来我发现,我看的这本漫画的图片地址只有mhurl不一样,所以我只需要找到mhurl,就能得到图片的src
mhurl = re.findall('mhurl="(.*?).jpg"', str(response.body))[0]
img_scr = 'http://p2.manhuapan.com/' + mhurl + ".jpg"
找到这章漫画之后,我们需要获取下一话的信息
在不是最后一页的情况下:

在是最后一页的情况下;
也就是说,我们只需要获取div里面的最后一个a标签即可
next_page = response.css(".navigation a::attr(href)").extract()[-1]
然后就是下载图片链接了,这里我比较懒,直接用的
urllib.request.urlretrieve(图片链接, 图片位置)
下面是spider下的完整代码 (写的比较匆忙,有些地方不是很严谨)


# -*- coding: utf-8 -*- import scrapy import re import urllib.request import os class ManhuaSpider(scrapy.Spider): name = 'manhua' allowed_domains = ['fzdm.com'] start_urls = ['https://www.fzdm.com/manhua/42/126/index_0.html'] def parse(self, response): print(response.body) mhurl = re.findall('mhurl="(.*?).jpg"', str(response.body))[0] img_scr = 'http://p2.manhuapan.com/' + mhurl + ".jpg" print(img_scr) count=re.findall('https://www.fzdm.com/manhua/42/(.*?)/index_(.*?).html',response.url)[0] index=count[1] count=count[0] isExists = os.path.exists(r"C:Users tdrDesktop est\%s" % count) if not isExists: os.makedirs(r"C:Users tdrDesktop est\%s" % count) pic_name = r"C:Users tdrDesktop est\%s\%s.jpg" %(count,index) urllib.request.urlretrieve(img_scr, pic_name) next_page = response.css(".navigation a::attr(href)").extract()[-1] # next_page=re.findall('href="(.*?)"',str(next_page))[0] if next_page is not None: next_page = response.urljoin(next_page) if not str(next_page).endswith(".html"): print(next_page) next_page=next_page+'/index_0.html' yield scrapy.Request(next_page, callback=self.parse)
四.拼接图片
爬取完成之后,文件夹应该如下图所示
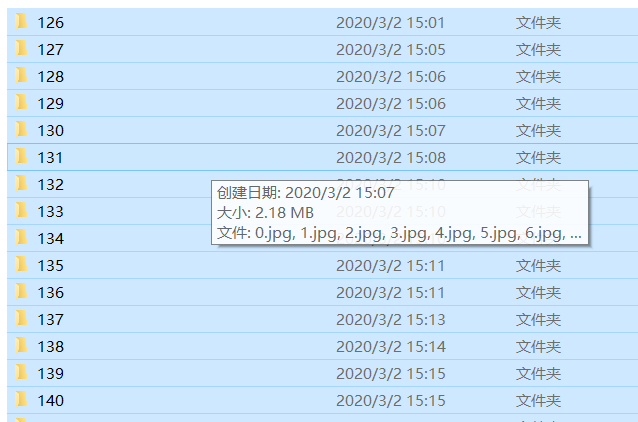
里面的图片应该为一张一张的小图片:
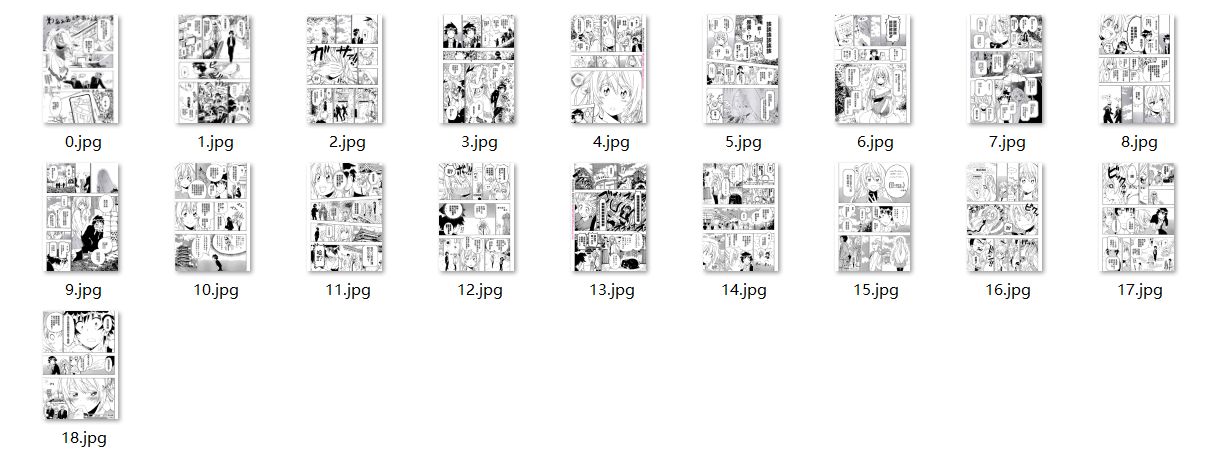
我们用PIL模块将图片拼接,这个过程很简单,我就直接放代码了:
import os import PIL.Image as Image for i in range(172,191): path=r'C:Users tdrDesktop est\%s' %i dirs=os.listdir(path) width=0 high=0 li=[0] for k in range(len(dirs)): pic_path = path + '\%s.jpg' % k fromImage = Image.open(pic_path) tem_w,tem_y=fromImage.size if tem_w> width=tem_w high+=tem_y li.append(high) toImage = Image.new('RGB', (width, high)) for k in range(len(dirs)): pic_path=path+'\%s.jpg' %k print(pic_path) fromImage = Image.open(pic_path) toImage.paste(fromImage,(0, li[k])) toImage.save(r'C:Users tdrDesktop est拼接后图片\%s.jpg' %i)
运行后效果如下:

然后我打包发到QQ看下效果

拼接正常,全程长图,右划下一章,完成。
ps:等我发工资会补票的,大家最好还是支持正版啊。。我做这个是出于技术o( ̄▽ ̄)d