模型评估与选择:
经验误差:实际预测输出和样本真实输出的差异,在训练集上的误差称为训练误差,经验误差,在新样本上的误差称为泛化误差。
拟合: 过拟合:训练样本学习的太好,泛化性能下降、欠拟合,训练样本尚未学好,繁华性能下降
评估方法:(从泛化误差进行评估,从而做出选择)
测试集、测试误差、泛化误差的近似,尽可能与训练集互斥
留出法、交叉验证法、自助法
调参与最终模型:
如书所说
性能度量:(错误率、精度、查准率、查全率、F1)
衡量模型泛化能力的评估标准:性能度量。把学习器预测结果和真实标记y进行比较。
回归任务:‘均方误差’
误率、精度、:
分类问题,错误率:分类错误的样本数占样本总数的比例。
精度:分类正确的样本数占样本总数的比例。
查准率P、查全率R、F1(基于查准率与查全率的调和平均):
TP、FP、TN、FN,混淆矩阵
P=TP/tp+fp R=TP/tp+fn
f1=2*p*r/p+r = 2*tp/阳历总数+tp-tn
一般形式 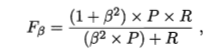
β>0时,说明查全率对查准率的相对重要性.=1时为标准的F1,>1时查全率有更大影响,<1时查准率有更大影响。
macro-P、macro-R、macro-F1 宏查准率,宏查全率,相应的宏F1,先在各混淆矩阵上分别计算查准率、查全率再计算平均值。
micro-P、micro-R、micro-F1。微查准率,微查全率,微F1,先计算平均TP,FP,TN,FN
ROC、AUC
ROC"受试者工作特征"
ROC曲线
AUC面积
代价敏感错误率与代价曲线
代价敏感错误率:权衡不同类型错误所造成的不同损失
比较检验:默认以错误率为性能度量
(此处补一个正态分布)
假设检验:
泛化错误率:模型在新样本上测试结果错误的率。
测试错误率约等于泛化错误率。
McNemar检验:
一个数据集上比较两个算法的性能
Friedman检验、Nemenyi后续检验
一组数据集上对多个算法进行比较,使用基于算法排序的Friedman检验。
偏差、方差
偏差度量学习算法的期望预测与真实结果的偏离程度,刻画学习算法本身的拟合能力;方差度量同样大小训练集的变动所导致学习性能的变化,刻画数据扰动所造成的影响。噪音是当前任务上任何学习算法所能达到的期望泛化误差的下界,刻画学习问题本身的难度。